
18. Nov 2024
Lesedauer 16 Min.
Asynchron
Rust-Kurs, Teil 8
Cooperative Scheduling in Rust-Anwendungen realisieren.

Rust ist eine neuartige, moderne Programmiersprache, die sich auf die Sicherheit, der Geschwindigkeit und auf die effiziente, fehlerfreie parallele Programmierung konzentriert. In dieser Artikelserie geht es um den Einstieg in Rust und nebenbei gelegentlich um einen Vergleich mit C/C++ sowie C#. Die zurückliegende Folge [1] hat sich näher mit Multi-Threading, Channels und parallelen Iteratoren beschäftigt. Die heutige Folge erklärt, wie Sie die asynchrone Programmierung in Rust realisieren können, mit der Sie in einer anderen Art und Weise mehrere Code-Pfade parallel ausführen können. Zunächst werden ein paar wichtige Begriffe vorgestellt.
Parallelism, Concurrency, Preemptive- und Cooperative Scheduling
Die beiden Begriffe Parallelism und Concurrency werden sehr oft synonym verwendet, obwohl es sich um unterschiedliche Konzepte handelt. Parallelism bedeutet, dass mehrere Tasks ihre Arbeit parallel zueinander verrichten. Die vorangegangene Folge hat hierzu das Konzept des Multi-Threading vorgestellt, mit dem das Parallelisieren von Threads auf einem Multi-Core-System einfach realisiert werden kann.Concurrency bedeutet auch, dass mehrere Tasks ausgeführt werden, die aber zeitlich zueinander versetzt ablaufen können. Bild 1 veranschaulicht diesen wichtigen Unterschied.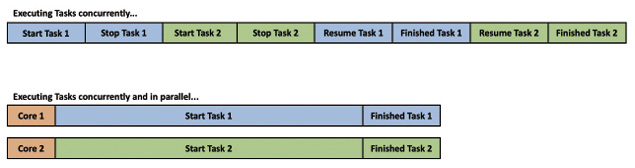
Concurrency versus Paralellism (Bild 1)
Autor
Um eine Concurrency von Tasks erreichen zu können, müssen Sie in der Lage sein, Tasks zu stoppen und ihren aktuellen Status zu speichern, damit Sie den Task zu einem späteren Zeitpunkt fortführen können.Das Betriebssystem stellt spezielle Multitasking-Funktionalitäten zur Verfügung, mit deren Hilfe Parallelism und Concurrency von Code-Pfaden realisiert werden können. Programmiersprachen wie Rust setzen auf diese Funktionalitäten auf. Multitasking kann hierbei auf zwei unterschiedliche Arten durchgeführt werden: per Cooperative Scheduling oder Preemptive Scheduling.Beim Preemptive Scheduling führt das Betriebssystem in regelmäßigen Abständen (unter Windows etwa alle vier Millisekunden) sogenannte Kontext-Switches durch. Dabei wird der Status des aktuellen Threads – also alle aktuellen Registerinhalte – in einer Datenstruktur gesichert und anschließend der Status eines anderen Threads in die Register geladen, damit dieser weiter ausgeführt werden kann. Da hierfür sehr viele Assembly-Instruktionen benötigt werden, ist ein Kontext-Switch sehr zeitintensiv und kann unter Umständen zu Skalierungsproblemen führen.Stellen Sie sich beispielsweise bei einem Datenbank-Server vor, dass für jede eingehende Abfrage ein neuer Thread gestartet wird. Bei Tausenden von gleichzeitig ablaufenden Abfragen müsste das Betriebssystem ein Kontext-Switching für Tausende Threads durchführen. Es ist leicht ersichtlich, dass davon die Performance kaum profitieren kann.Jeder Thread besteht zusätzlich aus verschiedenen Stack-Frames, welche die verwendeten lokalen Variablen speichern und den aktuellen Callstack umfassen. Stack-Frames behält das Betriebssystems im Hauptspeicher und generiert somit zusätzlichen Overhead. Beispiel Windows: Hier hat ein Stack-Frame für einen Thread eine initiale Größe von einem Megabyte. Trotz dieser Nachteile ist das Preemptive Scheduling die Multitasking-Variante, die moderne Betriebssysteme aktuell einsetzen.Neben dem Preemptive Scheduling gibt es aber noch das Cooperative Scheduling, bei dem das Scheduling primär von den Anwendungen selbst realisiert wird. Das heißt, dass eine Anwendung einen Code-Pfad für eine bestimmte Zeitdauer ausführt und nach Ablauf der Zeitdauer die CPU von sich aus freigibt, damit ein anderer Code-Pfad ausgeführt werden kann. Das Freigeben der CPU wird als CPU-Yielding bezeichnet.Da in diesem Verfahren keine Kontext-Switches seitens des Betriebssystems durchgeführt werden müssen, ist das Cooperative Scheduling um einiges schneller als das Preemptive Scheduling. Das Problem ist jedoch, dass Anwendungen selbst für das Freigeben der CPU verantwortlich sind. Dadurch kann ein einfacher Programmierfehler (das fehlende regelmäßige CPU-Yielding) das komplette Betriebssystem zum Absturz bringen. Diese Variante des Schedulings hat Microsoft unter Windows 3.1 eingesetzt – also vor einer sehr langen Zeit.Nebenbei sei noch ein weiteres Beispiel erwähnt: Der SQL Server implementiert intern ebenfalls ein Cooperative Scheduling zum Ausführen von Datenbank-Abfragen. Der SQL Server umgeht dabei das Preemptive Scheduling des Betriebssystems und führt seine Worker-Threads selbstständig aus. Daraus folgt auch, dass die Code-Pfade innerhalb des SQL Servers eigenständig dafür Sorge tragen müssen, dass die CPU in regelmäßigen Intervallen freigegeben wird. Jedes Mal, wenn ein CPU-Yielding innerhalb der Implementierung des SQL Servers durchgeführt wird, wird für die betreffende Abfrage der Wartetyp SOS_SCHEDULER_YIELD zurückgeliefert, die Abfrage wird in den Status RUNNABLE verschoben und wartet dann auf freie CPU-Zeit. In solchen und ähnlichen Fällen ist das Cooperative Scheduling durchaus sinnvoll.Als Daumenregel kann gesagt werden, dass Preemptive Scheduling immer dann die richtige Wahl ist, wenn CPU-intensive Arbeiten durchzuführen sind. Dazu können Sie Threads nutzen, deren Verwendung Sie bereits in der vorangegangenen Folge dieser Serie kennengelernt haben.Besteht Ihr Code jedoch aus Funktionsaufrufen, die zu Blockaden führen können (weil die Code-Ausführung gestoppt werden muss, bis der Funktionsaufruf seitens des Betriebssystems vollständig durchgeführt wurde), ist der Einsatz von Cooperative Scheduling sinnvoller. Dazu zählen unter anderem:
- Netzwerkzugriffe,
- Datenbankzugriffe,
- Internetzugriffe,
- Interaktion mit dem Storage-Subsystem,
- Warten bis ein Timer abgelaufen ist.
Asynchrone Rust Runtimes
Das asynchrone Programmiermodell von Rust ist nichts Neues oder Außergewöhnliches. Vergleichbar mit den Funktionalitäten in Rust sind beispielsweise die von JavaScript angebotenen Promises [2] oder das Task Asynchronous Programming Model (TAP) von .NET [3].Eine Besonderheit der asynchronen Programmierung in Rust ist die Tatsache, dass Rust nur die notwendige Infrastruktur zur Verfügung stellt. Hierbei handelt es sich um die Trait Future [4] und die beiden Schlüsselwörter async und await, die Bestandteil des Rust-Compilers rustc sind.Eine asynchrone Runtime gehört jedoch nicht zu den Bestandteilen eines klassischen Rust-Programms. Sie müssen sie deshalb explizit über eine passende Crate in Ihrem Programm referenzieren (über die Datei cargo.toml). Durch diesen Ansatz wird sichergestellt, dass Rust-Binaries sehr klein bleiben, da eine asynchrone Runtime nur dann mitkompiliert wird, wenn die Anwendung sie auch benötigt.Tabelle 1 gibt einen Überblick über die bekanntesten asynchronen Runtimes für Rust, die immer wieder in unterschiedlichen Projekten eingesetzt werden.Tabelle 1: Asynchrone Runtimes für Rust
Alle Beispiele in diesem Artikel basieren auf der Runtime async-std, da diese für die ersten Schritte leicht verständlich und programmiertechnisch an die synchrone Standard-Library von Rust angelehnt ist. Für ernsthafte Rust-Projekte ist jedoch die Tokio-Runtime zu empfehlen, da diese aktiv von der Rust-Community weiterentwickelt wird und für sie laufend neue Releases bereitgestellt werden.Abhängig von der gewählten Runtime und deren Konfiguration kann diese asynchronen Code mit nur einem Worker-Thread (Single-Threaded) oder mehreren Worker-Threads (Multi-Threaded) ausführen. Im Hintergrund nutzt die Runtime dafür einen Thread-Pool, dessen Größe man ebenfalls anpassen kann.
Asynchrone Programmierung mit Rust
Als Beispiel für die asynchrone Programmierung in Rust dient hier die Ausführung von Abfragen auf einem SQL Server.Zum besseren Verständnis wird in Listing 1 zunächst exemplarischer Code gezeigt, der sich zwar nicht kompilieren lässt, aber demonstriert, wie der Zugriff auf den SQL Server mit normalen synchronen Funktionen funktionieren würde und wo die Performance-Probleme versteckt sind. Wie Sie im Listing erkennen können, interagiert dieser Code an drei Stellen mit dem SQL Server:Listing 1: Synchroner Zugriff auf den SQL Server
// Exemplarisch. Der Code lässt sich nicht
// kompilieren!
fn main()
{
// 1. Connect to SQL Server.
let sql_client =
SQLClient::connect(connectionString);
// 2. Execute a simple SELECT query.
let select_query = Query::new(sql_statement);
let mut data_stream =
select_query.query(&client);
// 3. Retrieve and process each row...
while (let Some(row) = data_stream.try_next()
{
println!("{:?}", row);
}
} - Im ersten Schritt wird eine neue Datenbankverbindung zum SQL Server aufgebaut.
- Im nächsten Schritt wird eine SELECT-Abfrage zum SQL Server gesendet.
- Danach werden die zurückgelieferten Datensätze in der Anwendung verarbeitet.
Listing 2: Die Datei cargo.toml
[package]
name = "sqlserver_async"
version = "0.1.0"
edition = "2021"
[dependencies]
async-std =
{
version = "1.12.0",
features = ["attributes"]
}
anyhow = "1.0.0"
futures-util = "0.3"
# Windows
[target.'cfg(
target_os = "windows")'.dependencies]
tiberius =
{
version="0.12.2",
features = ["chrono", "time"]
}
# Mac OS
[target.'cfg(
target_os = "macos")'.dependencies]
tiberius =
{
version="0.12.2",
default-features = false,
features = ["chrono", "time",
"vendored-openssl"]
} Listing 3: Asynchroner Zugriff
async fn execute_query(sql_statement: String,
duration: u64) -> anyhow::Result<()>
{
// Create a new connection string.
let config = Config::from_ado_string(
CONNECTION_STRING)?;
// Create a new TcpStream to the
// SQL Server endpoint.
println!("Connecting to SQL Server...");
let socket = TcpStream::connect(
config.get_addr()).await?;
socket.set_nodelay(true)?;
// Connect to SQL Server.
let mut client = Client::connect(
config, socket).await?;
println!("Successfully connected to
SQL Server.");
// Execute a simple query against SQL Server.
let select_query = Query::new(
&sql_statement);
let mut data_stream = select_query.query(
&mut client).await?;
// Loop over the received data.
while let Some(row) =
data_stream.try_next().await?
{
match row
{
QueryItem::Metadata(meta) =>
{
println!("{:?}", meta);
println!("");
},
QueryItem::Row(row) =>
{
println!("{:?}", row);
println!("");
}
}
}
Ok(())
}
Die Funktion execute_query() wurde mit dem Schlüsselwort async definiert, wodurch Sie dem Rust-Compiler mitteilen, dass diese Funktion asynchron über Cooperative Scheduling ausgeführt werden soll. Jedes Mal, wenn Sie eine asynchrone Funktion aufrufen, die zu einer Blockade im Betriebssystem führt, wechselt die asynchrone Runtime über Cooperative Scheduling zu einem anderen Code-Pfad (der zuvor durch einen Funktionsaufruf blockiert war) und führt diesen weiter aus. Dabei handelt es sich um die zuvor angesprochene Technik des CPU-Yieldings. Wichtig zu wissen ist, dass hier das Betriebssystem nicht involviert ist, da das Cooperative Scheduling vollständig im User-Mode erfolgt. Die Frage, die sich nun stellt, ist, an welchen Punkten das CPU-Yielding durchgeführt werden soll. Dazu definiert die Programmiersprache Rust das Schlüsselwort await.Dieses Schlüsselwort können Sie beim Aufruf einer asynchronen Funktion angeben, wodurch seitens der verwendeten asynchronen Runtime das CPU-Yielding durchgeführt wird, wenn der Funktionsaufruf blockiert.In Listing 3 werden die folgenden CPU-Yielding-Points über das Schlüsselwort await definiert:
- TcpStream::connect(…).await?
- Client::connect(…).await?
- select_query.query(…).await?
- data_stream.try_next().await?
Futures
Jetzt geht es darum, wie man eine asynchrone Funktion in Rust aufrufen und verwenden kann. Der hier zuerst abgedruckte, logischste Ansatz – nämlich der direkte Aufruf der asynchronen Funktion – führt leider noch nicht zum gewünschten Ergebnis:
fn main()
{
execute_query(
"SELECT @@VERSION".to_string(), 0);
println!("Done!");
}
Rufen Sie die asynchrone Funktion über einen normalen Funktionsaufruf, passiert einfach gar nichts, wie Sie in Bild 2 sehen können. Lediglich das Makro println! der Funktion main() wird ausgeführt, der Code innerhalb der Funktion execute_query() allerdings nicht. Im Bild hervorgehoben ist, dass der Rust-Compiler eine Warnung generiert hat, die besagt, dass eine sogenannte Future nichts durchführt, solange das Schlüsselwort await fehlt oder die Funktion poll() ausgeführt wird. Was genau ist nun aber eine Future, und was bedeutet diese Warnung?
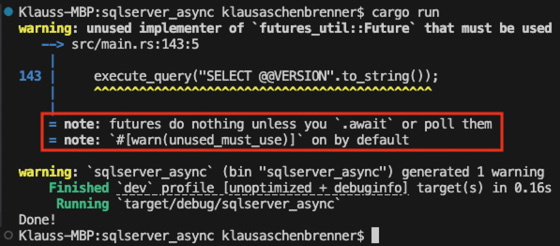
Futures tun zunächst einmal nichts (Bild 2)
Autor
Eine Future in Rust ist nichts anderes als eine Datenstruktur, welche die Trait Future [3] implementiert, die zur Standard Library von Rust gehört. Die Definition dieser Trait ist einfach gehalten, da nur ein Output-Typ und die Funktion poll() definiert wird. Hier die Definition dieser Trait:
pub trait Future
{
type Output;
// Required method
fn poll(
self: Pin<&mut Self>,
cx: &mut Context<'_>) ->
Poll<Self::Output>;
}
Wie Sie erkennen können, hat die Funktion poll() der Trait Future eine veränderliche Referenz auf sich selbst (Parameter self) und eine veränderliche Referenz auf einen sogenannten Context (Parameter cx).Interessant ist hierbei der Parameter self, da dieser in eine Datenstruktur vom Typ Pin<T> eingebettet ist. In Rust müssen Futures immer gepinnt werden, das heißt, dass diese im Hauptspeicher nicht verschoben werden dürfen. Diese Vorgehensweise ist notwendig, da Futures sogenannte Self-Referential Structures [6] sind, also Verweise auf sich selbst beinhalten.Würde der Speicherort einer Future im Hauptspeicher verändert, würden diese Verweise ungültig. Durch Verwenden des Datentyps Pin<T> ist sichergestellt, dass der Speicherort einer Future nicht geändert werden kann, und somit bleiben auch die Verweise innerhalb der Future intakt.Rufen Sie nun eine asynchrone Funktion auf, generiert der Rust-Compiler eine Datenstruktur, die diese Trait implementiert, und liefert sie als Funktionsergebnis zurück. Innerhalb der Funktion poll() ist die Funktion enthalten, die Sie zuvor in der asynchronen Funktion implementiert haben.Der Rust-Compiler führt eine Code-Transformation der asynchronen Funktion in eine Future durch. Darum wird beim Funktionsaufruf auch die eigentliche Funktionsimplementierung nicht ausgeführt, da nur die Future-Datenstruktur generiert wird.Damit nun die asynchrone Funktion ausgeführt werden kann, müssen Sie die zurückgelieferte Future-Datenstruktur an einen sogenannten Executor übergeben, der in regelmäßigen Intervallen die Funktion poll() aufruft und so die Future Schritt für Schritt abarbeitet.Die Executor-Komponente ist Bestandteil der asynchronen Runtime, die in der Rust-Anwendung referenziert wurde – im Beispiel ist sie also Bestandteil der Runtime async-std.Listing 4 zeigt nun, wie Sie die Future über die Funktion task::block_on() der asynchronen Runtime ausführen. Das Ergebnis dieser Ausführung zeigt Bild 3.
Listing 4: Eine Future ausführen
fn execute_single_query()
{
// The current thread will be blocked until
// the future is resolved.
let response1 = task::block_on(
execute_query(
"SELECT TOP 10
BusinessEntityID, FirstName, LastName,
ModifiedDate FROM
Person.Person".to_string(), 0));
println!("{:?}", response1);
// The current thread will be blocked until
// the future is resolved
let response2 = task::block_on(
execute_query(
"SELECT @@VERSION".to_string(), 0));
println!("{:?}", response2);
} 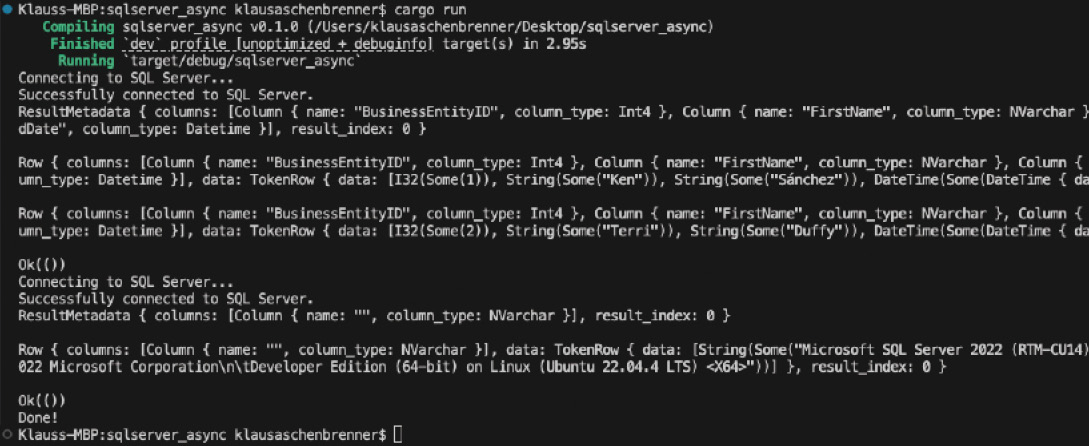
Die asynchrone Funktion wurde erfolgreich ausgeführt (Bild 3)
Autor
Wie Sie sehen, wird nun das Ergebnis der SQL-Abfrage
auf der Konsole ausgegeben – die asynchrone Funktion, beziehungsweise die Future, in die die asynchrone Funktion transformiert wurde, ist korrekt ausgeführt worden.Ein Problem, das sich in Listing 4 versteckt hat, ist die Tatsache, dass die beiden SQL-Statements seriell, also der Reihe nach ausgeführt werden. Die Funktion task::block_on() blockiert nämlich den aktuellen Thread so lange, bis die übergebene Future vollständig abgearbeitet wurde.Daraus folgt, dass das zweite SQL-Statement erst dann ausgeführt werden kann, wenn das erste Statement beendet wurde. Daher wird später noch besprochen, wie Sie mehrere Futures parallel abarbeiten können.
auf der Konsole ausgegeben – die asynchrone Funktion, beziehungsweise die Future, in die die asynchrone Funktion transformiert wurde, ist korrekt ausgeführt worden.Ein Problem, das sich in Listing 4 versteckt hat, ist die Tatsache, dass die beiden SQL-Statements seriell, also der Reihe nach ausgeführt werden. Die Funktion task::block_on() blockiert nämlich den aktuellen Thread so lange, bis die übergebene Future vollständig abgearbeitet wurde.Daraus folgt, dass das zweite SQL-Statement erst dann ausgeführt werden kann, wenn das erste Statement beendet wurde. Daher wird später noch besprochen, wie Sie mehrere Futures parallel abarbeiten können.
Futures als State Machines
Im vorangegangenen Abschnitt haben Sie gelernt, dass der Rust-Compiler aus einer asynchronen Funktion eine Future erzeugt, welche die Trait Future aus der Standard-Library implementiert. Und zum Ausführen einer Future benötigen Sie einen Executor, der Bestandteil der gewählten asynchronen Runtime ist.Was genau ist nun aber eine Future, und wie kann ein Executor eine solche Future ausführen? Die zurückgelieferte Datenstruktur, welche die Trait Future implementiert, ist nichts anderes als eine State Machine, die aus mehreren unterschiedlichen Status besteht.Wie Sie zuvor in Listing 3 gesehen haben, wurde beim Aufruf einer asynchronen Funktion das Schlüsselwort await verwendet. Bei jeder Verwendung dieses Schlüsselworts handelt es sich einerseits um einen CPU-Yielding-Point und anderseits um einen Status innerhalb der State Machine, der in der zurückgelieferten Future durch den Rust-Compiler generiert wird. Die folgenden Code-Zeilen zeigen exemplarisch, welche Stati für die asynchrone Funktion aus Listing 3 durch den Rust Compiler generiert werden.
enum State
{
Unpolled,
State0, // TcpStream::connect()
State1, // Client::connect()
State2, // select_query.query()
State3 // data_stream.try_next()
Resolved
}
Wie Sie erkennen können, startet eine Future immer im Status Unpolled. Bei jeder Verwendung des Schlüsselworts await wird ein weiterer Status zur State Machine hinzugefügt, und wenn die asynchrone Funktion vollständig abgearbeitet wurde endet jede State Machine im Status Resolved.Um nun von einem Status in den nächsten Status wechseln zu können, muss die Executor-Komponente auf der Future-Datenstruktur die Funktion poll() aufrufen (die Bestandteil der Trait Future ist). Diese führt dann eine entsprechende State Transition durch und wechselt vom aktuellen in den nächsten Status. Dies geschieht immer dann, wenn in der Code-Ausführung ein Punkt erreicht wird, an dem das Schlüsselwort await verwendet wurde.Da diese Code-Punkte jedoch einen asynchronen Funktionsaufruf beinhalten, wird mit höchster Wahrscheinlichkeit der Funktionsaufruf noch nicht vollständig abgearbeitet sein, wodurch der generierte Code ein CPU-Yielding durchführt, wodurch auf dem gleichen Thread ein anderer Code-Pfad zur Ausführung kommt.Sobald der ursprüngliche asynchrone Funktionsaufruf seine Arbeit erledigt hat, wird dies der asynchronen Runtime über eine sogenannte Waker-Komponente mitgeteilt, wodurch bei einer der nächsten CPU-Yielding-Operationen der ursprüngliche Task weiter ausgeführt wird – und zwar genau an der Stelle, wo er zuvor angehalten wurde.Das ist die Grundidee des Cooperative Scheduling, da hier seitens des Betriebssystems kein Kontext-Switching erforderlich ist.Sämtliche Scheduling-Operationen finden direkt im User-Mode statt, ohne das hier Funktionalitäten aufgerufen werden müssen, die im Kernel-Mode des Betriebssystems ablaufen. Dadurch ist das Konzept des Cooperative Scheduling für blockierende Funktionsaufrufe um einiges besser geeignet als das Konzept des Preemptive Scheduling. Bild 4 zeigt einen Ausschnitt aus dem Code, den der Rust-Compiler für asynchrone Funktionen generiert. Diesen sogenannten HIR Code (High Level Intermediate Representation Code) können Sie sich über folgenden Kommandozeilenbefehl ausgeben lassen:
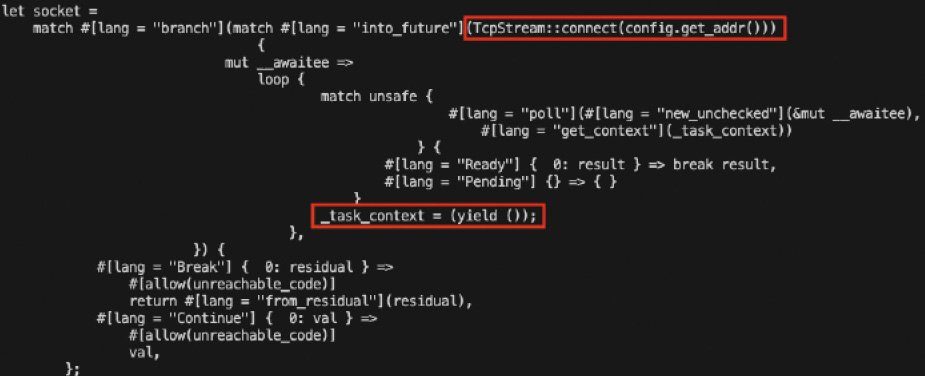
Ausschnitt des Codes, den der Rust-Compiler für asynchrone Funktionen generiert (Bild 4)
Autor
cargo rustc -- -Z unpretty=hir
Wichtig ist dabei, dass Sie eine Nightly-Build-Version von Rust einsetzen, da ein normaler Release-Build diesen Befehl nicht unterstützt. Installieren lässt sich eine solche Version mithilfe des folgenden Kommandozeilenbefehls:
rustup default nightly
Möchten Sie zur normalen Release-Build zurückwechseln, verwenden Sie den folgenden Kommandozeilenbefehl:
rustup default stable Parallel ausgeführte Futures
In Listing 4 haben Sie gesehen, wie Sie asynchrone Funktionen über die Funktion task::block_on() aufrufen. Übergeben Sie dieser Funktion jedoch nur eine Future zur Ausführung, wird der aktuelle Thread so lange blockiert, bis diese Future ihre Code-Ausführung beendet hat. Damit erreichen Sie aber keine richtige Parallelisierung, da bei einem CPU-Yielding-Point keine anderen Code-Pfade zur Ausführung zur Verfügung stehen.Daher bietet Ihnen die asynchrone Runtime async-std die Funktion task::spawn() an, mit der Sie eine asynchrone Funktion asynchron im Hintergrund ausführen können, ohne dass der aktuelle Thread blockiert wird. Durch diese Vorgehensweise erreichen Sie, dass Futures parallel ausgeführt werden. Listing 5 zeigt ein einfaches Beispiel.Listing 5: Mehrere Futures ausführen
fn execute_multiple_queries_concurrently()
{
let mut queries = vec![];
queries.push(
"SELECT TOP 10 BusinessEntityID,
FirstName, LastName, ModifiedDate FROM
Person.Person".to_string());
queries.push("SELECT @@VERSION".to_string());
queries.push("SELECT COUNT(*) FROM
Person.Person".to_string());
queries.push("SELECT TOP 10 AddressID,
AddressLine1, PostalCode FROM
Person.Address".to_string());
// The current thread will be blocked until
// the top future is resolved.
let response = task::block_on(
many_select_queries(queries));
println!("{:?}", response);
}
async fn many_select_queries(queries: Vec<String>)
{
let mut duration: u64 = queries.len() as u64 + 1;
let mut handles = vec![];
for query in queries
{
// Runs the new task asynchronously
// in the background.
// Other code can run concurrently...
handles.push(task::spawn(
execute_query(query.to_string(), duration)));
};
// Wait until all futures are resolved.
for handle in handles
{
let _ = handle.await;
}
}
Im Code werden innerhalb der Funktion execute_multiple_queries_concurrently() die verschiedenen Abfragen zusammengefasst, die anschließend über die Funktion many_select_queries() asynchron aufgerufen werden. Hierbei wird der Thread über die Funktion task::block_on() so lange blockiert, bis alle Abfragen beendet wurden. Daraus folgt, dass es sich bei der Funktion many_select_queries() wiederum um eine asynchrone Funktion handelt, die als Ergebnis eine Future zurückliefert.Innerhalb der Implementierung dieser Funktion wird nun für jede übergebene Abfrage die Funktion task::spawn() aufgerufen, die als Ergebnis eine Variable vom Typ JoinHandle zurückliefert. Auf dieser Variablen wird anschließend in einer Schleife wiederum die Funktion await aufgerufen, welche die internen State Machines der Futures von einem Status in den nächsten Status bewegt und somit die asynchronen Funktionen Schritt für Schritt abarbeitet. Bild 5 zeigt die Ergebnisse der verschiedenen Abfragen. Wenn Sie genau hinsehen, erkennen Sie, dass die Datensätze der einzelnen Abfragen auf der Konsole in einer anderen Reihenfolge ausgegeben werden, da sie nun parallelisiert über das Cooperative Scheduling ausgeführt wurden.
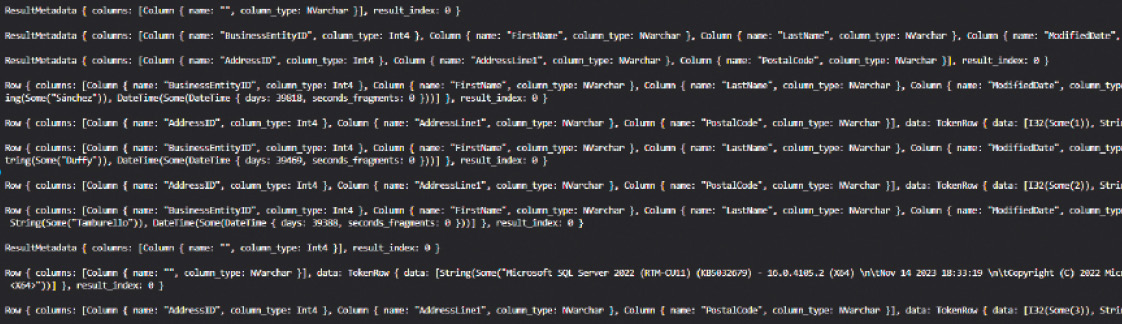
Ergebnisse der parallelen SQL-Abfragen (Bild 5)
Autor
Synchroner Code in Futures
Eine weitere Besonderheit von asynchronen Funktionen in Rust ist, wie Sie in diesen Funktionen synchrone Funktionsaufrufe durchführen sollten. Wenn Sie eine synchrone Funktion ganz normal aufrufen, blockiert der aktuelle Thread so lange, bis der synchrone Funktionsaufruf vollständig durchgeführt wurde.Daraus folgt aber auch, dass kein Cooperative Scheduling seitens des Executors durchgeführt werden kann, da bis zur Fertigstellung des synchronen Funktionsaufrufs kein CPU-Yielding-Point innerhalb der asynchronen Funktion erreicht werden kann. Dadurch wird auch die Executor-Komponente der asynchronen Runtime blockiert. Daraus ergeben sich dann entsprechende Performanceprobleme.Listing 6 illustriert dieses Problem innerhalb der Funktion execute_query() durch den expliziten Aufruf der synchronen Funktion std::thread::sleep(), die den aktuellen Thread für die angegebene Zeit pausiert.Listing 6: Synchrone Funktionsaufrufe 1/2
// Loop over the received data.
while let Some(row) =
data_stream.try_next().await?
{
match row
{
QueryItem::Metadata(meta) =>
{
println!("{:?}", meta);
println!("");
},
QueryItem::Row(row) =>
{
println!("{:?}", row);
println!("");
// This call blocks the executor of the
// runtime, because there is no .await!
println!("Long running CPU intensive task...");
std::thread::sleep(
core::time::Duration::from_secs(duration));
}
}
}
Rufen Sie diesen Code mit std::thread:sleep() auf, werden Sie feststellen, dass die Ausführung um einiges länger dauert, da nach jedem zurückgelieferten Datensatz der aktuelle Thread für einige Sekunden angehalten wird – wie lange, ist abhängig vom übergebenen Parameter duration. Während dieser Zwangspause können jedoch auch kein Cooperative Scheduling durchgeführt und keine anderen Codepfade ausgeführt werden.Um dieses Problem zu vermeiden, können Sie in der Runtime async-std die Funktion task::spawn_blocking() verwenden. Diese Funktion erwartet eine Closure, die anschließend in einem eigenen Thread ausgeführt wird. Dadurch wird der Haupt-Thread nicht blockiert, und seitens des Executors kann das Cooperative Scheduling durchgeführt werden. In Listing 7 sehen Sie die dafür erforderlichen Änderungen.
Listing 7: Synchrone Funktionsaufrufe 2/2
// Loop over the received data.
while let Some(row) = data_stream.try_next().await?
{
match row
{
QueryItem::Metadata(meta) =>
{
println!("{:?}", meta);
println!("");
},
QueryItem::Row(row) =>
{
println!("{:?}", row);
println!("");
// The CPU intensive task is running on a
// separate thread, and will not block the
// executor.
task::spawn_blocking(move ||
{
println!("Long running CPU
intensive task...");
std::thread::sleep(
core::time::Duration::from_secs(duration));
});
}
}
}
Der Thread, der über die Funktion task::spawn_blocking() gestartet wird, wird aus einem Thread-Pool genommen, der für blockierende Funktionsaufrufe reserviert ist. Wenn Sie – wie in diesem Beispiel – beim Aufruf der Funktion task::spawn_blocking() das Schlüsselwort await weglassen, führt der Haupt-Thread einfach seine Arbeit fort, ohne auf die neu gestarteten Threads zu warten.Daraus resultiert, dass der Haupt-Thread seine Arbeit um einiges schneller beendet hat als die nebenläufig gestarteten Threads, wodurch Ihr Programm beendet wird und die nebenläufigen Threads abgebrochen werden. Dieses Problem können Sie vermeiden, indem die nebenläufigen Threads mithilfe eines Channels mit dem Haupt-Thread kommunizieren und sich untereinander koordinieren.Zusätzlich bietet die gewählte asynchrone Runtime die Möglichkeit an, freiwillig an beliebig gewählten Code-Punkten ein CPU-Yielding durchzuführen. Dies geschieht durch den Aufruf der Funktion task::yield_now(). Dieser Ansatz ist zum Beispiel dann sehr von Vorteil, wenn Sie in einer asynchronen Funktion einen längeren CPU-intensiven Algorithmus implementieren möchten.Generell sollten Sie aufgrund der größer werdenden Komplexität vermeiden, in einer asynchronen Funktion CPU-intensive Operationen durchzuführen beziehungsweise synchrone Funktionen auszuführen. Je mehr asynchrone Funktionen mit entsprechenden CPU-Yielding-Points zur Verfügung stehen, desto besser kann der Executor im Hintergrund das Cooperative Scheduling durchführen.Eine weitere Funktionalität, die Rust in Kombination mit asynchronen Funktionen anbietet, sind sogenannte Async Blocks. Ein Async Block ist nichts anderes als ein Code-Abschnitt, der als Ergebnis eine Future zurückliefert, die wiederum über eine asynchrone Runtime ausgeführt werden kann. Hier ein einfaches Beispiel:
fn async_blocks()
{
let query1 = async
{
let _ = execute_query(
"SELECT TOP 10 BusinessEntityID,
FirstName, LastName, ModifiedDate FROM
Person.Person".to_string(), 0).await;
};
task::block_on(query1);
}
Ein Async Block bietet ebenfalls die Möglichkeit, CPU-Yielding-Points über das Schlüsselwort await zu definieren, an denen ein Cooperative Scheduling durch die asynchrone Runtime durchgeführt wird.
Fazit
In diesem Artikel haben Sie das asynchrone Programmiermodell von Rust kennengelernt, mit dem Sie in einer einfachen Art und Weise ein Cooperative Scheduling in Ihren Anwendungen realisieren können. Die Standard-Library von Rust definiert dafür die Trait Future, die über eine asynchrone Runtime Schritt für Schritt abgearbeitet werden kann.Fussnoten
- [1] Klaus Aschenbrenner, Multithreading, dotnetpro 10/2024, Seite 131 ff.,
- [2] Promises in JavaScript,
- [3] TAP im .NET Framework,
- [4] Trait Future,
- [5] async-std, https://docs.rs/async-std/latest/async_std/
- [6] Self Referential,
- [7] Tokio, https://docs.rs/tokio/latest/tokio/
- [8] smol, https://docs.rs/smol/latest/smol/
- [9] fuchsia-async,
- Tiberius,









