
18. Mär 2019
Lesedauer 17 Min.
Rechnen mit CUDA
Vollgas mit der GPU, Teil 1
Schnellere Ergebnisse dank einer modernen Grafikkarte.

Das Rechnen auf einer Grafikkarte (GPU) oder einer speziellen Rechenkarte ist immer noch die „etwas andere Art, zu rechnen“. Es gibt verschiedene Bibliotheken, mit denen sehr schnelle Berechnungen auf einer Grafikkarte durchgeführt werden können.Angefangen hat alles im Jahr 2007 mit den CUDA-Bibliotheken des Grafikkartenherstellers Nvidia. CUDA, kurz für Compute Unified Device Architecture, bietet eine Möglichkeit, mathematische Algorithmen in einen speziellen Code zu übersetzen, der dann mit sehr vielen Threads auf einer Grafikkarte ausgeführt wird.In diesem Artikel soll die Benutzung der CUDA-Bibliotheken ausgehend von normalem C/C++-Code vorgestellt werden. Außerdem werden die Grundlagen der GPU-Programmierung vermittelt und die erforderlichen Werkzeuge beschrieben.In einem Desktop-Computer kann sowohl die CPU (Central Processing Unit) als auch die GPU zum Rechnen genutzt werden. Da in den Rechnern heute Mehrkernprozessoren mit in der Regel vier Prozessoren (Quad Core) eingebaut werden, lassen sich auf der CPU vier Threads starten und vier voneinander unabhängige Aufgaben ausführen. Auf einer GPU können jedoch mehrere Hundert oder mehrere Tausend Threads gestartet und parallel bearbeitet werden, wodurch man – bei geeigneter Aufgabenstellung – eine wesentlich höhere Ausführungsgeschwindigkeit erzielen kann.Vergleicht man die CPU mit einem Sportwagen und die GPU mit einem Lieferwagen, so bietet sich folgendes Beispiel an: Für einen Umzug sind 50 Kisten über 1 000 Kilometer zu transportieren. In den Sportwagen passen jeweils zwei Kisten, die er in fünf Stunden ans Ziel bringt. Der Sportwagen kommt dabei auf eine Leistung 0,4 Kisten/Stunde. Der Lieferwagen schafft dagegen alle 50 Kisten auf einmal, braucht dafür zwar 20 Stunden, kommt mit 2,5 Kisten/Stunde aber auf einen vielfach höheren Durchsatz. Wären dagegen nur vier Kisten zu transportieren, sähe die Rechnung anders aus.Man kann eine Grafikkarte also nicht für alle Berechnungen sinnvoll einsetzen, sondern muss zunächst prüfen, ob viele Datenwerte gleichzeitig und gleichartig verarbeitet werden können. Wenn dies der Fall ist, dann sind Sie bei der GPU sehr gut aufgehoben und können je nach Problem, Datenmenge und Grafikkarte durchaus enorme Performance-Steigerungen bis zum 1 000-Fachen erzielen.
Installation
In diesem Artikel geht es um die CUDA-Bibliotheken von Nvidia. Das bedeutet, dass Sie, um die Codebeispiele nachzuvollziehen, einerseits eine einigermaßen moderne Grafikkarte von Nvidia in Ihrem Rechner benötigen und andererseits das kostenlose CUDA-SDK aus dem Internet herunterladen und installieren müssen.Das Software Development Kit finden Sie unter [1] für die Betriebssysteme Microsoft Windows, Linux und macOS. Mit dem Toolkit werden alle benötigten Werkzeuge, Compiler, Editor-Erweiterungen und Bibliotheken installiert. Denken Sie auch daran, den neuesten Treiber für Ihre Grafikkarte zu installieren, um ein einwandfreies Arbeiten der CUDA-Komponenten sicherzustellen.Sie benötigen außerdem eine Entwicklungsumgebung. Unter Windows (Version 7, 8 oder 10) ist das meist Visual Studio ab Version 2015. Mit Visual Studio (VS) ist es möglich, CUDA-Anwendungen zu erstellen. Eine entsprechende Projektvorlage wird für die vorhandenen VS-Versionen installiert. Unter Linux oder macOS können die für diese Plattformen vorhandenen Entwicklungswerkzeuge benutzt werden.In diesem Artikel wird CUDA 9.1 (64 Bit) mit Microsoft Visual Studio 2015 unter dem Betriebssystem Microsoft Windows 10 (64 Bit) benutzt.Vorgehensweise mit CUDA
Wenn Sie auf der Grafikkarte etwas berechnen möchten, müssen Sie sowohl den Code für den Algorithmus als auch die benötigten Daten auf die GPU transferieren. Und hier ergibt sich das erste Problem in diesem Szenario: Die Übertragung großer Datenmengen kostet nämlich etwas Zeit. Bei den Beispielprogrammen, die mit dem CUDA-SDK installiert werden, ist das kleine Testprogramm bandwidthTest enthalten, welches die Übertragungsgeschwindigkeit für Ihren Rechner ermitteln kann. Diese liegt in der Regel zwischen 3 und 6 Gigabyte pro Sekunde.Die Menge der zu übertragenden Daten kann bei manchen Berechnungen sehr schnell anwachsen. Bei einer Matrixmultiplikation müssen zwei Arrays auf die Grafikkarte kopiert und anschließend das Ergebnis-Array zurück in den CPU-Speicher kopiert werden. Bei einer Matrix-Größe von 500 mal 500 Elementen in doppelter Genauigkeit (8 Byte) müssen insgesamt 6 Megabyte an Daten übertragen werden. Wenn mit diesen Daten nun nur wenige Rechenoperationen ausgeführt werden, benötigt die Datenübertragung mehr Zeit, als durch das parallele Ausführung des Algorithmus auf der GPU gewonnen wird.Das Übertragen des Programmcodes geht normalerweise sehr schnell, da es sich oft nur um einige Kilobyte handelt. Aber auch hier gibt es einen Haken: Bevor das Programm das erste Mal auf der GPU ausgeführt werden kann, muss der Code speziell für die Grafikkarte vorbereitet werden. Auch das kostet wieder Zeit. Dies bedeutet, dass der erste Aufruf eines GPU-Codes etwas länger dauert als der darauf folgende zweite Aufruf. Der allgemeine Ablauf einer Berechnung auf der GPU ist folgender:- Die GPU mit cudaSetDevice auswählen,
- den Speicher auf der GPU mit cudaMalloc bereitstellen,
- Daten mit cudaMemcpy auf die GPU kopieren,
- den Algorithmus auf der GPU ausführen,
- mit cudaDeviceSynchronize auf die GPU warten,
- die Ergebnisse der GPU mit cudaMemcpy zurückkopieren,
- den Speicher der GPU mit cudaFree wieder freigeben,
- die GPU mit cudaDeviceReset zurücksetzen.
Listing 1: Ein einfaches CUDA-Beispiel
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
// Code, der auf der GPU laufen soll
__global__ void addKernel(
int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
// Arrays auf dem Host
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Zeiger auf Arrays in der GPU
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
// GPU auswählen
cudaSetDevice(0);
// Speicher in der GPU anlegen
cudaMalloc((void**)&dev_c, arraySize * sizeof(int));
cudaMalloc((void**)&dev_a, arraySize * sizeof(int));
cudaMalloc((void**)&dev_b, arraySize * sizeof(int));
// Arrays a und b in die GPU kopieren
cudaMemcpy(dev_a, a, arraySize * sizeof(int),
cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, arraySize * sizeof(int),
cudaMemcpyHostToDevice);
// Code auf der GPU ausführen
addKernel <<<1, arraySize >>>(dev_c, dev_a, dev_b);
// Warten auf die GPU
cudaDeviceSynchronize();
// Ergebnis-Array auf den Host zurückkopieren
cudaMemcpy(c, dev_c, arraySize * sizeof(int),
cudaMemcpyDeviceToHost);
// Speicher auf der GPU freigeben
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
// Ausgabe der Ergebnisse
for (int i = 0; i < 5; i++)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
// GPU zurücksetzen
cudaDeviceReset();
return 0;
}
Es sei noch einmal darauf hingewiesen, dass in Listing 1 wegen der Übersichtlichkeit der gesamte Fehlerprüfcode weggelassen wurde. Wenn Sie das CUDA-Toolkit frisch auf Ihrem Rechner installiert haben, ist es sicherlich ratsam, zunächst einmal zwei oder drei Beispielprogramme aus dem Toolkit auszuführen, um die Korrektheit und Vollständigkeit der CUDA-Installation zu überprüfen.Im Beispielcode werden zunächst die wichtigen CUDA-Header-Dateien eingefügt. Danach wird die Funktion addKernel definiert, die den Code enthält, der auf der GPU ausgeführt werden soll. Diese Funktion muss mit dem Prefix __global__ eingeleitet werden, damit der Compiler diesen Code für die Ausführung auf der GPU vorbereitet. Der Funktionscode ist eigentlich sehr einfach, trotzdem gibt er uns ein Rätsel auf: Woher kommt die Variable threadIdx.x in der ersten Zeile der Funktion?Es handelt sich dabei um ein spezielle CUDA-Variable, die in der Header-Datei device_launch_parameter.h deklariert wird. Die Variable threadIdx.x stellt dem Entwickler eine eindeutige Nummer eines Threads zur Verfügung, in welchem der Funktionscode ausgeführt wird.Auf das Beispiel bezogen entsteht dann folgende Situation: Die Arrays a, b und c enthalten jeweils fünf Elemente. Die CUDA-Bibliothek erzeugt nun fünf Threads. Für den ersten Thread wird die Variable threadIdx.x auf den Wert 0 gesetzt, im zweiten Thread auf den Wert 1, und so weiter. Der fünfte Thread enthält in der Thread-spezifischen Variablen threadIdx.x den Wert 4. Da eine Grafikkarte fünf Threads problemlos gleichzeitig erzeugen und auch ausführen kann, erfolgt die Berechnung der fünf Ergebniswerte parallel – also gleichzeitig – in fünf GPU-Threads. In der zweiten Zeile der Funktion addKernel wird dieser Thread-Index benutzt, um die Elemente in den Arrays a, b und c anzusprechen.Die Datenübergabe an die Funktion addKernel erfolgt über ganz normale C-Zeiger. Es muss nun aber noch geklärt werden, wo diese Zeiger herkommen und wie die CUDA-Bibliothek erkennt, dass für das gezeigte Programm eben exakt fünf Threads benötigt werden, um das Ergebnis zu ermitteln. Dazu soll die main-Funktion des Beispiels etwas genauer betrachtet werden.Zuerst werden die drei erforderlichen C-Arrays deklariert und initialisiert. Dabei ist es wichtig zu verstehen, dass diese Arrays im normalen Arbeitsspeicher der CPU angelegt werden. Die Arrays a und b werden nicht verändert und können darum mit dem Attribut const versehen werden.Danach werden drei Integer-Zeiger angelegt und zunächst mit 0 initialisiert. Diese Zeiger werden in Kürze auf die Speicherbereiche zeigen, die für die Daten im Speicher der GPU angelegt werden.Als Nächstes wird eine CUDA-fähige Grafikkarte mit dem Befehl cudaSetDevice ausgewählt. In den meisten Fällen erübrigt sich diese Zeile, da es im Rechner oft nur eine solche Grafikkarte gibt. Diese wird von den CUDA-Bibliotheken dann automatisch benutzt.Jetzt werden die erforderlichen Speicherbereiche in der GPU mit cudaMalloc angelegt. Als Parameter wird die Adressvariable der jeweiligen Zeiger angegeben, die eben deklariert wurden. Zudem muss die gewünschte Größe des Speicherblocks übergeben werden. Die Funktion cudaMalloc legt den Speicherbereich im GPU-Speicher an und gibt die Position im Zeiger zurück. Allerdings ist hier etwas Vorsicht angesagt, denn in Listing 1 wird noch nicht überprüft, ob das Anlegen der Speicherblöcke erfolgreich war oder nicht. Der dazu erforderliche Code wird gleich im nächsten Beispiel vorgestellt.Im folgenden Schritt werden die Daten, die sich ja zunächst im CPU-Speicher in den Arrays a und b befinden, mithilfe der Funktion cudaMemcpy in den GPU-Speicher kopiert. Als Parameter werden Ziel- und Quellzeiger des Arrays sowie die Größe des Speicherblocks und die Kopierrichtung angegeben. Die Kopierrichtung kann mithilfe der Konstanten cudaMemcpyHostToDevice und cudaMemcpyDeviceToHost angegeben werden.Das Array c liegt zwar ebenfalls im Arbeitsspeicher der CPU und wurde mit 0 initialisiert, es wird aber nicht in die GPU kopiert, denn dieser Kopiervorgang wäre überflüssig und würde nur zusätzliche Zeit beanspruchen.Nun kommt im C-Quellcode wieder eine sehr sonderbare Zeile. Hier wird nun die Funktion addKernel aufgerufen und auf der GPU ausgeführt. Diese Kernel-Funktionen haben für CUDA die folgende Aufrufkonvention:
funcName <<<a, b>>>(params,...);
Der Aufruf beginnt mit dem Namen der Funktion (hier heißt sie addKernel), die bei der Implementierung mit dem Prefix __global__ gekennzeichnet wurde. Der Compiler-Treiber
nvcc von Nvidia kann diesen Aufruf auflösen. In den dreifachen spitzen Klammern können Compiler-Konstanten oder Variablen angegeben werden, die im Prinzip die Anzahl der Thread-Blöcke (im Beispiel: 1) und die Anzahl der Threads in einem Block (im Beispiel: arraySize) definieren. Diese beiden Angaben werden im Folgenden noch genauer erläutert. Am Ende des Statements übergeben Sie die Parameter für den Funktionsaufruf. Im gezeigten Beispiel sind das die Zeiger auf die drei Arrays, deren Speicher in der GPU liegt.Da der Aufruf der Kernel-Funktion addKernel asynchron ausgeführt wird, muss nun auf die Beendigung durch den blockierenden Aufruf von cudaDeviceSynchronize gewartet werden. Dann können Sie die Ergebnisdaten mit cudaMemcpy aus dem GPU-Speicher zurück in den Arbeitsspeicher der CPU kopieren. Danach können Sie auf den Inhalt des Arrays c zugreifen, das nun die Ergebnisse enthält.Abschließend ist noch eine sehr wichtige Aufgabe zu erledigen: Die auf der GPU allokierten Speicherblöcke müssen mit cudaFree wieder frei gegeben werden.Im letzten Teil des Beispielprogramms werden die Ergebnisse ausgegeben und schließlich mit der Funktion cudaDeviceReset alle Ressourcen aufgelöst, die in der GPU für diesen Prozess angelegt wurden.Die Datei mit dem besprochenen C-Code bekommt (von Visual Studio) den Namen kernel.cu. Das Projekt kann nun mit den Standardbefehlen von Visual Studio übersetzt und ausgeführt werden. Alternativ dazu können Sie das Programm mit dem Befehl nvcc auch aus der Kommandozeile heraus übersetzen.Wie schon mehrfach erwähnt, wurde im Listing jeglicher Code für die Fehlerprüfung weggelassen. Jede CUDA-Funktion liefert beim Aufruf einen Fehlerstatus in Form einer Variablen vom Typ cudaError_t zurück. Hat alles geklappt, enthält diese Variable den Wert cudaSuccess, ansonsten liefert sie einen Fehlercode.Ein CUDA-Aufruf wird dann im Prinzip immer mit dem Fehlerbehandlungscode aus Listing 2 erweitert. Beim Starten der Kernel-Funktion auf der GPU kann der Fehlerstatus mit der Funktion cudaGetLastError abgefragt werden. Die zu einem Fehlerstatus gehörende Meldung ermitteln Sie durch einen Aufruf von cudaGetErrorString. Tritt ein Fehler auf, müssen Sie den auf der GPU allokierten Speicher unbedingt wieder freigeben. Dies wird im Beispiel durch einen Sprung auf das Label Error gewährleistet. Hier sind natürlich auch andere Vorgehensweisen denkbar. Den grundsätzlichen Aufbau des Codes zeigt Listing 2.
nvcc von Nvidia kann diesen Aufruf auflösen. In den dreifachen spitzen Klammern können Compiler-Konstanten oder Variablen angegeben werden, die im Prinzip die Anzahl der Thread-Blöcke (im Beispiel: 1) und die Anzahl der Threads in einem Block (im Beispiel: arraySize) definieren. Diese beiden Angaben werden im Folgenden noch genauer erläutert. Am Ende des Statements übergeben Sie die Parameter für den Funktionsaufruf. Im gezeigten Beispiel sind das die Zeiger auf die drei Arrays, deren Speicher in der GPU liegt.Da der Aufruf der Kernel-Funktion addKernel asynchron ausgeführt wird, muss nun auf die Beendigung durch den blockierenden Aufruf von cudaDeviceSynchronize gewartet werden. Dann können Sie die Ergebnisdaten mit cudaMemcpy aus dem GPU-Speicher zurück in den Arbeitsspeicher der CPU kopieren. Danach können Sie auf den Inhalt des Arrays c zugreifen, das nun die Ergebnisse enthält.Abschließend ist noch eine sehr wichtige Aufgabe zu erledigen: Die auf der GPU allokierten Speicherblöcke müssen mit cudaFree wieder frei gegeben werden.Im letzten Teil des Beispielprogramms werden die Ergebnisse ausgegeben und schließlich mit der Funktion cudaDeviceReset alle Ressourcen aufgelöst, die in der GPU für diesen Prozess angelegt wurden.Die Datei mit dem besprochenen C-Code bekommt (von Visual Studio) den Namen kernel.cu. Das Projekt kann nun mit den Standardbefehlen von Visual Studio übersetzt und ausgeführt werden. Alternativ dazu können Sie das Programm mit dem Befehl nvcc auch aus der Kommandozeile heraus übersetzen.Wie schon mehrfach erwähnt, wurde im Listing jeglicher Code für die Fehlerprüfung weggelassen. Jede CUDA-Funktion liefert beim Aufruf einen Fehlerstatus in Form einer Variablen vom Typ cudaError_t zurück. Hat alles geklappt, enthält diese Variable den Wert cudaSuccess, ansonsten liefert sie einen Fehlercode.Ein CUDA-Aufruf wird dann im Prinzip immer mit dem Fehlerbehandlungscode aus Listing 2 erweitert. Beim Starten der Kernel-Funktion auf der GPU kann der Fehlerstatus mit der Funktion cudaGetLastError abgefragt werden. Die zu einem Fehlerstatus gehörende Meldung ermitteln Sie durch einen Aufruf von cudaGetErrorString. Tritt ein Fehler auf, müssen Sie den auf der GPU allokierten Speicher unbedingt wieder freigeben. Dies wird im Beispiel durch einen Sprung auf das Label Error gewährleistet. Hier sind natürlich auch andere Vorgehensweisen denkbar. Den grundsätzlichen Aufbau des Codes zeigt Listing 2.
Listing 2: Fehlerbehandlung
// ...
cudaError_t cudaStatus;
// ...
cudaStatus =
cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// ...
// Code auf GPU ausführen
addKernel<<<1, arraySize>>>(dev_c, dev_a, dev_b);
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "addKernel launch failed: %s\n",
cudaGetErrorString(cudaStatus));
goto Error;
}
// ...
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
// ...
Den kompletten Code des Beispiels inklusive Fehlerbehandlung können Sie sich ansehen, wenn Sie mit Visual Studio ein CUDA-Projekt erstellen und sich die Datei kernel.cu ansehen. Der CUDA-spezifische Code ist dort in der separaten Kernel-Funktion addWithCuda implementiert. Dort werden der Speicher auf der GPU angelegt, die Daten kopiert, der Kernel aufgerufen und die Ergebnisse zurück in den Arbeitsspeicher transferiert. Nach jedem CUDA-Aufruf folgt eine Prüfung, ob die Aktion erfolgreich war. Wird ein Fehler festgestellt, werden alle angelegten Speicherblöcke freigegeben und das Programm beendet.
Was kann meine GPU?
Bevor es um die Organisation der Threads auf der GPU geht, soll noch gezeigt werden, wie Sie die Möglichkeiten einer bestimmten Grafikkarte ermitteln. Die CUDA-Bibliothek bietet dazu die Funktion cudaGetDeviceProperties an. Deren Aufruf erfolgt mit einem Zeiger auf die Datenstruktur cudaDeviceProp und die Nummer der jeweiligen GPU. Ist im Rechner nur eine Grafikkarte für CUDA-Anwendungen und Grafikausgabe vorhanden, so wird 0 als Gerätenummer verwendet. Listing 3 demonstriert den Aufruf der Funktion cudaGetDeviceProperties.Listing 3: Ausgabe einiger GPU-Daten
#include <iostream>
#include <cuda_runtime.h>
int main()
{
int deviceCount = 0;
cudaError_t error_id =
cudaGetDeviceCount(&deviceCount);
if (error_id != cudaSuccess)
{
printf("Fehler Nr. %d\n-> %s\n",
(int)error_id, cudaGetErrorString(error_id));
exit(EXIT_FAILURE);
}
printf("\nEs wurde(n) %d CUDA-Grafikkarte(n)
gefunden.\n", deviceCount);
if(deviceCount == 0)
{
return 0;
}
int driverVersion = 0;
int runtimeVersion = 0;
// Schleife über alle gefundenen CUDA-Devices
for (int dev = 0; dev < deviceCount; ++dev)
{
cudaSetDevice(dev);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("\nDevice %d: \"%s\"\n\n", dev,
deviceProp.name);
cudaDriverGetVersion(&driverVersion);
cudaRuntimeGetVersion(&runtimeVersion);
printf(" CUDA Driver Version / Runtime Version:
%d.%d / %d.%d\n", driverVersion / 1000, (driver
Version % 100) / 10, runtimeVersion / 1000,
(runtimeVersion % 100) / 10);
printf(" CUDA Capabilities:
%d.%d\n", deviceProp.major, deviceProp.minor);
printf(" Groesse des globalen Speichers:
%llu Bytes\n", deviceProp.totalGlobalMem);
printf(" Anzahl der Multiprozessoren:
%3d\n", deviceProp.multiProcessorCount);
printf(" GPU Taktfrequenz:
%.0f MHz\n", deviceProp.clockRate * 1e-3f);
printf(" Max. Anzahl der Threads / MP:
%d\n", deviceProp.maxThreadsPerMultiProcessor);
printf(" Max. Anzahl der Threads / Block:
%d\n", deviceProp.maxThreadsPerBlock);
printf(" Groesse des Konstanten-Speichers:
%lu Bytes\n", deviceProp.totalConstMem);
printf(" Groesse des Shared Speichers / Block:
%lu Bytes\n\n", deviceProp.sharedMemPerBlock);
}
return 0;
}
Außerdem werden die Version des aktuell installierten Treibers und die Version der vorhandenen CUDA-Runtime ermittelt und ausgegeben. Im Anschluss daran listet die Funktion verschiedene Datenwerte aus der Struktur cudaDeviceProp auf dem Bildschirm. Im Beispiel handelt es sich nur um die allerwichtigsten Werte.Nach den Versionsnummern werden die sogenannten Compute Capabilities [2] ausgegeben. Dieser Wert gibt an, welche Möglichkeiten die GPU anbietet. Moderne Grafikkarten haben hier eine Versionsnummer größer als 5.x. Ältere Grafikkarten können natürlich auch noch mit CUDA benutzt werden. In diesen Fällen stehen aber die jüngeren Erweiterungen der CUDA-Bibliotheken nicht zur Verfügung.Die für Ihre Anwendung erforderlichen Compute Capabilities können Sie in den Eigenschaften des Visual-Studio-Projekts angeben und bei der Übersetzung entsprechend berücksichtigen.Danach werden die Größe des GPU-Speichers und die Anzahl der auf der Grafikkarte vorhandenen Multiprozessoren ausgegeben. Jeder der Prozessoren kann eine bestimmte Anzahl von Threads parallel ausführen. Wie groß die Anzahl der Threads ist, hängt von der Architektur der Grafikkarte ab. In aktuellen Nvidia-Grafikkarten findet man 64, 128 oder 192 Threads pro Multiprozessor. Schließlich folgt die Ausgabe der GPU-Taktfrequenz. Alle weiteren Angaben werden später noch genauer betrachtet.
Organisation der GPU-Threads
Die auf der GPU laufenden Threads werden in Grids und Blöcken organisiert (Bild 1). Alle Threads, die von einem Prozessorkern gleichzeitig gestartet werden, sind in einem Grid angeordnet. Diese Threads benutzen alle gemeinsam den gleichen globalen Speicher. Ein Grid wird aus Thread-Blöcken aufgebaut. Die Threads eines Blocks können interagieren, das heißt, die Threads lassen sich synchronisieren und alle Threads benutzen den Speicherbereich des jeweiligen Blocks gemeinsam (Shared Memory). Die Nummer eines Blocks im Grid wird durch die Variable blockIdx angegeben. Die Nummer eines Threads im Block wird mit der Variablen threadIdx angegeben, beide haben Sie bereits im ersten Beispielprogramm kennengelernt.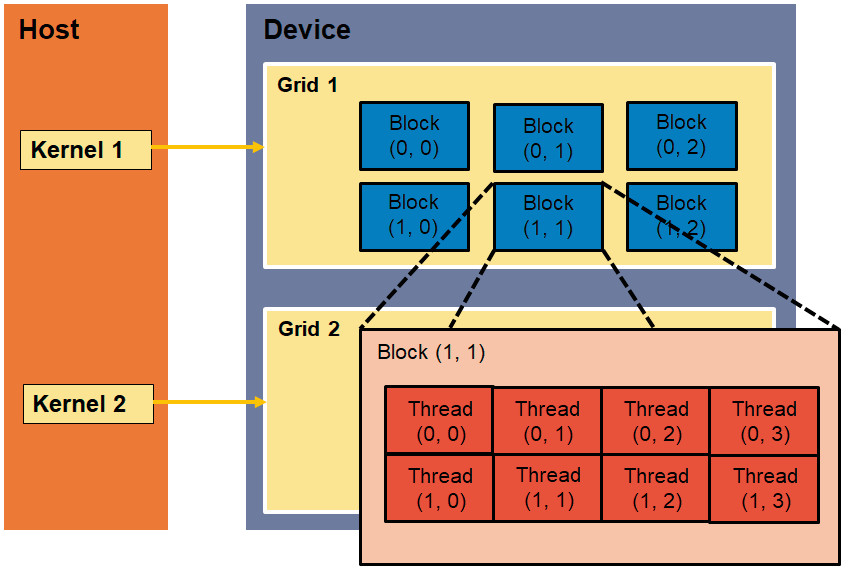
Die Architekturvon Grids, Blöcken und Threads(Bild 1)
Autor
Die Variablen blockIdx und threadIdx sind Vektoren, die aus drei vorzeichenlosen Integer-Variablen bestehen:
- blockIdx.x, blockIdx.y, blockIdx.z sowie
- threadIdx.x, threadIdx.y, threadIdx.z.
- blockDim.x, blockDim.y, blockDim.z.
threadNummer = blockIdx.x * blockDim.x + threadIdx.x
Die Variable blockDim.x enthält dann die Zahl 10 und die Variable threadIdx.x läuft von 0 bis 9 für jeden Block.Nun folgt ein genauerer Blick auf den Aufruf der Kernel-Funktion mit den drei spitzen Klammern. Die dort angegebenen Zahlen kontrollieren nämlich die Anzahl der Blöcke und die Anzahl der Threads pro Block. In Listing 1 wurden hier einfache Integer-Zahlen angegeben, da das Thread-Arrangement nur eindimensional war. Da die Blöcke und Threads aber auch einen zwei- oder dreidimensionalen Aufbau haben können, gibt es in den CUDA-Bibliotheken eine spezielle Struktur für diese Parameter namens dim3. Diese Struktur enthält drei vorzeichenlose Integer-Variablen, um jeweils die Größen in x-, y- und z-Richtung für die Blöcke im Grid und für die Threads im Block aufzunehmen. Der Aufruf eines Kernels kann dann folgendermaßen aussehen:
// ...
// Block-Größe (hier eindimensional)
dim3 block(5);
// Grid-Größe (hier eindimensional)
dim3 grid(arraySize / 5);
// Kernel aufrufen
callKernel <<<grid, block>>> ();
// ...
Die Aufteilung der Threads und Blöcke ist in manchen Fällen mit etwas Ausprobieren verbunden, um die größte Performance bei der Kernel-Ausführung zu erzielen.
Die Matrixmultiplikation
Die Matrixmultiplikation ist ein relativ einfacher und überschaubarer Algorithmus, der aber dennoch in Wissenschaft und Technik von enormer Wichtigkeit ist. Dieser Algorithmus soll nun für die normale CPU und zum Vergleich mit CUDA für die GPU implementiert werden. Bei diesem Beispiel wird auch der Performancegewinn beobachtet. Standardalgorithmus für das Multiplizieren zweier quadratischer Matrizen (oder Arrays) sind drei ineinandergeschachtelte Schleifen. Das Ergebnis ist ein Array. Angenommen es gibt die drei gleich großen Arrays a, b und c, wobei c das Ergebnis-Array sein soll. Die Arrays haben jeweils die Größe n * n. Dann sieht der Code so aus:
// Arrays deklarieren und initialisieren
for(int i = 0; i < n; i++)
{
for(int j = 0; j < n; j++)
{
for(int k = 0; k < n; k++)
{
c[i,j] += a[i,k] * b[k,j];
}
}
}
Diese sehr einfache Implementierung funktioniert recht gut für kleine Arrays, die in den 1st-Level-Cache der CPU passen. Bei großen Arrays wird der Algorithmus allerdings überproportional langsamer. Man kann allgemein sagen: Verdoppelt man die Kantenlänge n der drei Arrays, so muss theoretisch achtmal soviel gerechnet werden. Bei sehr großen Arrays wird man aber wesentlich längere Rechenzeiten finden, da die benötigten Daten nicht mehr im Cache gehalten werden können.In Listing 4 finden Sie eine einfache Matrixmultiplikation sowohl für die Ausführung auf einer CPU als auch auf der GPU mit CUDA.
Listing 4: Einfache Matrixmultiplikation (Teil 1)
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <time.h>
#define BLOCK_WIDTH 32
cudaError_t cudaMethod(float* a, float* b,
float* c, int n);
int cpuTest(float* a, float* b, float* c, int n);
__global__ void matMultKernel(float* d_a, float* d_b,
float* d_c, int n)
{
int iCol = blockIdx.x * blockDim.x + threadIdx.x;
int iRow = blockIdx.y * blockDim.y + threadIdx.y;
// Was zu groß ist, wird nicht gerechnet!
if ((iRow < n) && (iCol < n))
{
float sum = 0.0f;
for (int k = 0; k < n; k++) {
sum += d_a[iRow * n + k] * d_b[k * n + iCol];
}
d_c[iRow * n + iCol] = sum;
}
}
int main()
{
double start, ende; // für Zeiten
const int n = 1024; // Array-Größe
int iRet;
float* a = new float[n * n];
float* b = new float[n * n];
float* c = new float[n * n];
// Arrays initialisieren
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
int ind = i * n + j;
a[ind] = (float)(i + j);
b[ind] = (float)(i - j + 1);
c[ind] = 0.0f;
}
}
// Auf der CPU rechnen
//start = clock();
//iRet = cpuTest(a, b, c, n);
//ende = clock() - start;
// Kernel einmal vorübersetzen
iRet = cudaMethod(a, b, c, n);
// Auf der GPU rechnen
start = clock();
iRet = cudaMethod(a, b, c, n);
ende = clock() - start;
// Fehler und Zeit ausgeben
if (iRet == 0)
printf("Kein Fehler.\n");
else
printf("Error!!!!\n");
printf("Zeit: %.3f msek\n", ende);
cudaDeviceReset();
return 0;
}
cudaError_t cudaMethod(float* a, float* b,
float* c, int n)
{
float *d_a = 0;
float *d_b = 0;
float *d_c = 0;
cudaError_t cudaStatus;
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) goto Error;
// Speicher allokieren
cudaStatus = cudaMalloc((void**)&d_c, n * n * sizeof(float));
if (cudaStatus != cudaSuccess) goto Error;
cudaStatus = cudaMalloc((void**)&d_a,
n * n * sizeof(float));
if (cudaStatus != cudaSuccess) goto Error;
cudaStatus = cudaMalloc((void**)&d_b,
n * n * sizeof(float));
if (cudaStatus != cudaSuccess) goto Error;
// Daten kopieren
cudaStatus = cudaMemcpy(d_a, a,
n * n * sizeof(float), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) goto Error;
cudaStatus = cudaMemcpy(d_b, b,
n * n * sizeof(float), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) goto Error;
// Grid- und Blockgröße ermitteln
int nBlocks = n / BLOCK_WIDTH;
if (n % BLOCK_WIDTH != 0)
nBlocks++;
// Kernel aufrufen
dim3 dimGrid(nBlocks, nBlocks, 1);
dim3 dimBlock(BLOCK_WIDTH, BLOCK_WIDTH, 1);
matMultKernel <<< dimGrid, dimBlock >>>(d_a,
d_b, d_c, n);
// Warten, bis Kernel fertig ist
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) goto Error;
// Ergebnis kopieren
cudaStatus = cudaMemcpy(c, d_c,
n * n * sizeof(float), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) goto Error;
// Speicher freigeben
cudaFree(d_c);
cudaFree(d_a);
cudaFree(d_b);
return cudaStatus;
Error:
cudaFree(d_c);
cudaFree(d_a);
cudaFree(d_b);
return cudaStatus;
}
int cpuTest(float* a, float* b, float* c, int n)
{
// Einfache Matrixmultiplikation
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
float sum = 0.0f;
for (int k = 0; k < n; k++)
{
sum += a[i * n + k] * b[k * n + j];
}
c[i * n + j] = sum;
}
}
return 0;
}
Das Beispiel beginnt nach den Header-Dateien wieder mit der Kernel-Funktion matMultKernel. Da hier mit quadratischen Arrays gerechnet wird, ist es sinnvoll, auch zweidimensionale Indizes für die Threads zu benutzen. Aus dem Block-Index blockIdx und dem Thread-Index threadIdx werden dann die Indizes für Zeile und Spalte errechnet, die anschließend in der Schleife mit der Laufvariablen k multipliziert und summiert werden.Die main-Methode arbeitet genauso wie in den vorhergehenden Beispielen: Daten bereitstellen, Speicher anlegen, Daten kopieren, Kernel aufrufen, Ergebnisse kopieren.Es lohnt sich den Kernel-Aufruf genauer anzuschauen: Ganz am Anfang des Beispielprogramms wurde der Platzhalter BLOCK-WIDTH auf den Wert 32 gesetzt. Die Arrays bestehen aus n Zeilen und Spalten. Sind die Arrays sehr groß (im Beispiel: 1 024 * 1 024 Elemente), kann die Berechnung nicht in einem einzigen Thread-Block ausgeführt werden, denn in einem Block sind üblicherweise nur 1 024 Threads erlaubt. Man muss also mehrere Blöcke verwenden. In der Variablen nBlocks wird die Anzahl der benötigten Blöcke in horizontaler und vertikaler Richtung berechnet und abgelegt. Das heißt, für die Berechnung werden nBlocks * nBlocks Thread-Blöcke benutzt. Jeder Thread-Block wiederum enthält BLOCK_WIDTH * BLOCK_WIDTH Threads. Mit diesen Informationen wird nun die Kernel-Funktion aufgerufen. In diesem Zusammenhang ist es nicht ganz unwichtig, in der Kernel-Funktion mit einem if-Statement zu prüfen, ob die benutzen Werte für Zeile und Spalte immer kleiner als n sind. Wenn n %BLOCK_WIDTH nämlich nicht null ist, wird nBlocks um eins erhöht.In den äußeren Blöcken können dann aber nicht alle Threads mit sinnvollen Daten rechnen. Diese Thread-Indizes werden durch den if-Befehl ignoriert.Das Beispiel in Listing 4 enthält auch normalen C-Code, um die Matrixmultiplikation auf der CPU in einem einzigen Thread auszuführen. In der main-Methode ist dieser Code als Kommentarzeilen eingebaut. Dieser Teil kann bei Bedarf zum Zeitvergleich aktiviert werden.Die Zeiten für die CUDA-Berechnung werden inklusive der erforderlichen Datenübertragungszeiten in und aus der GPU gemessen.Weiterhin wird beim CUDA-Aufruf der Kernel zweimal ausgeführt. Der zweite Aufruf ist normalerweise schneller, denn der Code muss nicht mehr für die Ausführung auf der GPU vorbereitet werden.Die Zeitmessung erfolgt mit der einfachen C-Funktion clock(), die in der Datei time.h deklariert ist. Unter Windows liefert die Funktion Millisekunden zurück. Unter Linux liefert diese Funktion die Zeit in Mikrosekunden zurück.Ein Zeitvergleich der CPU- und der CUDA-Implementierung ergibt für eine 1 024 * 1 024-Matrix ein deutliches Ergebnis:
CPU : 6,396 Sekunden,
CUDA: 0,044 Sekunden
Die CUDA-Routine ist also etwa 145-mal so schnell wie der Code auf der CPU. Allerdings muss man natürlich erwähnen, dass man den CPU-Code ebenfalls parallelisieren und entsprechend kürzere Rechenzeiten erhalten kann – zum Beispiel mit OpenMP.Der Code aus dem zuletzt gezeigten Beispiel ist aber noch nicht optimal. Man kann das noch etwas schnellere Shared Memory für die Berechnungen nutzen (Bild 2). Allerdings ist dieser Speicherbereich begrenzt und die drei Arrays passen nicht komplett hinein. Die wichtigsten Änderungen für den Einsatz des schnelleren Speichers finden Sie in Listing 5.
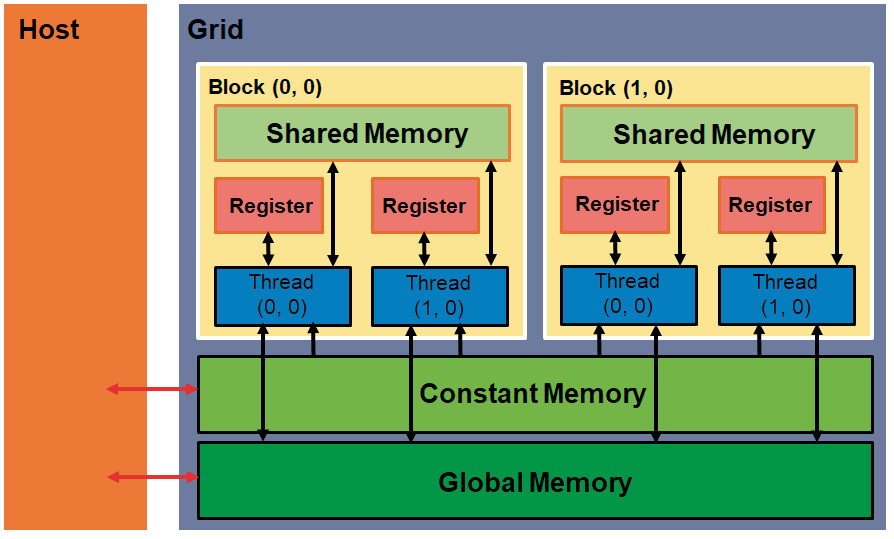
Architekturdes GPU-Speichers(Bild 2)
Autor
Listing 5: Verbesserte Matrixmultiplikation
__global__ void matMultKernel(float* d_a,
float* d_b, float* d_c, int n)
{
// Hilfsarrays im schnellen Speicher
__shared__ float ads[TILE_WIDTH][TILE_WIDTH];
__shared__ float bds[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int iRow = by * TILE_WIDTH + ty;
int iCol = bx * TILE_WIDTH + tx;
float sum = 0.0f;
// Hilfsarrays mit Daten füllen
for (int m = 0; m < n / TILE_WIDTH; m++) {
ads[ty][tx] =
d_a[iRow * n + m * TILE_WIDTH + tx];
bds[ty][tx] =
d_b[(m * TILE_WIDTH + ty) * n + iCol];
__syncthreads();
// Multiplikation
for (int k = 0; k < TILE_WIDTH; k++) {
sum += ads[ty][k] * bds[k][tx];
}
__syncthreads();
}
d_c[iRow * n + iCol] = sum;
}
In dieser Variante werden Teile der GPU-Arrays d_a und d_b in das schnellere Shared Memory kopiert, dann wird die Multiplikation mit den kleinen Hilfs-Arrays ausgeführt und die Ergebnisse werden an die richtige Stelle im Ergebnis-Array d_c kopiert. Dabei müssen die Threads aber an zwei Stellen mit syncthreads() synchronisiert werden. Beim ersten Aufruf wird sichergestellt, dass alle erforderlichen Daten in die kleinen Arrays kopiert wurden. Beim zweiten Aufruf sollten dann alle Multiplikationen ausgeführt sein, und das Ergebnis kann korrekt im Ziel-Array abgelegt werden.Statt des Platzhalters BLOCK_WIDTH wird nun der Name TILE_WIDTH benutzt. Dies muss auch in der main-Funktion entsprechend angepasst werden. Setzt man die TILE_WIDTH im Beispiel auf die Werte 4, 8, 16 oder 32 und misst die Ausführungszeiten, so stellt man fest, dass die Zeiten mit einer größeren TILE_WIDTH besser werden. Je größer TILE_WIDTH ist, desto mehr Rechenoperationen können mit den kleinen Arrays pro Kopiervorgang durchgeführt werden. Bei einem Wert von 32 ist jedoch Schluss, da ein Block nur 1 024 (also 32 * 32) Threads ausführen kann.Mit einer TILE_WIDTH von 32 wurde eine Rechenzeit von 0,016 Sekunden gemessen, das ist also noch einmal fast dreimal schneller als die Variante aus Listing 4. Diese Werte variieren von Rechner zu Rechner. Einen besonderen Einfluss hat sicherlich die Grafikkarte. Je mehr CUDA-Kerne zur Verfügung stehen, desto kürzer sind die Rechenzeiten.
Zusammenfassung
Durch die Berechnungen auf der GPU können Sie bestimmte Code-Teile einer Anwendung deutlich beschleunigen. Dafür müssen jedoch einige Bedingungen erfüllt werden:- Die Datenmengen, die in die GPU kopiert werden müssen, dürfen nicht zu groß sein.
- Mit den kopierten Daten müssen möglichst viele Rechenoperationen ausgeführt werden.
- Die Daten müssen möglichst in der gleichen Weise verarbeitet werden.
- Der Rechenalgorithmus muss an die Grafikhardware angepasst werden, um optimale Performance-Steigerungen zu erzielen.
Fussnoten
- CUDA-Download,
- CUDA (Wikipedia),










