
4. Sep 2017
Lesedauer 5 Min.
Wissensdatenbank Yago ist nun Open Source
Universität des Saarlandes
Yago ist eine der ersten Wissensbanken. Entwickelt wurde sie vom Max-Planck-Institut für Informatik in Saarbrücken und der Télécom ParisTech. Die Forscher veröffentlichen nun auch den Programmcode, sodass jeder die Wissensbank anpassen und erweitern kann.
„Wenn ich zum Beispiel nach dem Begriff Allianz suche, dann ist das für die jeweilige Suchmaschine nur eine Ansammlung von Buchstaben, ohne Bedeutung“, erklärt Professor Gerhard Weikum, wissenschaftlicher Direktor am Max-Planck-Institut für Informatik in Saarbrücken. „Mithilfe einer Wissensbank kann diese Buchstabenkette auf mögliche Bedeutungen abgebildet werden, zum Beispiel auf den Allianz-Versicherungskonzern oder die Rebellen-Allianz aus den Star-Wars-Filmen“. Dieses Hintergrundwissen ist heute bei Suchmaschinen nicht mehr wegzudenken, nur durch Wissensbanken kann beispielsweise Google neben den Ergebnissen der Websuche auch Börsenkurse, Logos und den Geschäftsführer der Allianz-Versicherung einblenden.
Die Wissensbanken begannen als akademische Forschungsprojekte. „Vor allem Yago und nur wenig später ‚DBpedia‘ haben in diesem Feld Pionierarbeit geleistet“, sagt Weikum. Das Yago-Projekt war 2007 Thema der Dissertation von Fabian Suchanek am Max-Planck-Institut für Informatik in Saarbrücken. Mehr und mehr Forscher beteiligten sich an dem Projekt. Heute ist Yago eine Zusammenarbeit des Max-Planck-Instituts und der Télécom ParisTech Universität, wo Suchanek inzwischen eine Professur innehat, sowie der Max-Planck-Ausgründung Ambiverse. Yago enthält das Wissen von Wikipedia und anderen Quellen in für den Computer lesbarer Form. So weiß das System beispielsweise, dass die Allianz ihren Hauptsitz in München hat, aber auch, dass die Rebellen-Allianz im Star-Wars-Universum kämpft.
Da momentan viele Programme in den unterschiedlichsten Industriezweigen mit Hilfe von Künstlicher Intelligenz effizienter und vor allem einfacher bedienbar gemacht werden sollen, ist Yago vielfältig im Einsatz. Anwendungen können mit Hilfe von Yago in mehreren Sprachen suchen oder Fakten sowohl räumlich als auch zeitlich einordnen. Suchanfragen wie „Nenne mir alle Wissenschaftler, die im 20. Jahrhundert gelebt haben und mit einem Nobelpreis ausgezeichnet wurden, sowie im weiteren Umkreis von Stuttgart geboren wurden!“ sind somit möglich. Ein Beispiel für die Nutzung liefert Primal.com, ein kanadisches Start-up, das andere Unternehmen mit Hilfe von Yago dabei unterstützt, die Interessen von individuellen Kunden zu verstehen, um somit Inhalte und Produkte besser vorschlagen zu können. Das prominenteste Beispiel der vergangenen zehn Jahre ist wohl, dass Yago von IBM als Bestandteil des Watson Systems verwendet wurde, welches 2011 die Quiz-Show „Jeopardy!“ gewann.
Einen weiteren Anwendungsfall liefert Ambiverse selbst. Vor wenigen Monaten analysierte das Spin-off des Max-Planck-Instituts die Panama Papers mittels Yago. Innerhalb weniger Stunden konnte Ambiverse so neue Erkenntnisse über die Inhaber der Panama-Konten gewinnen, die man manuell nur mit größtem Aufwand hätte finden können. Eine solche Analyse war nur möglich, weil Yago alle Personen in eine Struktur einordnet. Bis dato konnten Computer zwar Unmengen an Daten speichern, jedoch diese weder einordnen noch verstehen. Mit Yagos Struktur kann der Computer hingegen beispielsweise zwischen Gerd Müller, Fußballweltmeister aus dem Jahr 1974 und „Bomber der Nation“, und Gerd Müller, CSU-Entwicklungsminister, unterscheiden. „YAGO ordnet Personen das Umfeld zu, sodass ganz einfach festgestellt werden kann, ob nun mehr Sportler oder mehr Politiker Konten in Panama haben“, erläutert Johannes Hoffart, Geschäftsführer von Ambiverse. Solche Strukturen wurden ursprünglich per Hand erstellt. Dies ist jedoch sehr aufwendig – sowohl in puncto Produktion als auch Überprüfung.
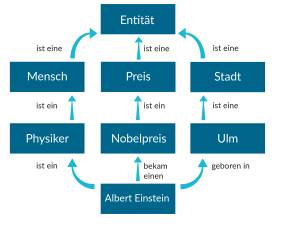
Für Yago haben die Forscher ein Verfahren entwickelt, das dieses Dilemma auf geschickte Art umgeht. Sie schürfen systematisch in der Wissensgrube Wikipedia. Nicht nur das Wissen, ob es sich um Sportler oder Politiker handelt, wird so in maschinenlesbare Form gebracht, sondern auch Beziehungen zwischen diesen. Die Informatiker bezeichnen diese als „Relationen“. So verbindet die Relation „hat Hauptsitz in“ die Entität „Allianz-Versicherung“ mit der Entität „Stadt München“. In Yago wird jeder Wikipedia-Artikel zu einer Entität der Wissensbank. Auf diese Weise schaffen es die Forscher, in Yago fast 17 Millionen Entitäten und 150 Millionen Beziehungen zwischen diesen abzuspeichern.
Unter anderem dafür wurden sie in der vergangenen Woche mit dem Prominent Paper Award des Artificial Intelligence Journal (AIJ), der wichtigsten wissenschaftlichen Zeitschrift für Künstliche Intelligenz, ausgezeichnet. Der Preis würdigt herausragende Publikationen der vergangenen sieben Jahre, die in ihrer Bedeutung und ihrem Einfluss außergewöhnlich sind. Die Wissenschaftler nahmen ihn in Melbourne entgegen, wo mit der IJCAI die bedeutendste wissenschaftliche Konferenz im Bereich Künstliche Intelligenz stattgefunden hat.
Inzwischen haben die Forscher den Quellcode ihrer Wissensdatenbank auf der Plattform GitHub unter der Open Source Lizenz GNU GPL v3 veröffentlicht. Diese Softwarelizenz stellt sicher, dass jeder den damit geschützten Programmcode ausführen, studieren, verändern und teilen darf. „Mit Yago bekommt die Entwickler-Gemeinde eine Wissensbank von hoher Qualität“, erklärt Professor Fabian Suchanek, Gründer des Projekts. „Von der Veröffentlichung erhoffen wir uns nicht nur weitere Anwendungen von Yago, sondern auch Beiträge von der Entwickler-Gemeinde”. Den zugehörigen Quellcode kann sich nun jedermann unter dem folgenden Link herunterladen: https://github.com/yago-naga/yago3
Die Wissensbanken begannen als akademische Forschungsprojekte. „Vor allem Yago und nur wenig später ‚DBpedia‘ haben in diesem Feld Pionierarbeit geleistet“, sagt Weikum. Das Yago-Projekt war 2007 Thema der Dissertation von Fabian Suchanek am Max-Planck-Institut für Informatik in Saarbrücken. Mehr und mehr Forscher beteiligten sich an dem Projekt. Heute ist Yago eine Zusammenarbeit des Max-Planck-Instituts und der Télécom ParisTech Universität, wo Suchanek inzwischen eine Professur innehat, sowie der Max-Planck-Ausgründung Ambiverse. Yago enthält das Wissen von Wikipedia und anderen Quellen in für den Computer lesbarer Form. So weiß das System beispielsweise, dass die Allianz ihren Hauptsitz in München hat, aber auch, dass die Rebellen-Allianz im Star-Wars-Universum kämpft.
Da momentan viele Programme in den unterschiedlichsten Industriezweigen mit Hilfe von Künstlicher Intelligenz effizienter und vor allem einfacher bedienbar gemacht werden sollen, ist Yago vielfältig im Einsatz. Anwendungen können mit Hilfe von Yago in mehreren Sprachen suchen oder Fakten sowohl räumlich als auch zeitlich einordnen. Suchanfragen wie „Nenne mir alle Wissenschaftler, die im 20. Jahrhundert gelebt haben und mit einem Nobelpreis ausgezeichnet wurden, sowie im weiteren Umkreis von Stuttgart geboren wurden!“ sind somit möglich. Ein Beispiel für die Nutzung liefert Primal.com, ein kanadisches Start-up, das andere Unternehmen mit Hilfe von Yago dabei unterstützt, die Interessen von individuellen Kunden zu verstehen, um somit Inhalte und Produkte besser vorschlagen zu können. Das prominenteste Beispiel der vergangenen zehn Jahre ist wohl, dass Yago von IBM als Bestandteil des Watson Systems verwendet wurde, welches 2011 die Quiz-Show „Jeopardy!“ gewann.
Einen weiteren Anwendungsfall liefert Ambiverse selbst. Vor wenigen Monaten analysierte das Spin-off des Max-Planck-Instituts die Panama Papers mittels Yago. Innerhalb weniger Stunden konnte Ambiverse so neue Erkenntnisse über die Inhaber der Panama-Konten gewinnen, die man manuell nur mit größtem Aufwand hätte finden können. Eine solche Analyse war nur möglich, weil Yago alle Personen in eine Struktur einordnet. Bis dato konnten Computer zwar Unmengen an Daten speichern, jedoch diese weder einordnen noch verstehen. Mit Yagos Struktur kann der Computer hingegen beispielsweise zwischen Gerd Müller, Fußballweltmeister aus dem Jahr 1974 und „Bomber der Nation“, und Gerd Müller, CSU-Entwicklungsminister, unterscheiden. „YAGO ordnet Personen das Umfeld zu, sodass ganz einfach festgestellt werden kann, ob nun mehr Sportler oder mehr Politiker Konten in Panama haben“, erläutert Johannes Hoffart, Geschäftsführer von Ambiverse. Solche Strukturen wurden ursprünglich per Hand erstellt. Dies ist jedoch sehr aufwendig – sowohl in puncto Produktion als auch Überprüfung.
Für Yago haben die Forscher ein Verfahren entwickelt, das dieses Dilemma auf geschickte Art umgeht. Sie schürfen systematisch in der Wissensgrube Wikipedia. Nicht nur das Wissen, ob es sich um Sportler oder Politiker handelt, wird so in maschinenlesbare Form gebracht, sondern auch Beziehungen zwischen diesen. Die Informatiker bezeichnen diese als „Relationen“. So verbindet die Relation „hat Hauptsitz in“ die Entität „Allianz-Versicherung“ mit der Entität „Stadt München“. In Yago wird jeder Wikipedia-Artikel zu einer Entität der Wissensbank. Auf diese Weise schaffen es die Forscher, in Yago fast 17 Millionen Entitäten und 150 Millionen Beziehungen zwischen diesen abzuspeichern.
Unter anderem dafür wurden sie in der vergangenen Woche mit dem Prominent Paper Award des Artificial Intelligence Journal (AIJ), der wichtigsten wissenschaftlichen Zeitschrift für Künstliche Intelligenz, ausgezeichnet. Der Preis würdigt herausragende Publikationen der vergangenen sieben Jahre, die in ihrer Bedeutung und ihrem Einfluss außergewöhnlich sind. Die Wissenschaftler nahmen ihn in Melbourne entgegen, wo mit der IJCAI die bedeutendste wissenschaftliche Konferenz im Bereich Künstliche Intelligenz stattgefunden hat.
Inzwischen haben die Forscher den Quellcode ihrer Wissensdatenbank auf der Plattform GitHub unter der Open Source Lizenz GNU GPL v3 veröffentlicht. Diese Softwarelizenz stellt sicher, dass jeder den damit geschützten Programmcode ausführen, studieren, verändern und teilen darf. „Mit Yago bekommt die Entwickler-Gemeinde eine Wissensbank von hoher Qualität“, erklärt Professor Fabian Suchanek, Gründer des Projekts. „Von der Veröffentlichung erhoffen wir uns nicht nur weitere Anwendungen von Yago, sondern auch Beiträge von der Entwickler-Gemeinde”. Den zugehörigen Quellcode kann sich nun jedermann unter dem folgenden Link herunterladen: https://github.com/yago-naga/yago3











