
12. Feb 2024
Lesedauer 17 Min.
Die ersten Schritte
Rust-Kurs, Teil 1
Zum achten Mal in Folge beliebteste Programmiersprache in der alljährlichen StackOverflow-Umfrage – was macht Rust aus? Unser mehrteiliger Rust-Kurs führt Sie in die Sprache ein.

Rust ist eine moderne Systemprogrammiersprache mit dem Fokus auf Sicherheit, Geschwindigkeit und effizienter, fehlerfreier paralleler Programmierung. In der Welt der systemnahen Softwareentwicklung hat Rust in den letzten Jahren rasch an Bedeutung gewonnen, insbesondere durch den Einsatz im Windows-Kernel und eine erste einfache Unterstützung innerhalb von Linux.Im Rahmen dieser Artikelserie werden wir einen genaueren Blick auf Rust werfen und uns ansehen, wie leistungsfähig die Sprache ist, auch im Vergleich mit C/C++.
Historie und Motivation
Die Geschichte von Rust begann im Jahr 2006, als Graydon Hoare, damals Mitarbeiter bei Mozilla, die Entwicklung der Programmiersprache in Angriff nahm, anfangs zunächst noch im Rahmen eines persönlichen Projekts. Nachdem Mozilla indes das Potenzial der Programmiersprache erkannt hatte, beteiligte sich das Unternehmen seit dem Jahr 2009 offiziell an der Entwicklung.Eine wesentliche Motivation bei der Rust-Entwicklung war es, die Speicherverwaltungs- und -zuweisungsprobleme zu vermeiden, die in C und C++ häufig auftreten.Offiziell angekündigt wurde Rust erstmals im Jahr 2010; der Compiler wurde damals noch in Objective CAML implementiert. Im selben Jahr begann jedoch bereits der Wechsel zu einem neuen Compiler, der selbst in Rust geschrieben wurde. Dieser Compiler nennt sich rustc, er verwendet das LLVM Compiler Framework als Backend und kann sich seit dem Jahr 2011 erfolgreich selbst kompilieren.Um die Zukunft von Rust sicherstellen zu können, gründete das Rust-Kernteam im Jahr 2020 eine Rust-Stiftung, um die Eigentumsrechte an sämtlichen Markenzeichen und Domainnamen zu übernehmen wie auch die finanzielle Verantwortung für deren Kosten. Am 8. Februar 2021 gaben die Unternehmen AWS, Huawei, Google, Microsoft und Mozilla sowie fünf Mitglieder aus dem Rust-Team die Gründung der Rust Foundation bekannt.Das Design von Rust wurde stark von den Erfahrungen und Herausforderungen bei der Entwicklung großer, komplexer Systeme wie der Servo-Webbrowser-Engine und der Mozilla-Software beeinflusst.Grundlegendes Ziel der Rust-Entwickler ist es, eine Programmiersprache anzubieten, die gleichzeitig effizient, sicher und leicht verständlich ist. Rust generiert hierbei ebenso wie C/C++ Maschinencode für unterschiedliche CPU-Plattformen (x64, ARM), der direkt ohne Umwege über eine Virtual Machine (.NET Runtime, Java VM) auf der Zielplattform ausgeführt wird. Dadurch ist Rust den in der Systemprogrammierung klassisch eingesetzten Sprachen überlegen.Rust vereint dabei Features von unterschiedlichsten Programmierparadigmen, einschließlich funktionaler, imperativer und objektorientierter Programmierung.Rust 1.0 wurde im Mai 2015 veröffentlicht. Die Version markierte einen wichtigen Meilenstein, da sie die Basis für zukünftige Entwicklungen der Programmiersprache legte. Seitdem hat Rust regelmäßige Updates erhalten, die sowohl die Leistungsfähigkeit als auch die Benutzerfreundlichkeit verbessern.In den letzten Jahren wuchs die Popularität von Rust stetig, angetrieben durch die Effizienz in der Systemprogrammierung. Verschiedenste Projekte und Unternehmen, darunter Microsoft, Google und Amazon Web Services, haben Rust für ihre Systemprogrammierung übernommen. So veröffentlichte etwa Mark Russinovich, CTO von Microsoft Azure, am 10. Mai 2023 auf X (ehemals Twitter) einen Tweet [1], in dem er bekannt gab, dass auch im Windows-Kernel für Neuentwicklungen teilweise auf Rust gesetzt wird.Rust wird mittlerweile in einer Vielzahl von Anwendungen eingesetzt, von Betriebssystemen über Webanwendungen bis hin zu eingebetteten Systemen.Speichersicherheit durch Ownership
Einer der größten Vorteile von Rust liegt in der Implementierung von parallelen Programmen mittels Multi-Threading, wobei Rust hier großen Wert auf die Sicherheit und die Geschwindigkeit der generierten Anwendungen legt.Rust ermöglicht es, mehrere Threads parallel in einem Programm sicher zu verwenden, ohne die Gefahr, dass Race Conditions entstehen. Rust verzichtet dabei auf einen Garbage-Collection-Mechanismus, wie Sie ihn zum Beispiel vom .NET Framework her kennen. Stattdessen setzt die Sprache auf ein System, bei dem Speicherressourcen direkt und deterministisch verwaltet werden. Das geschieht durch das sogenannte „Ownership and Borrowing“-System. Es besagt, dass Daten in Rust zu einem bestimmten Zeitpunkt immer nur einen einzigen Besitzer (Owner) haben können und dieser für die Freigabe des Speichers verantwortlich ist.Das „Ownership and Borrowing“-System stellt sicher, dass Threads gleichzeitig auf Daten zugreifen können, solange sie die Regeln dieses Systems befolgen. Diese Regeln werden durch den Rust-Compiler erzwungen, der entsprechende Fehler während der Kompilierung erzeugt, sobald der von Ihnen geschriebene Rust-Code diese Regeln verletzt. Das erfordert etwas Lernaufwand seitens der Entwickler, führt aber zu speichersicheren Anwendungen.Wird in Rust ein Wert einer Variablen zugewiesen, wird diese Variable zum Besitzer. Verlässt der Besitzer den Gültigkeitsbereich, wird der zugeordnete Speicher automatisch freigegeben, ohne dass ein separater Aufruf eines Garbage Collectors notwendig ist. Dadurch werden Performance-Probleme vermieden, die durch den nicht-deterministischen Aufruf eines Garbage Collectors entstehen könnten.Daten können in Rust – wie schon angesprochen – immer nur einen einzigen Besitzer zu einem bestimmten Zeitpunkt haben, was bedeutet, dass dieser Besitzer für die Freigabe der Variablen und deren Speicher verantwortlich ist.In der Programmierung ist es jedoch oft notwendig, mehrere Zugriffe auf die gleichen Daten zuzulassen. Rust erlaubt daher das Ausleihen (Borrowing) von Daten, damit andere Teile des Codes auf die Werte zugreifen können, entweder als lesende/schreibende Referenz (mutable – veränderbar) oder als nur lesende Referenz (immutable – nicht veränderbar). Das Borrowing-System stellt sicher, dass zu keinem Zeitpunkt gleichzeitig mutable- und immutable-Referenzen auf dieselbe Variable existieren. Diese Vorgehensweise ermöglicht es, sicher auf gemeinsam genutzte Daten in einer Multi-Threading-Anwendung zuzugreifen, ohne die Integrität des Programms zu gefährden.Die ersten Schritte mit Rust
Nachdem Sie einen Überblick über die Geschichte, die Zielsetzung und die Vorteile von Rust bekommen haben, möchte ich Ihnen nun die ersten Schritte mit Rust näherbringen und zeigen, wie das klassische Hello-World-Programm in Rust implementiert wird.Als Erstes gilt es dazu den Rust-Compiler und alle notwendigen Tools zu installieren. Die einfachste Möglichkeit ist hierbei der Download über die Website [2], die Ihnen abhängig vom installierten Betriebssystem ein entsprechendes In-stallationsprogramm für alle notwendigen Tool anbietet (Bild 1). In Tabelle 1 sehen Sie die wichtigsten Tools aufgelistet, die dabei installiert werden und die Sie im Alltag immer wieder benötigen werden.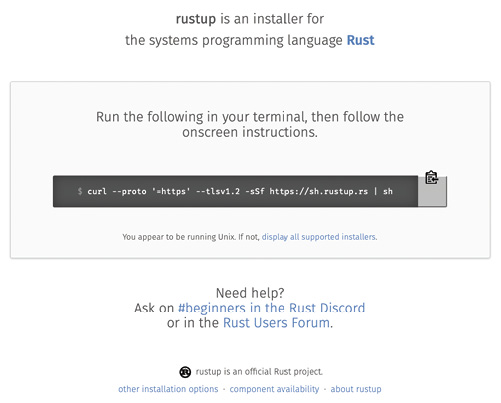
Das Installationsprogramm herunterladen (Bild 1)
Autor
Tabelle 1: Die wichtigsten Rust-Tools
|
Als Entwicklungsumgebung für Rust bietet sich Visual Studio Code an: Hierzu gibt es mit dem Rust-Analyzer eine äußerst leistungsstarke Erweiterung, die Ihnen in effizienter Art und Weise die Entwicklung und auch das Debugging Ihrer Rust-Programme ermöglicht (Bild 2).
Der Rust-Analyzer in Visual Studio Code (Bild 2)
Autor
Das folgende Listing zeigt Ihnen nun das Hello-World-Programm – implementiert in Rust:
fn main()
{
println!("Hello World from the Rust programming
language!");
}
Wie Sie aus dem Listing erkennen können, besteht das Programm aus der Funktion main(), die den Eintrittspunkt darstellt. Diese Funktion wird automatisch aufgerufen, sobald das Programm gestartet wird. Eine Funktion wird hierbei über das Schlüsselwort fn definiert und kann innerhalb der Klammern mehrere Parameter definieren, die beim Aufruf übergeben werden müssen. Da die Funktion main() keinen Rückgabewert definiert hat, wird auch nichts (void) zurückgeliefert.In der nächsten Zeile wird dann ein entsprechender String auf der Konsole ausgegeben. Hierbei wird das Makro println!() eingesetzt. Aufrufe von Makros werden in Rust mit dem Ausrufezeichen (!) gekennzeichnet. Wie Sie ebenfalls aus dem Listing ersehen können, wird jeder Funktionsaufruf durch einen Strichpunkt (;) abgeschlossen, und jeder Codeblock muss in geschwungene Klammern ({}) gesetzt sein.Um nun den Rust-Code zu Maschinencode zu kompilieren und daraus ein ausführbares Programm zu erzeugen, rufen Sie mit dem folgenden Befehl auf der Kommandozeile den Rust-Compiler auf:
rustc main.rs
Das Ergebnis ist ein vollständig ausführbares Programm, das Sie auf der Kommandozeile aufrufen können.Wenn Sie auf einem Linux-System unterwegs sind, können Sie sich auch weitere Informationen über die erzeugte Binärdatei ermitteln lassen (Bild 3). Dazu verwenden Sie den folgenden Befehl:
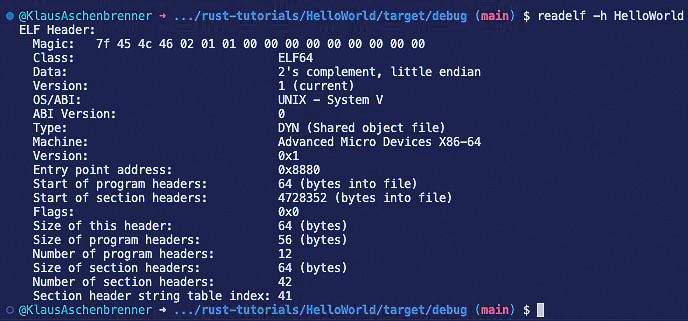
Unter Linux weitere Informationen anzeigen lassen (Bild 3)
Autor
readelf -h main
Bei komplexeren Rust-Projekten, die sich über viele Quellcodedateien erstrecken, macht es wenig Sinn, den Rust-Compiler immer händisch aufzurufen und alle Quellcodedateien als Parameter mitzugeben. Rust bietet Ihnen hierzu den Paketmanager cargo an, mit dem Sie größere Rust-Projekte automatisch kompilieren können.Weiterhaben Sie die Möglichkeit, alle dazugehörigen Abhängigkeiten Ihres Projektes entsprechend zu verwalten. Der Paketmanager wird über den Befehl cargo auf der Kommandozeile aufgerufen. Tabelle 2 gibt Ihnen einen Überblick über die wichtigsten Befehle, die unterstützt werden.
Tabelle 2: Die wichtigsten cargo-Befehle
|
Um die Vorteile von cargo kennenzulernen, legen Sie mit dem folgenden Befehl ein neues Rust-Projekt an:
cargo new HelloWorld
Daraufhin generiert Ihnen cargo im aktuellen Ordner die Projektstruktur, die Sie in Bild 4 sehen.
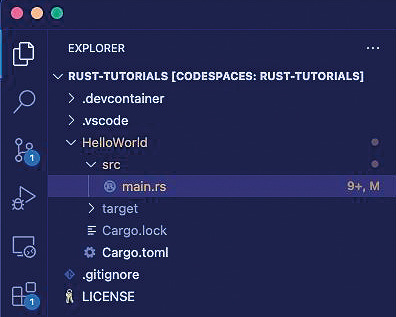
Die von cargo generierte Projektstruktur (Bild 4)
Autor
Wie Sie aus der Abbildung erkennen können, besteht das neue Projekt aus der Datei main.rs, die sich im Ordner src befindet. Des Weiteren wurde im Hauptverzeichnis die Datei Cargo.toml hinzugefügt.Hierbei handelt es sich um ein sogenanntes Manifest-File, das alle externen Abhängigkeiten zu anderen Bibliotheken verwaltet. Das folgende Listing zeigt den aktuellen Inhalt dieser Datei:
[package]
name = "HelloWorld"
version = 20.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Im Abschnitt [package] werden die Eigenschaften Ihres Rust-Projektes definiert – der Name, die Version und die Edition von Rust, die Sie einsetzen möchten. Die aktuelle Edition ist hierbei 2021.In späteren Folgen dieser Artikelserie werden Sie auch den Abschnitt [dependencies] näher kennenlernen. Er wird dann entsprechende Verweise auf andere Rust-Bibliotheken abspeichern, die Sie in Ihrem Code verwenden.Innerhalb der Datei main.rs im Ordner src können Sie wiederum den Code aufnehmen, den Sie bereits ganz zu Anfang gesehen haben – das klassische Hello-World-Programm. Um nun mit cargo ein Projekt zu kompilieren, führen Sie auf der Kommandozeile folgenden Befehl aus:
cargo build
Dieser Befehl kompiliert nun im Ordner src (und allen weiteren Unterordnern) alle vorhandenen .rs-Quellcodedateien und generiert daraus wiederum ein ausführbares Programm. Sämtliche generierten Dateien werden hierbei im Ordner target abgelegt. Das generierte Programm können Sie über den folgenden Befehl ausführen:
cargo run
Möchten Sie die erzeugten Dateien der Kompilierung löschen, führen Sie den folgenden Befehl aus:
cargo clean
In weiterer Folge werden wir ausschließlich cargo für unsere Programme verwenden, da es um einiges effizienter ist, mit dem Paketmanager zu arbeiten, als jedes Mal händisch den Rust-Compiler aufzurufen.
Datentypen in Rust
Nachdem Sie im letzten Abschnitt gesehen haben, wie Sie Ihr erstes Rust-Programm erzeugen können (händisch oder mit dem Paketmanager cargo), möchte ich Ihnen in diesem Abschnitt die verschiedenen unterstützten Datentypen von Rust näherbringen, bevor wir uns dann in den nächsten Abschnitten mit weiterführenden Konzepten der Programmiersprache beschäftigen.In Tabelle 3 sind die wichtigsten einfachen Datentypen zu sehen, die von Rust unterstützt werden.Tabelle 3: Die wichtigsten einfachen Datentypen
|
Bevor wir damit beginnen, Variablen zu definieren, müssen wir uns auch mit der Namenskonvention von Rust näher beschäftigen, die vorschreibt, wie die Namen unterschiedlicher Sprachelemente aufgebaut sein sollen. Tabelle 4 gibt Ihnen hierzu einen entsprechenden Überblick.
Tabelle 4: Namenskonventionen von Rust
|
Wenn Sie diese Namenskonventionen nicht strikt einhalten, werden während der Kompilierung entsprechende Warnungen vom Rust-Compiler generiert – die Sie nicht ignorieren sollten.Eine Variable können Sie mit dem Schlüsselwort let in Rust definieren. Den Datentyp können Sie hierbei weglassen, weil der Rust-Compiler in der Lage ist, auf Basis des initialisierten Wertes den Datentyp abzuleiten. Des Weiteren haben Sie auch die Möglichkeit, bei Zahlen den entsprechenden Datentyp als Suffix anzugeben. Listing 1 zeigt dazu ein einfaches Beispiel.
Listing 1: Initialisierung von Variablen
fn work_with_variables()
{
let a: i32 = 12;
let b;
b = 34;
let c = a * b;
println!("{} * {} = {}", a, b, c);
println!("Range of i32: {} - {}",
i32::min_value(),
i32::max_value());
// Variable initialization with a suffix
let d = 3.14f32;
let e = 3.14f64;
let f = 42i8;
let g = 89usize;
}
Wie Sie anhand dieses Listings erkennen können, wurden für die beiden Variablen b und c keine Datentypen angegeben, da der Compiler diese Datentypen (i32) entsprechend ableiten kann. Für die Variablen d, e, f und g wurde der Datentyp über das Suffix definiert.Damit Sie im Makro println!() auf Variablen zugreifen können, müssen Sie hierzu den Platzhalter {} verwenden. Wenn Sie versuchen, eine Variable direkt zu referenzieren, führt das zu einer entsprechenden Fehlermeldung seitens des Compilers. Über die beiden Konstanten MIN und MAX lässt sich für einen beliebigen numerischen Datentyp der Minimal- und Maximalwert ermitteln.Alle Variablen des vorherigen Listings wurden als immutable definiert, das heißt, dass diese nicht veränderbar sind. Sie können eine solche Variable einmalig initialisieren, jedoch zu einem späteren Zeitpunkt ihren Wert nicht mehr verändern. Wenn Sie versuchen, eine der Variablen nach der Ini-tialisierung zu verändern, zum Beispiel durch das Statement
c = 45;
bekommen Sie durch den Compiler einen entsprechenden Fehler generiert.Damit Sie eine Variable nach ihrer Initialisierung auch ändern können, müssen Sie diese bei der Deklaration als veränderlich (mutable) mit dem Schlüsselwort mut kennzeichnen. Das folgende Listing zeigt Ihnen hierzu ein einfaches Beispiel:
fn work_with_variables()
{
let mut d: i32 = 42;
println!("d = {}", d);
d = 89;
println!("d = {}", d);
}
Dass Variablen standardmäßig nicht geändert werden können, wird in Rust als „Immutable by Default“ bezeichnet und soll Programmierfehler verhindern. Möchten Sie eine Variable zu einem späteren Zeitpunkt verändern können, müssen Sie den Compiler wie im obigen Code explizit mit dem Schlüsselwort mut darauf hinweisen.Eine weitere Besonderheit, die Rust in Kombination mit Variablen unterstützt, ist das sogenannte „Shadowing“. Damit sind Sie in der Lage, eine Variable zu definieren, deren Name bereits von einer älteren Variablen verwendet wird. Die ältere Variable wird dabei durch die neuere Variable „überdeckt“ beziehungsweise ersetzt. Das folgende Listing zeigt Ihnen ein Beispiel für ein solches Shadowing von Variablen:
fn variables_shadowing ()
{
let a = 42;
println!("a = {}", a);
let a = 89;
println!("a = {}", a);
} Arrays und Vektoren
Rust unterstützt drei verschiedene Möglichkeiten, um eine Sequenz von Werten im Hauptspeicher darstellen zu können. Die erste Möglichkeit ist ein klassisches Array, das aus einer fix definierten Anzahl von Werten besteht, die bereits zur Kompilierung feststehen müssen. Ein Array kann zu einem späteren Zeitpunkt nicht mehr verändert werden.Die zweite Möglichkeit ist ein sogenannter Vektor, der dynamisch zur Laufzeit am Heap angelegt wird und dessen Größe veränderlich ist. Sie können neue Werte in einen Vektor aufnehmen und bereits existierende Werte daraus löschen.Sehen wir uns nun diese zwei Möglichkeiten im Detail an. Listing 2 zeigt verschiedene Funktionalitäten, die Sie mit Arrays durchführen können.Listing 2: Arbeiten mit Arrays
fn work_with_arrays()
{
// Define some arrays
let mut databases = ["SQL Server", "Oracle",
MySQL", "PostgreSQL"];
let prime_numbers = [1, 2, 3, 5, 7, 11, 13, 17, 19];
println!("Number of databases: {}",
databases.len());
databases.sort();
for db in databases
{
println!("{}", db);
}
for i in prime_numbers
{
println!("{}", i);
}
// Defines an array of 1000 ones
let number_ones = [1; 1000];
println!("Number of 1: {}",
number_ones.len());
}
Wie Sie aus dem Listing erkennen können, wird ein Array mithilfe der eckigen Klammern definiert. Innerhalb dieser Klammern geben Sie dann einfach die gewünschten Werte an, die natürlich alle den gleichen Datentyp aufweisen müssen.Jeder Array-Datentyp besitzt ebenfalls zusätzliche Funktionen, die Sie aufrufen können. Beim Array databases wird zum Beispiel über die Funktion sort() eine alphabetische Sortierung durchgeführt. Da dieses Array durch den Funktionsaufruf verändert wird, muss auch die Variable entsprechend über das Schlüsselwort mut als veränderlich gekennzeichnet werden.Eine weitere Möglichkeit bei der Definition eines Arrays ist es, zwei Werte durch einen Strichpunkt in den eckigen Klammern zu trennen. Der erste Wert gibt hierbei den Wert im Array an, und der zweite numerische Wert gibt an, wie oft der Eintrag im Array wiederholt werden soll. Am Ende von Listing 2 wird hierzu ein Array definiert, das tausendmal den Wert 1 beinhaltet.Die Anzahl der Einträge in einem Array ist statisch und muss zur Kompilierung festgelegt werden, da ein Array immer im Stack Frame der aktuellen Funktion abgespeichert wird. Daraus folgt ebenfalls, dass Ihr Rust-Programm einen Stack Overflow generieren kann, wenn ein Array zu groß definiert wurde.Die folgende Array-Definition führt zum Beispiel zu einem Stack Overflow, da hier 8 MB an Daten für ein Array allokiert werden:
let large_array = [0u64; 0x100000];
Hierbei wird der Wert 0 als 64-bit Unsigned Integer 1 048 576-mal in einem Array abgelegt. Bild 5 zeigt die Fehlermeldung, die Sie bei Ausführung des Programms erhalten.
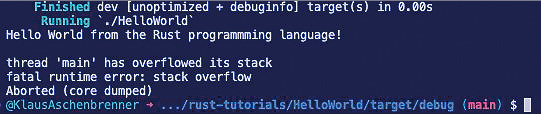
Fehlermeldung bei Stack Overflow (Bild 5)
Autor
Möchten Sie ein veränderliches Array nutzen, bietet Ihnen Rust den schon erwähnten Vektor an, der im Unterschied zu einem Array immer dynamisch am Heap allokiert wird und daher von der Größe her veränderlich ist. Listing 3 zeigt die Verwendung von Vektoren.
Listing 3: Arbeiten mit Vektoren
fn work_with_vectors()
{
let mut databases = vec!["SQL Server"];
databases.push("Oracle");
databases.push("Access");
databases.push("MySQL");
// Remove the vector entry on index 1
databases.remove(1);
// Insert a new entry into the vector
Databases.insert(1, “PostgreSQL”);
// Sorts the vector
databases.sort();
// Removes the last entry of the vector
databases.pop();
for db in databases
{
println!("{}", db);
}
// Produces a new vector with the digits 0 - 9
let mut digits: Vec<i8> = (0..10).collect();
// Reverse the vector
digits.reverse();
for i in digits
{
println!("{}", i);
}
}
Wie aus dem Listing ersichtlich ist, wird ein Vektor über das Macro vec! erzeugt. Innerhalb der eckigen Klammern können Sie wiederum mehrere Werte angeben, die im Vektor nach dessen Definition enthalten sein sollen.Weitere zusätzliche Einträge können dem Vektor über die Funktionen push() und insert() hinzugefügt werden, und bereits existierende Einträge lassen sich über die Funktionen pop() und remove() entfernen. Bei den Funktionen insert() und remove() können Sie einen entsprechenden Index angeben, wohingegen die Funktionen push() und pop() immer am Ende des Vektors einen Eintrag hinzufügen beziehungsweise daraus entfernen.Der Vektor databases wurde hierbei wieder mit dem Schlüsselwort mut gekennzeichnet, da anschließend über die Funktion sort() erneut eine Sortierung durchgeführt wurde. Eine weitere Möglichkeit ist es, einen Vektor aus einem sogenannten Iterator zu initialisieren.In Listing 3 wurde hierzu ein Iterator definiert, der die Zahlen 0 bis 9 zurückliefert. Über die Funktion collect() wird dieser Iterator zu einer Collection transformiert und anschließend damit der Vector digits initialisiert. Auf Iteratoren werde ich in einem späteren Artikel näher zu sprechen kommen.
Slices
Ein sogenannter Slice ist in Rust ein Teilbereich eines Arrays oder eines Vektors, der als Referenz in einer Variablen abgespeichert wird. Listing 4 zeigt die Definition von zwei Slices, welche sich auf ein Array beziehungsweise einen Vektor beziehen.Listing 4: Definition von Slices
fn work_with_slices()
{
// Define an array and a vector
let databases_array = ["SQL Server", "Oracle",
"MySQL", "PostgreSQL"];
let databases_vector = vec!["SQL Server",
"Oracle", "MySQL", "PostgreSQL"];
// Define some slices
let array_slice = &databases_array;
let vector_slice = &databases_vector;
// Print out both slices
print_slice(array_slice);
print_slice(vector_slice);
// Print out some parts of an array or vector
// through the use of slices
print_slice(&databases_array[0..3]);
print_slice(&databases_vector[1..]);
print_slice(&databases_array[..4]);
}
Bei den beiden Slices array_slice und vector_slice handelt es sich um sogenannte Fat Pointer in Rust. Ein Fat Pointer umfasst zwei Word-Werte, wobei der erste Wert der Zeiger auf die Startposition innerhalb des Arrays/Vektors ist und der zweite Word-Wert die Anzahl der Elemente im Slice umfasst. Bild 6 veranschaulicht dieses Konzept.
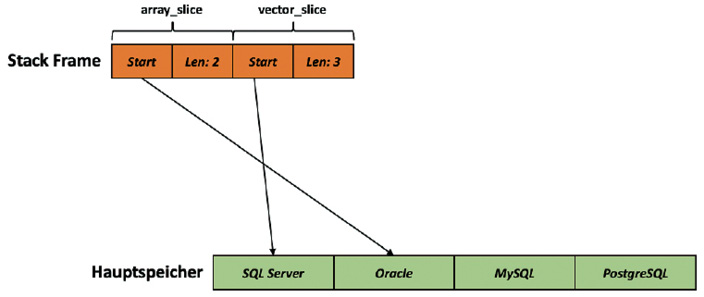
Fat Pointer: array_slice und vector_slice (Bild 6)
Autor
Wie Sie aus der Abbildung erkennen können, werden die beiden Slices wiederum als lokale Variablen im Stack Frame der aktuellen Funktion abgespeichert. Der Slice array_slice speichert eine Referenz auf die Hauptspeicheradresse des Arrays databases_array innerhalb des Stack Frame, während der Slice vector_slice eine Referenz auf die Hauptspeicheradresse des Vektors databases_vector, der dynamisch am Heap allokiert wurde, speichert.Nachdem ein Slice sich entweder auf ein Array oder einen Vektor beziehen kann, können Sie nun generischen Code schreiben, der zum Beispiel Elemente eines Slices auf der Konsole ausgibt. Das folgende Listing zeigt die Definition der Funktion print_slice(), die den übergebenen Slice mit String-Referenzen entsprechend ausgibt:
// Prints a slice of string references
fn print_slice(str: &[&str])
{
for s in str
{
println!("{}", *s);
}
}
Da Sie eine Referenz auf einen String erhalten, muss bei der Ausgabe diese Referenz über den Operator * dereferenziert werden, um auf den eigentlichen String-Wert zugreifen zu können.Natürlich muss ein Slice nicht ein komplettes Array beziehungsweise einen kompletten Vektor umfassen, sondern kann sich auch nur auf einen bestimmten Teilbereich beziehen. Hierzu geben Sie in eckigen Klammern einfach den gewünschten Teilbereich an, der im Slice enthalten sein soll. Diese Vorgehensweise sehen Sie bei den letzten drei Aufrufen der Funktion print_slice() innerhalb von Listing 4.
Tupel
Eine weitere Besonderheit der Programmiersprache Rust sind Tupel (englisch: tuples). Hierbei handelt es sich um eine Zusammenfassung von mehreren Werten, die auch aus unterschiedlichen Datentypen bestehen können. Die Werte eines Tupels werden dabei in einem Klammernpaar aufgelistet. Sehen Sie sich dazu die folgende Definition näher an:
let author = ("Klaus", "Vienna", 1980);
Dieses Tupel besteht insgesamt aus drei verschiedenen Werten, wobei es sich beim ersten und zweiten Wert um jeweils eine String-Referenz handelt und beim dritten Wert um einen Integer. Die einzelnen Werte des Tupels können Sie nun über einen Index ansprechen: author.0 liefert Ihnen den ersten String zurück, author.1 den zweiten String, und author.2 gibt Ihnen den Integer-Wert zurück.Wie Sie anhand dieser Schilderung erkennen können, können Sie den einzelnen Werten in einem Tupel keinen Variablennamen zuweisen. Diese Möglichkeit bieten Ihnen zum Beispiel sogenannte Structs, auf die wir in einem der nächsten Artikel noch näher eingehen werden. Der folgende Befehl gibt Ihnen die Informationen des Tupels auf der Kommandozeile aus.
println!("{} lives in {}, and is born in the year {}.",
author.0,
author.1,
author.2);
Tupel sind immer dann von Vorteil, wenn Sie mehrere Informationen in einer Variablen zusammenfassen möchten. Wie Sie in den weiteren Folgen dieser Artikelserie sehen werden, liefern Funktionen in Rust sehr oft Tupel als Ergebnis zurück:
- Wenn ein Fehler aufgetreten ist, wird ein Exception-Objekt zurückgeliefert.
- Ist hingegen kein Fehler aufgetreten, wird der ermittelte Wert der Funktion zurückgeliefert.
Strings
Ein weiterer sehr wichtiger Datentyp in Rust ist der String, der entsprechende Zeichenketten in Unicode abspeichert. Wie in anderen Programmiersprachen auch wird ein String in Anführungszeichen eingeschlossen. Sehen Sie sich dazu Listing 5 näher an.Listing 5: Strings in Rust
fn work_with_strings()
{
// A few simple string literals
let author = "Klaus Aschenbrenner";
let path = "c:\\Windows\\system32";
let rawString = r"c:\Windows\system32";
let largeString = "This very long string goes
over multiple lines - without any problems.";
// Declare a tuple, and generate a string
// out of it
let author = ("Klaus", "Vienna", 1980);
let formatted_string = format!("{} lives in {},
and is born in the year {}.",
author.0, author.1, author.2);
println!("{}", formatted_string);
// This string literal is allocated on the heap
let full_name =
"Klaus Aschenbrenner".to_string();
println!("{}", full_name);
// Define a string slice
let last_name = &full_name [6..];
println!("{}", last_name);
}
In den ersten Zeilen des Listings werden verschiedene String-Literale definiert. Wichtig ist hierbei zu wissen, dass diese String-Literale direkt im ausführbaren Programm abgelegt werden – nicht jedoch am Stack beziehungsweise am Heap. Im Falle von Linux werden diese Strings in der Section .rodata abgelegt. Diese Vorgehensweise macht Sinn, da sich die Größe von String-Literalen zur Laufzeit nicht ändern kann, da diese bereits zur Kompilierung feststehen.Wenn Sie spezifische Zeichen (wie zum Beispiel einen Backslash) in einem String aufnehmen möchten, können Sie diesen einerseits mit einer Escape-Sequenz versehen oder den String mit dem Präfix r definieren. Hierbei handelt es sich dann um einen sogenannten Raw-String, der auch Escape-Zeichen beinhalten kann, da diese seitens des Compilers einfach ignoriert werden.Wenn Sie bei einem String-Literal die Funktion to_string() aufrufen, wird der String als dynamisches Objekt auf dem Heap allokiert und kann dadurch zur Laufzeit auch entsprechend verändert werden. Über einen String Slice können Sie dann auch wiederum auf einen Teilbereich des Strings verweisen.In Listing 5 wurde der textuelle Inhalt der Variablen full_name am Heap allokiert, und die lokale Variable full_name (abgespeichert im aktuellen Stack Frame) verweist einfach auf die entsprechende Hauptspeicheradresse. Zusätzlich wird in der lokalen Variablen als weitere Information auch noch die Länge des Strings abgespeichert.Der String Slice last_name wird ebenfalls als lokale Variable innerhalb des aktuellen Stack Frame abgespeichert. Die Slice-Variable verweist auf die Hauptspeicheradresse, wo der String beginnt, und speichert zusätzlich wiederum auch die Länge des Slices ab. Daraus folgt auch, dass Strings in Rust nicht mit Nullen abgeschlossen werden – so wie zum Beispiel in C/C++.
Fazit
In diesem ersten Artikel der Serie über die Programmiersprache Rust haben Sie einen Einblick in die grundlegende Struktur von Rust-Programmen erhalten. Im ersten Schritt haben wir uns mit den Kernkonzepten, den Zielen und den Vorteilen von Rust beschäftigt.Darauf aufbauend haben Sie im nächsten Schritt Ihr erstes Rust-Programm implementiert und auch den Package Manager cargo näher kennengelernt. Im verbleibenden Teil des Artikels haben wir uns mit den verschiedenen Datentypen von Rust beschäftigt, wobei Sie auch gesehen haben, dass es hier große Unterschiede zu anderen Programmiersprachen wie C/C++ gibt.In der nächsten Folge dieser Serie werden wir uns näher mit Funktionen, Statements, Expressions und den Kontrollstrukturen in Rust beschäftigen.Fussnoten
- Mark Russinovich auf X (ehem. Twitter),
- Rust-Compiler und -Tools, Download, https://rustup.rs/
Inhalt









