
13. Apr 2020
Lesedauer 6 Min.
Time-Series-Datenbanken
Vergleich von ZeitreihenDatenbanken
Shooting-Star Prometheus versus Klassiker InfluxDB.
Spricht man von Datenbanken, denken viele an relationale Datenbanken, analytische spaltenorientierte Datenbanken oder NoSQL-Datenbanken. Zeitreihendatenbanken (Time-Series-Datenbanken) fristen ein Nischendasein. Grund genug, einen Blick auf sie zu werfen.Entwickler können ab einem gewissen Grad an Erfahrung Datenverarbeitungsmuster typischen Datenbanksystemen zuordnen. Banktransaktionen zum Beispiel: Hier denken wir an relationale Systeme und an Funktionalitäten, welche durch Akronyme wie ACID zusammengefasst werden. SQL-Abfragen für relationale Datenbanken zu schreiben gehört zum Basis-Know-how eines Entwicklers. Wer in der Business-Intelligence-Welt (BI) Fuß gefasst hat, weiß, dass für statistische Auswertungen das, was in den Spalten steht, interessanter ist als das in den Reihen. CRUD-Operationen, für die relationale Datenbanken geschaffen wurden, sind hier sekundär. Gute analytische Datenbanken sind darauf optimiert, Daten spaltenweise auszulesen und zu aggregieren.Auch NoSQL-Datenbanken sind vermutlich den meisten vertraut. JSON-Daten lassen sich in Dokumentendatenbanken wie MongoDB ablegen, Schlüssel-Wert-Paare passen in spezielle Datenbanksysteme wie Redis. Graphen bilden Beziehungen ab und kommen in eine Graphdatenbank, und auch für Wide-Column-Szenarien fallen uns Lösungen ein.Welche Anwendungsmuster werden also durch Time-Series-Datenbanken gelöst?
Anwendungsfälle
Denken Sie an Sensordaten von Maschinen. Wärmesensoren liefern beispielsweise kontinuierlich Informationen über die Zeit. Um diese Daten zu sammeln, sind der Timestamp und die dem Timestamp zugeordneten Werte wesentlich, so lassen sich dann Graphen erstellen, die Veränderungen über die Zeit visualisieren.Als Entwickler denken wir auch an Systeminformationen aus unseren Rechnern und Servern. Es mag interessant sein, die CPU-Auslastung über die Zeit zu veranschaulichen. Streng genommen ist also jeder Taskmanager (Windows) oder Aktivitätenmanager (macOS), der Prozesse über die Zeit misst, eine Time-Series-Anwendung.Time-Series-Datenbanken
Welche Lösungen gibt es also, um Messdaten über die Zeit festzuhalten? Ein Blick auf die Seite DB-Engines [1] zeigt, dass es scheinbar einen Marktführer gibt. Geht es nach DB-Engines, ist InfluxDB die mit Abstand beliebteste Time-Series-Datenbank (Bild 1). Weitere Artikel im Internet kommen zu ähnlichen Aussagen [2]. Kurz zusammengefasst werden in Artikeln oft die folgenden vier Datenbanken als Referenz für Time-Series-Datenbanken genannt: InfluxDB, Graphite, TimeScaleDB und OpenTDSB.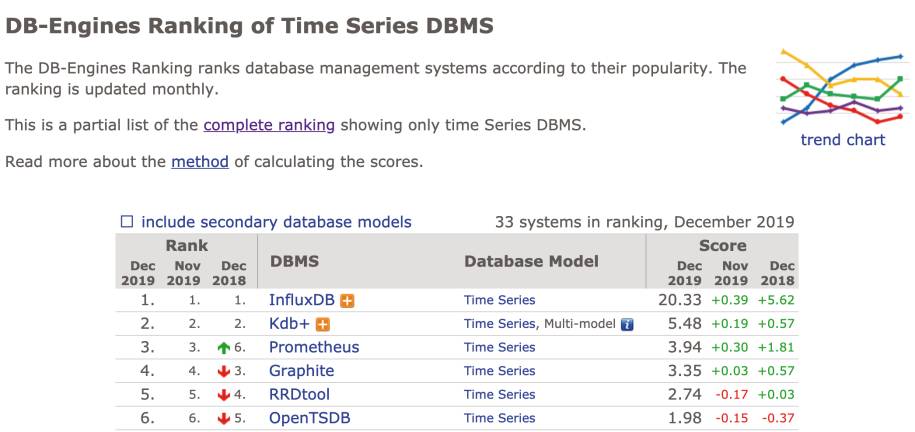
Rankingauf DB-Engines(Bild 1)
Autor
Wer aber auf Stackshare [3] und GitHub schaut, findet ein etwas anderes Ranking (Bild 2). Dort zeigt sich, dass es anscheinend einen neuen Herausforderer oder gar neuen Champion gibt: Prometheus [4]. Prometheus wird oft als Hybrid wahrgenommen. Es ist im Kern eine Time-Series-Datenbank, bietet daneben aber auch eine Monitoring-Plattform an.
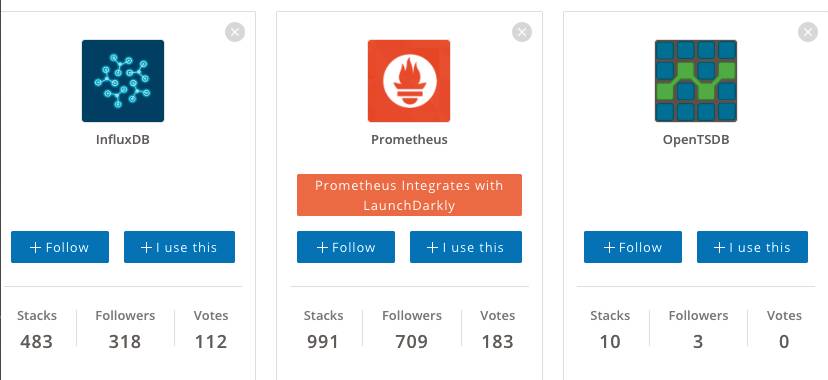
Stackshare-Ranking(Bild 2)
Autor
Es ist wie so oft eine Frage der Betrachtungsweise. InfluxDB wird oft als „I“ in einen Technologiestack eingebunden, der als TICK-Stack (Telegraf, InfluxDB, Chronograf, Kapacitor) bezeichnet wird. Alle vier Komponenten dieses Stacks bilden ab, was Prometheus tut. Prometheus aus dem Ranking zu entfernen, nur weil es mehr kann, als lediglich Zeitreihendaten zu speichern, wäre demnach nicht sinnvoll.Auf der Webseite von Prometheus [4] werden die Time-Series-Plattformen ebenfalls verglichen. Das Fazit lautet dort:
- InfluxDB ist besser geeignet für die Ereignisprotokollierung. Die kommerzielle Version bietet zudem Clustering für InfluxDB, was auch für die langfristige Datenspeicherung besser ist. Außerdem ist InfluxDB besser bei der Eventually Consistent View auf die Daten zwischen Replikaten.
- Prometheus ist besser, wenn es hauptsächlich um Metriken geht. Es bietet die leistungsfähigere Abfragesprache, dazu Alarm- und Benachrichtigungsfunktionalitäten. Für Prometheus spricht zudem die höhere Verfügbarkeit und Betriebszeit für Grafiken und Alarme.
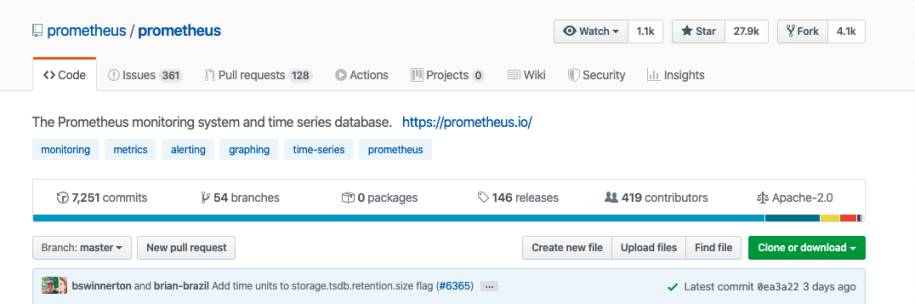
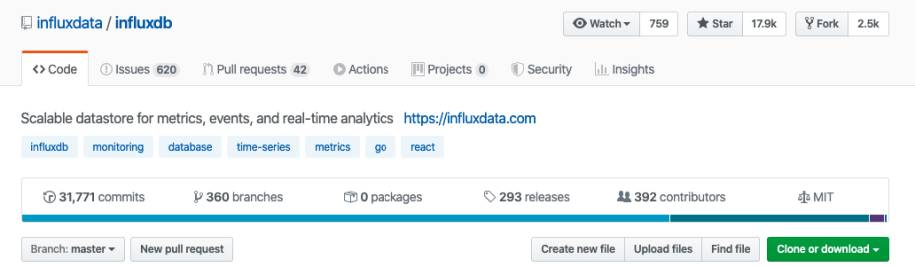
GitHubverzeichnet über 400 Mitwirkende zu Prometheus(Bild 3)
Autor
InfluxDBhat laut GitHub etwas weniger Mitwirkende als Prometheus(Bild 4)
Autor
Allzu weit liegen die Zahlen jedoch nicht auseinander. Bei einem Vergleich mit anderen Werkzeugen, wie etwa OpenTSDB, können diese Metriken allerdings durchaus das wesentliche Entscheidungsmerkmal sein. Wenn niemand ein Werkzeug mehr weiterentwickelt, ist man gezwungen, irgendwann umzusteigen.Auch die Aktivitätsanzeige auf GitHub [5] zeigt mehr Aktivitäten aufseiten von Prometheus (Bild 5) als bei anderen Time-Series-Datenbanken. Diese Information kann ebenfalls entscheidend sein.
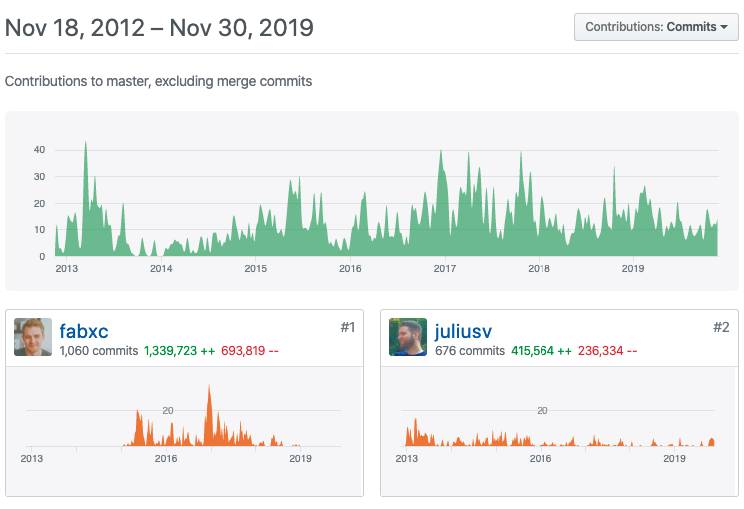
Prometheuswird aktiv weiterentwickelt, wie die GitHub-Zahlen zeigen(Bild 5)
Autor
Der Prometheus-Weg
Um zu entscheiden, ob man auf althergebrachte Technologien setzt oder gleich mit Prometheus zu arbeiten beginnt, gilt es zu verstehen, was Prometheus speziell auszeichnet und von anderen Datenbanken unterscheidet.Wer mit InfluxDB arbeitet, stellt schnell fest, dass vieles einem Schema folgt, das man von Datenbanken gewohnt ist. Es ist möglich, Daten in diese Datenbank zu pushen und dann auch wieder auszulesen. Prometheus kommt mit einem neuen Konzept. Der Slogan bei Prometheus lautet: Pull statt Push. Anwendungen exponieren ihre Metadaten über ein API und Prometheus zieht die Daten an sich. Prometheus bietet APIs für Clients an, um Messdaten über diese Schnittstellen zu exponieren. Auf GitHub sind die Client-APIs zu finden. Darunter auch die APIs für Python [6] und Java [7].Der Standardweg ist also, Daten zu ziehen. Der Weg, Daten direkt in Prometheus zu pushen, ist nur für Sonderfälle gedacht, in denen es nicht möglich ist, die Daten zu exponieren. Als klassischen Referenzfall für einen Push-Algorithmus nennt die Webseite eine Anwendung, die nur Ergebnisse meldet.Vier Metriken und ein Port
Prometheus stellt vier Metriken bereit: Counter, Gauge, Summary und Histogramm. Die folgende Referenzimplementierung zeigt, wie Code in Python instrumentiert wird, um Daten für Prometheus bereitzustellen. Konkret bedeutet das:- Es wird ein Port registriert, an welchem die Daten für Prometheus bereitgestellt werden.
- Der Code wird so weit instrumentiert, dass die Daten an diesen Port geschickt werden.
Listing 1: Python-Implementierung
from prometheus_client import \
start_http_server, Summary
import random
import time
# Create a metric to track time spent
# and requests made.
REQUEST_TIME = Summary( \
'request_processing_seconds', \
'Time spent processing request')
# Decorate function with metric.
@REQUEST_TIME.time()
def process_request(t):
"""A dummy function that takes some time."""
time.sleep(t)
if __name__ == '__main__':
# Start up the server to expose the metrics.
start_http_server(8000)
# Generate some requests.
while True:
process_request
(random.random()) Daten abholen
Wesentlich ist, dass im Code alle Daten an Port 8000 exportiert werden. Mithilfe eines Werkzeugs wie beispielsweise cURL oder eines Browsers lässt sich dies verifizieren, indem man die Seite mit dem Port aufruft. Nachdem wir also die Daten über einen Port bereitstellen, wird es auch Zeit, diese abzuholen.Werfen Sie dazu einen Blick auf die Architektur (Bild 6). Die Daten sind bereitgestellt. Nun gilt es sie einzubinden. Das klappt am einfachsten, indem Prometheus in einem Docker-Container gestartet wird.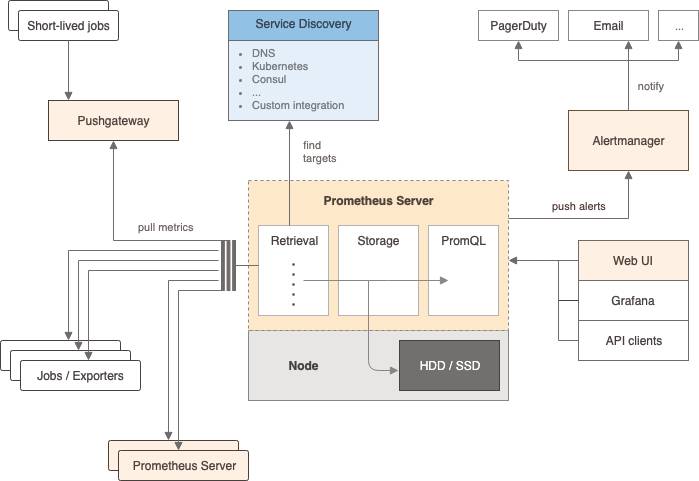
Die Architekturvon Prometheus(Bild 6)
Autor
docker run --name prometheus -d -p 127.0.0.1:9090:9090 prom/prometheus
Danach kann man eine Verbindung mit dem Container mit folgendem Befehl herstellen:
docker exec -it prometheus /bin/sh
Im Container finden Sie die Datei prometheus.yaml in der Hierarchie des Konfigurationsverzeichnisses etc. Dort können Sie die Server angeben, die „gescrapt“ werden sollen.
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets:
['127.0.0.1:9090',
'127.0.0.1:9100']
labels:
group: 'prometheus'
Werden die Anpassungen korrekt vorgenommen, kann man mehrere Targets definieren und auslesen. Bild 7 zeigt, dass mehrere Targets in Prometheus eingebunden worden sind.
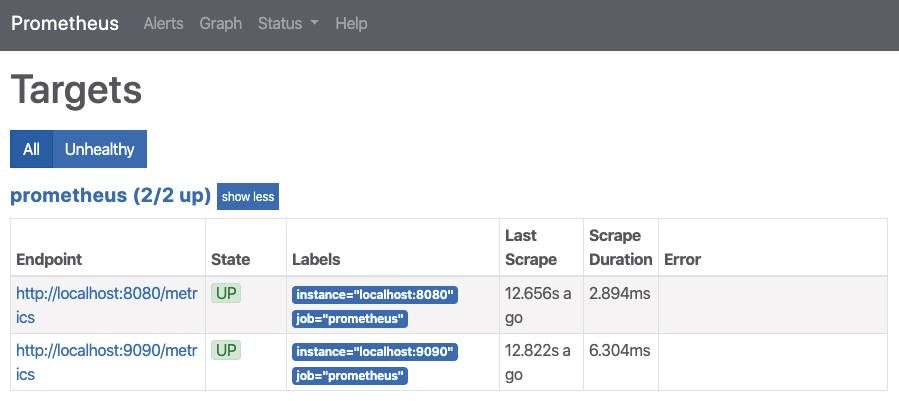
Zwei Targetswurden eingebunden(Bild 7)
Autor
Der USP von Prometheus
An diesem Punkt angelangt, gilt es zu unterstreichen, was Prometheus so speziell macht. Es geht hier nicht in erster Linie darum, wie Daten im Detail in einer Datenbank gespeichert werden. Wesentlich ist vielmehr, dass mit der von Prometheus verwendeten Methode ein Standard geschaffen wird. Daten, die mit Prometheus-Clients exponiert werden, können auch von anderen Frameworks verarbeitet werden. Man könnte also beispielsweise auch einen Kafka-Producer schreiben, der die Daten vom Port abholt und in einem Kafka-Broker speichert. Außerdem können die in Prometheus abgelegten Daten jederzeit mithilfe von Grafana oder einem anderen Visualisierungswerkzeug darstellt werden.Fazit
Ob Prometheus der neue Star am Himmel der Time-Series-Datenbanken ist oder nicht, darüber kann man debattieren. Wesentlich ist, dass Prometheus durch das Exponieren der APIs einen neuen Ansatz wählt, dank dem sich auch noch andere Werkzeuge in die Pipeline einbinden lassen. Aufgrund der hohen Beliebtheit von Prometheus ist es definitiv empfehlenswert, es bei der Suche nach einer Zeitreihendatenbank in die engere Wahl einzubeziehen.Fussnoten
- DB-Engines,
- DZone,
- Stackshare, https://stackshare.io/
- Prometheus,
- Prometheus auf GitHub,
- Python-Client für Prometheus,
- Java-Client für Prometheus,











