
16. Okt 2023
Lesedauer 16 Min.
MongoDB + .NET – ein Traumpaar
Best Practices für NoSQL
Wie Sie mit den richtigen Patterns und Best Practices in .NET ein langfristig erweiterungsfähiges Datenmodell mit MongoDB umsetzen.

Die zunehmende Komplexität moderner Anwendungen hat zu einer breiten Vielfalt von Datenbanktechnologien geführt, die den unterschiedlichen Anforderungen gerecht werden sollen. In diesem Kontext hat MongoDB, eine führende NoSQL-Datenbank, aufgrund ihrer Flexibilität und Skalierbarkeit viel Aufmerksamkeit erregt. Insbesondere für .NET-Entwickler bietet MongoDB eine robuste Plattform zur Speicherung und Verwaltung von Daten in nichtrelationalen Formaten. Dieser Fachartikel widmet sich der nahtlosen Integration von MongoDB in .NET-Applikationen und präsentiert bewährte Methoden für den erfolgreichen Einsatz.Traditionelle relationale Datenbanken haben jahrzehntelang die Datenlandschaft dominiert, jedoch stoßen sie inzwischen an Grenzen, wenn es um die Speicherung und Verarbeitung großer Datensätze und deren flexible Erweiterung geht. Hier bieten NoSQL-Datenbanken eine flexible und skalierbare Alternative. MongoDB als dokumentenorientierte NoSQL-Datenbank ermöglicht die Speicherung von Daten in Form von Dokumenten, wodurch komplexe Hierarchien und sich ändernde Strukturen leichter bewältigt werden können.Die Integration von MongoDB in .NET-Anwendungen eröffnet Entwicklern neue Möglichkeiten, Daten effizient zu verwalten und skalierbare Anwendungen zu erstellen. Durch die intuitiv aufgebauten SDKs und durch das Zusammenspiel von MongoDB und .NET können Entwicklungsteams auf einfache Weise von den Vorteilen der NoSQL-Technologie profitieren, ohne dabei auf die gewohnten Funktionen und Strukturen von .NET verzichten zu müssen.
MongoDB als Allzweckwaffe
MongoDB hat sich als eine der prominentesten NoSQL-Datenbanken etabliert und erfreut sich großer Beliebtheit in der Softwareentwicklung, insbesondere im Kontext von .NET-Anwendungen. In diesem Abschnitt werfen wir einen näheren Blick auf MongoDB, beleuchten die Unterschiede zwischen dokumentenorientierten Datenbanken und relationalen Datenbanken und tauchen in die zugrunde liegenden NoSQL-Konzepte ein, die MongoDB zu einer leistungsfähigen Alternative machen.Dokumentenorientierte Datenbanken versus relationale Datenbanken
Traditionelle relationale Datenbanken sind seit Jahrzehnten das Rückgrat vieler Unternehmensanwendungen. Sie verwenden Tabellen, Schemata und Beziehungen, um Daten zu speichern und auf sie zuzugreifen.Dokumentenorientierten Datenbanken wie MongoDB verfolgen eine andere Herangehensweise. Hier werden Daten in flexiblen Dokumenten gespeichert, die in JSON-ähnlichen Formaten vorliegen. Im Vergleich zu Tabellen bieten Dokumente eine natürliche Möglichkeit, Daten darzustellen, da sie hierarchische Strukturen und komplexe Datentypen besser unterstützen.Ein wesentlicher Vorteil von dokumentenorientierten Datenbanken liegt in ihrer Flexibilität. Anders als in relationalen Schemata sind keine festen Tabellenstrukturen oder vordefinierten Spalten erforderlich. Dies ermöglicht eine einfache und organische Entwicklung, bei der Datenstrukturen sich an die Anforderungen der Anwendung anpassen können, ohne dass umfangreiche Datenbankmigrationen notwendig sind (vergleiche Bild 1).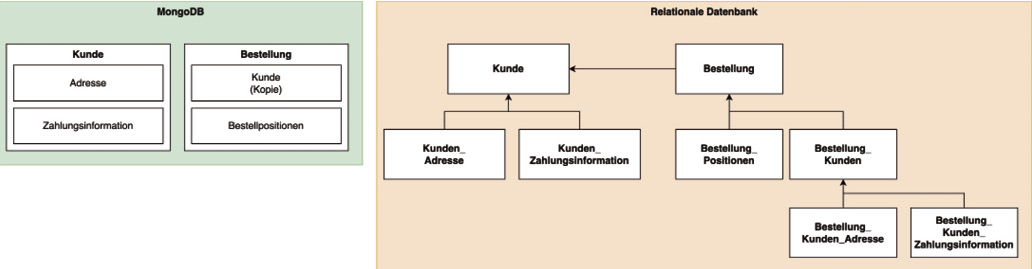
Collection-/Tabellen-Schema inklusive der versionierten Kunden im Fall von Bestellungen (Bild 1)
Autor
Eingesetzte Konzepte
MongoDB basiert auf grundlegenden NoSQL-Konzepten, die es von traditionellen relationalen Datenbanken unterscheiden. Diese Konzepte sind essenziell für das Verständnis der Arbeitsweise dieses Systems und wie es Daten speichert.Der Übergang von den starren Strukturen relationaler Datenbanken zu den flexibleren Ansätzen dokumentenorientierter NoSQL-Datenbanken erfordert eine Anpassung des Denkens, eröffnet jedoch gleichzeitig Möglichkeiten für eine agilere Entwicklung und eine bessere Anpassung an sich ändernde Anforderungen.MongoDB in .NET einsetzen
Die nahtlose Integration von MongoDB in .NET-Anwendungen eröffnet Softwareentwicklern die Möglichkeit, die Flexibilität einer dokumentenorientierten Datenbank in Kombination mit den umfangreichen Möglichkeiten des .NET Frameworks zu nutzen.Der offizielle MongoDB-.NET-Treiber ist das zentrale Bindeglied zwischen der .NET-Anwendung und der MongoDB-Datenbank. Er bietet eine umfassende Palette von Funktionen, die speziell auf die Integration von MongoDB mit .NET abgestimmt sind. Die Funktionalitäten des Treibers erstrecken sich von der einfachen Durchführung von CRUD-Operationen bis hin zur Unterstützung komplexer Aggregationen und Transaktionen. Hierbei nutzt man entweder direkte Datenbankaufrufe oder kann die gesamte Datenbankstruktur auf Basis des eigenen Klassenmodells aufbauen.Gerade dieser Faktor wird eine große Arbeitserleichterung bei dem Umgang mit den dokumentenorientierten Datenmodellen sein. Das gesamte Modell kann als einfaches Klassenmodell aufgebaut werden, ohne dass OR-Mapper die einzelnen Strukturen in normalisierte Tabellenstrukturen umwandeln müssen. Mittels Standard-Attributen aus .NET sowie gesonderten Attributen für MongoDB können Verhaltensweisen, Fallback-Verhalten (Migrationen), Indizes und vieles mehr ganz einfach im Klassenmodell definiert werden.Installation und Einrichtung des Treibers
Die Installation des MongoDB-.NET-Treibers ist unkompliziert und erfolgt am besten über den Paketmanager NuGet, der fester Bestandteil des .NET-Ökosystems ist. Hierzu kann die NuGet-Konsole oder das NuGet-Paketmanager-Tool in Visual Studio verwendet werden. Der Befehl Install-Package MongoDB.Driver lädt den Treiber samt seiner Abhängigkeiten herunter und fügt sie dem Projekt hinzu.Nach der Installation kann der Treiber über den using-Befehl in Ihren C#-Dateien eingebunden werden:
using MongoDB.Driver;
Die Einrichtung des Treibers erfordert meist keine weitere Konfiguration, da er die Verbindungsinformationen zur MongoDB-Datenbank aus einer Verbindungszeichenfolge liest.
Connection erstellen und verbinden
Diese Zeichenfolge ist jedoch etwas anders aufgebaut als die aus den SQL-Servern bekannten Connection-Strings. Ein MongoDB-Connection-String beinhaltet ebenso den Host, Port, Datenbank und gegebenenfalls Benutzerinformationen, deren Aufbau basiert jedoch auf einem URL.
mongodb://localhost:27017
Dies wäre die Verbindung auf eine einzelne MongoDB-Instanz ohne Credentials. Hat man jedoch für den Produktivbetrieb einen MongoDB-Cluster (meist ein Replica-Set) eingerichtet, so existieren mindestens drei Server-Instanzen. Der entsprechende Connection-String lautet in diesem Fall wie folgt:
mongodb://server1.local:27017, server2.local:27017,
server3.local:27017/?replicaSet=myReplicaSetName
Wie man an diesem Connection-String bereits sehen kann, stellt sich der Aufbau eines redundanten Clusters in MongoDB als sehr einfach heraus und sollte demnach als Best Practice für den produktiven Einsatz gelten.Um eine Verbindung zur MongoDB-Datenbank herzustellen, verwenden Sie den MongoClient aus dem MongoDB-
.NET-Treiber. Der MongoClient ist verantwortlich für das Herstellen und Verwalten der Verbindung. Hier ein einfaches Beispiel, wie eine Verbindung aufgebaut wird:
.NET-Treiber. Der MongoClient ist verantwortlich für das Herstellen und Verwalten der Verbindung. Hier ein einfaches Beispiel, wie eine Verbindung aufgebaut wird:
string connectionString = "mongodb://localhost:27017";
var client = new MongoClient(connectionString);
Die Variable connectionString enthält den passenden Connection-String des MongoDB-Servers. Nach dem Aufbau der Verbindung kann der Datenbankzugriff über die Datenbank- und Sammlungsobjekte erfolgen. Hier ein Beispiel, wie auf eine bestimmte Datenbank und Sammlung zugegriffen wird:
var database = client.GetDatabase("UserDatabase");
var collection = database.GetCollection<BsonDocument>(
"UserCollection");
In diesem Beispiel werden die Datenbank UserDatabase und die Sammlung UserCollection ausgewählt.Der Typ BsonDocument stellt das Standardformat für Dokumente in MongoDB dar. Im weiteren Verlauf werden wir jedoch eigene Klassen als objektorientierte Strukturen hierfür nutzen. Sollte es nicht ersichtlich sein, wie die Daten in der zugrunde liegenden Collection aufgebaut sind, eignen sich BsonDocuments, um generisch auf Daten zugreifen zu können. Teils sind diese für die Manipulation von partiellen Daten und die Erstellung von Aggregationen hilfreich und werden insbesondere dort eingesetzt.
Datenmodellierung in .NET für NoSQL-Systeme
Bei der Gestaltung von Datenbanken steht das Schema-Design an vorderster Front, denn es beeinflusst nicht nur die Art und Weise, wie Daten gespeichert werden, sondern auch, wie effizient auf sie zugegriffen werden kann. MongoDB verfolgt in Bezug auf Schema-Design einen Ansatz, der sich grundlegend von traditionellen relationalen Datenbanken unterscheidet. In diesem Abschnitt werfen wir einen genaueren Blick darauf, wie sich das Schema-Design in MongoDB von relationalen Datenbanken abhebt und welche Vor- und Nachteile diese Herangehensweise für .NET-Entwickler bietet.Ein Schlüsselfeature von MongoDB beziehungsweise von objekt- oder dokumentenorientierten Datenbanken generell liegt in der Fähigkeit, flexible Datenschemata zu unterstützen, die dennoch eine sinnvolle Struktur beibehalten. Im Gegensatz zu relationalen Datenbanken, die feste Tabellen und vordefinierte Spalten erfordern, können in MongoDB Dokumente mit unterschiedlichen Feldern in derselben Sammlung gespeichert werden. Diese Flexibilität ermöglicht es Entwicklern, Daten dynamisch hinzuzufügen oder zu ändern, ohne das gesamte Schema anpassen zu müssen (Bild 2).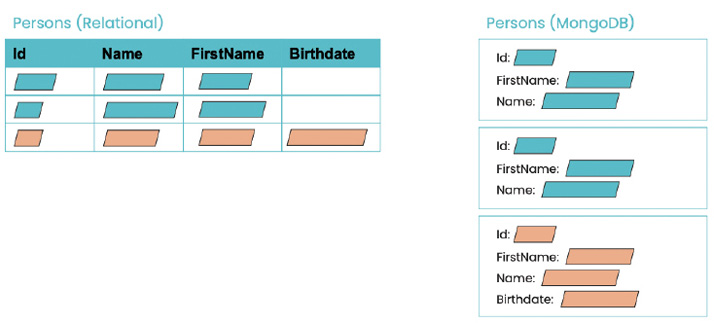
Beispiel einer Schema-Änderung (orange Inhalte). Relational gegenüber MongoDB (Bild 2)
Autor
Nehmen wir an, Sie entwickeln eine Blog-Plattform. In einer relationalen Datenbank würden Sie vielleicht eine Tabelle für Autoren und eine andere für Artikel erstellen, wobei jede Tabelle eine vordefinierte Anzahl von Spalten hat. In MongoDB könnte man hingegen alle Autoreninformationen und Artikel in einer Sammlung speichern. Autoren können unterschiedliche Felder haben, je nachdem, welche Informationen vorhanden sind. Dies ermöglicht es, auf natürliche Weise mit variablen Daten umzugehen, ohne leere Felder oder komplexe JOIN-Operationen zu verwenden. Dies bringt zum einen eine bis dato unerreichte Flexibilität und einfache Updates, aber auch eine wesentlich höhere Performance, da Mehrfachanfragen und Aggregationen auf ein Minimum beschränkt werden können.
Hierarchie oder Referenz?
Ein weiteres wichtiges Konzept im Schema-Design von MongoDB betrifft die Verwendung von eingebetteten Dokumenten (Embedded Documents) im Vergleich zu referenzierten Dokumenten (Referenced Documents). In relationalen Datenbanken werden Beziehungen zwischen Tabellen über Fremdschlüssel hergestellt. In MongoDB können Sie Dokumente jedoch direkt in andere Dokumente einbetten, was die Datenaggregation und -abfrage vereinfacht.Stellen Sie sich vor, Sie entwickeln eine E-Commerce-Anwendung. In einer relationalen Datenbank würden Sie vielleicht separate Tabellen für Produkte und Kunden haben, die über eine Kunden-ID verknüpft sind. In MongoDB könnten Sie stattdessen die Kundeninformationen direkt in das Bestellungs-Dokument einbetten. Das ermöglicht Ihnen, eine Bestellung inklusive Kundeninformationen in einem einzigen Dokument abzurufen, was die Ladezeiten und Abfragen beschleunigen kann.Allerdings ist es wichtig zu beachten, dass übermäßiges Einbetten von Dokumenten zu einer erhöhten Datenredundanz führen kann, insbesondere wenn die gleichen Informationen in mehreren Dokumenten wiederholt werden. In solchen Fällen kann es sinnvoller sein, auf referenzierte Dokumente zurückzugreifen, um Datenkonsistenz zu gewährleisten und den Speicherplatz effizient zu nutzen.Um die Unterschiede zwischen eingebetteten und referenzierten Dokumenten im Schema-Design von MongoDB zu verdeutlichen, betrachten wir ein praktisches Beispiel im Kontext einer Blog-Plattform, die Artikel und Autoreninformationen speichert.Embedded DocumentsAngenommen, Sie entwickeln eine Blog-Plattform, in der Artikel von Autoren verfasst werden. In einer relationalen Datenbank würden Sie möglicherweise separate Tabellen für Autoren und Artikel erstellen, die über eine Autoren-ID verknüpft sind. In MongoDB könnten Sie jedoch das Konzept der eingebetteten Dokumente nutzen. Ein Dokument für einen Artikel könnte wie folgt aussehen:
{
"_id": ObjectId("2a4c3..."),
"title": "Der Titel des Artikels",
"content": "Der Inhalt des Artikels...",
"author": {
"name": "Max Mustermann",
"email": "max@example.com"
}
}
Sie sehen, dass die Autoreninformationen direkt im Artikel-Dokument eingebettet sind. Dies ermöglicht es, alle relevanten Informationen zu einem Artikel in einem einzigen Dokument abzurufen, was Abfragen effizienter macht. Des Weiteren kann der Stand des Autors zum Zeitpunkt der Erstellung des Artikels fixiert werden. Wenn sich Namen oder Ähnliches ändern sollten, würde sich dies nicht auf den ursprünglichen Artikel auswirken. Dies ist insbesondere für Bestellsysteme oder Online-Shops wichtig, da sich ansonsten die ursprünglichen Daten und Belege ändern könnten. Dieses Schema kann jedoch anfällig für Redundanz sein, wenn mehrere Artikel vom selben Autor stammen.Referenzierte DokumenteAlternativ könnte man sich für eine referenzierte Dokumentenstruktur entscheiden, um Redundanz zu vermeiden. Ein Artikel-Dokument könnte auf ein separates Autoren-Dokument verweisen:Artikel-Dokument:
{
"_id": ObjectId("2a4c3..."),
"title": "Der Titel des Artikels",
"content": "Der Inhalt des Artikels...",
"author_id": ObjectId("ba23d...")
}
Autoren-Dokument:
{
"_id": ObjectId("ba23d..."),
"name": "Max Mustermann",
"email": "max@example.com"
}
In diesem Fall verweist das Artikel-Dokument auf das _id-Feld des entsprechenden Autoren-Dokuments. Das reduziert die Redundanz, da Autoreninformationen nur einmal gespeichert werden müssen. Allerdings erfordert das Abrufen eines Artikels nun eine zusätzliche Abfrage, um die Autoreninformationen zu erhalten.Die Wahl zwischen eingebetteten und referenzierten Dokumenten hängt von verschiedenen Faktoren ab, beispielsweise der Häufigkeit der Abfragen, der Konsistenz der Daten, der Notwendigkeit der Historisierung und der Notwendigkeit, Redundanz zu minimieren (Bild 3).
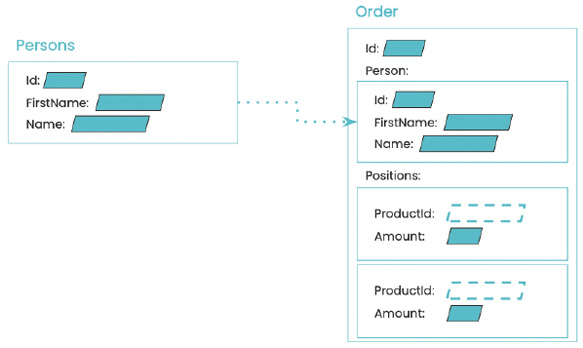
Referenz oder gekapseltes Dokument (Kopie) in MongoDB (Bild 3)
Autor
Entsprechend den vorgestellten Modellen muss hier auch das .NET-Datenmodell strukturiert werden. Für den Fall von .NET gibt es eine Möglichkeit zur Umsetzung von referenzierten Dokumenten in MongoDB mittels des .NET-Treibers und der Verwendung des Objekts MongoDBRef. Dieses Objekt ermöglicht es, eine Referenz zu einem anderen Dokument in einer anderen Sammlung herzustellen, indem es die ID des Ziel-Dokuments und den Namen der Ziel-Sammlung speichert. Der Vorteil von MongoDBRef liegt darin, dass es die Referenzierung transparenter macht und die Verwaltung von Referenzen erleichtert.
// Referenz auf einen Autor mittels MongoDBRef
var authorRef = new MongoDBRef("Authors",
ObjectId.Parse("author_id"));
// Ein Artikel-Dokument mit Referenz zum Autor // erstellen
var article = new BsonDocument
{
{ "title", "Der Titel des Artikels" },
{ "content", "Der Inhalt des Artikels..." },
{ "author", authorRef }
};
In diesem Beispiel wird eine MongoDBRef-Instanz erstellt, die auf ein Autoren-Dokument in der Authors-Sammlung verweist. Diese Referenz wird dann im Artikel-Dokument gespeichert. Hierbei liegt der Vorteil darin, dass die verweisende Collection ebenfalls gespeichert wird und dadurch eine Referenz über das Objekt und nicht durch eigene Programmlogik aufgelöst werden kann.Das für dieses Beispiel passende C#-Klassenmodell würde demnach wie folgt aussehen:
// C#-Klasse für Autoren
public class Author
{
[BsonId]
public ObjectId Id { get; set; }
public string Name { get; set; }
public string Email { get; set; }
}
// C#-Klasse für Artikel
public class Article
{
[BsonId]
public ObjectId Id { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public MongoDBRef Author { get; set; }
} IDs – Dos and Don’ts
Bei der Arbeit mit Datenmodellen ist die eindeutige Identifikation von Dokumenten von zentraler Bedeutung, um eine reibungslose Datenverwaltung zu gewährleisten. Im Fall von MongoDB kommt die sogenannte ObjectID ins Spiel – eine automatisch generierte und eindeutige Kennung für jedes in der Datenbank gespeicherte Dokument. Die MongoDB-ObjectID besteht aus zwölf Bytes und enthält Informationen wie einen Zeitstempel, eine Maschinen-ID, eine Prozess-ID und eine Zufallszahl. Diese Kombination garantiert, dass die ObjectID in der Regel weltweit einmalig ist und in verschiedenen Instanzen oder Datenbanken nicht kollidiert.Die Verwendung von MongoDB-ObjectIDs bietet mehrere Vorteile. Erstens erleichtert sie die eindeutige Identifikation von Dokumenten über verschiedene Sammlungen und Datenbanken hinweg. Dadurch wird die Notwendigkeit eines globalen, einheitlichen Schlüsselsystems reduziert. Zweitens ermöglicht die Verwendung der ObjectID die Zuordnung von Dokumenten ohne zentrale Koordination oder Konfliktvermeidung. Jede Instanz kann Dokumente mit ObjectIDs unabhängig voneinander erstellen, ohne befürchten zu müssen, dass es zu Kollisionen kommt. Drittens stellt die im Zeitstempel der ObjectID enthaltene Information sicher, dass Dokumente chronologisch sortiert werden können, was für viele Anwendungen von Vorteil ist, beispielsweise für Log-Einträge oder Zeitreihendaten.Gerade dieser Aspekt ist bei der Indizierung von Daten von großem Vorteil. Anstatt also auf clientseitig generierte IDs wie zum Beispiel GUIDs zu vertrauen, sollten die MongoDB-eigenen ObjectIDs genutzt und durch den Treiber automatisiert erstellt werden. Werden GUIDs beispielsweise zur Programmlaufzeit generiert und als Schlüssel festgelegt, so sind diese zwar nach dem Standard weltweit eindeutig, bringen jedoch eine wesentlich schlechtere Sortierbarkeit mit sich. Das führt zu einer schlechteren Indexqualität und wesentlich reduzierter Performance.Mit Indizes und Aggregationen blitzschnelle Abfragen zaubern
Die Gestaltung effizienter Abfragen in MongoDB ist ein entscheidender Aspekt, um die Leistung und Reaktionsfähigkeit Ihrer .NET-Anwendungen sicherzustellen. Dieser Abschnitt stellt bewährte Methoden und Best Practices zur Optimierung von Datenabfragen in MongoDB vor. Wir befassen uns dabei mit der Indexierung von Daten für verbesserte Abfrageleistungen sowie der Verwendung der Aggregation-Pipeline für die Bewältigung komplexer Abfragen.Die effiziente Abfrageleistung in MongoDB wird maßgeblich durch die Verwendung von Indizes beeinflusst. Indizes sind Datenstrukturen, die den Zugriff auf Daten beschleunigen, indem sie die Suche und Sortierung von Informationen optimieren. MongoDB unterstützt verschiedene Arten von Indizes, darunter Einzel- und Mehrfachfeldindizes, Textindizes für Volltextsuche sowie geografische Indizes für räumliche Daten. Die Erstellung eines Index ist einfach und kann direkt über den .NET-Treiber in C# erfolgen.Hier ist ein Beispiel für die Erstellung eines einfachen Index auf das title-Feld in der articles-Sammlung:
// C#-Klasse für Artikel
public class Article
{
[BsonId]
public ObjectId Id { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public MongoDBRef Author { get; set; }
}
Indizes können die Abfrageleistung erheblich verbessern, sind jedoch nicht ohne Kosten. Sie beanspruchen Speicherplatz und erfordern Aktualisierungen bei der Einfügung, Aktualisierung oder Löschung von Dokumenten. Es ist daher wichtig, Indizes sorgfältig für diejenigen Felder zu wählen, nach denen häufig gesucht wird, um den größtmöglichen Nutzen zu erzielen.Die Aggregation-Pipeline ist ein ausgereiftes und vielseitiges Werkzeug zur Verarbeitung und Transformation von Daten in MongoDB. Sie ermöglicht die Verknüpfung von mehreren Abfrageoperationen in einer Pipeline, um komplexe Transformationen und Berechnungen durchzuführen. Die Pipeline umfasst verschiedene Stufen wie $match, $group, $sort, $project und mehr, die in einer bestimmten Reihenfolge durchlaufen werden.Stellen wir uns vor, Sie möchten für alle Artikel, die ein Array Comments (Kommentare) beinhalten, ein Objekt erhalten mit der ID des Artikels sowie dem Zeitpunkt des letzten Kommentars:
var result = _db.GetCollection<Article>("Articles")
.Aggregate()
.Unwind(i => i.Comments)
.Group(new BsonDocument
{
{ "_id", "$ArtId" },
{ "LastComment", new BsonDocument("$max",
"$Comments.Created") }
})
.ToList();
Diese Pipelines werden serverseitig ausgeführt und sind äußerst flexibel, wenn es darum geht, komplexe Datenverarbeitungen direkt in der Datenbank durchzuführen. Dies kann die Notwendigkeit verringern, Daten in die Anwendung zu laden und dort zu verarbeiten, was ebenfalls die Leistung und Skalierbarkeit erhöht.
CRUD – das Herzstück
Die CRUD-Operationen (Create, Read, Update, Delete) bilden das grundlegende Fundament für die Interaktion mit Datenbanken. Der MongoDB-.NET-Treiber bietet eine reichhaltige Palette von Funktionen, um diese Operationen nahtlos in Ihre .NET-Anwendungen zu integrieren. Wir betrachten die Durchführung von CRUD-Operationen im Detail und stellen praxisnahe Codebeispiele für das Einfügen, Lesen, Aktualisieren und Löschen von Dokumenten bereit.Das Einfügen von Dokumenten in MongoDB ist mit dem .NET-Treiber denkbar einfach. Hier ist ein Beispiel, wie Sie ein neues Dokument in einer Sammlung erstellen können:
var collection =
database.GetCollection<Article>("Articles");
var newDocument = new Article()
{
Title= "Ein neuer Titel",
Content= "Text",
Author= new MongoDBRef("Authors", myAuthor.Id)
};
collection.InsertOne(newDocument);
Das Lesen von Dokumenten erfolgt über die Methode Find in der Collection. Über Find wird ein Objekt übergeben, das Kriterien beinhaltet, nach denen gefiltert werden soll. Hier ein Beispiel, das alle Dokumente in einer Sammlung abruft:
var collection =
database.GetCollection<Article>("Articles");
var documents =
collection.Find(new BsonDocument()).ToList();
Möchte man zum Beispiel nach Dokumenten suchen, deren Titel exakt Mein neuer Artikel ist, so kann dies über folgende Abfrage geschehen:
var collection =
database.GetCollection<Article>("Articles");
var documents = collection.Find(a => { a.Title =
"Mein neuer Artikel" }).ToList();
Mit dem Aufruf .AsQueryable() auf Basis der Collection können weiterhin auch primitive LINQ-Abfragen für die Abfragen durchgeführt werden.Müssen jedoch komplexere Abfragen ausgeführt werden, empfiehlt es sich gegebenenfalls, die strukturierten Abfragen in MongoDB durchzuführen.Im Fall von .NET stehen hier sogenannte Builder bereit, auf denen man im Objektmodell die Filterkriterien definieren kann:
var collection =
database.GetCollection<Article>("Articles");
var filter = Builders<User>.Filter.Regex("Title",
new BsonRegularExpression(regexString))
var documents = collection.Find(filter).ToList();
Die Filterung wird ebenso bei den Aktualisierungen von Daten verwendet. Dieser Schritt erfolgt über die Methode UpdateOne oder UpdateMany. Hier ist ein Beispiel, wie Sie einen gesamten Artikel anhand des bisherigen Titels aktualisieren können:
var collection =
database.GetCollection<Article>("Articles");
var newArticle = ...
var oldArticle = collection.Find(a => a.Id ==
articleId).FirstOrDefault();
collection.UpdateOne(a => a.Title == oldArticle.Title,
newArticle);
In diesem Fall würden alle vorhandenen Eigenschaften des Dokuments überschrieben werden. Möchte man jedoch ausschließlich einzelne Eigenschaften aktualisieren, kann dies mit differenziellen Aktualisierungen geschehen. Diese ermöglichen unter anderem auch, dass Werte in einem Unterdokument (Nested Document) oder einem Array geändert werden können, ohne das gesamte Dokument vollständig überschreiben zu müssen.
var collection =
database.GetCollection<Article>("Articles");
var oldArticle = collection.Find(a => a.Id ==
articleId).FirstOrDefault();
var update = Builders<BsonDocument>.Update.Set(
"Title", "Ein aktualisierter Titel");
collection.UpdateOne(a => a.Title ==
oldArticle.Title, update);
Das Löschen von Dokumenten ähnelt den Aktualisierungen und erfolgt über die Methode DeleteOne und DeleteMany. Hierbei können die gleichen Filtermechanismen eingesetzt werden, um zu definieren, welche Daten gelöscht und welche beibehalten werden sollen.
collection.DeleteMany(a => a.Title == oldArticle.Title);
All diese Aktionen stehen auch vollständig für asynchrone Aufrufe zur Verfügung und können mittels async/await komfortabel in modernen .NET-Applikationen eingesetzt werden.
Die MongoDB-„Specials“
Neben diesen einfachen Datentypen und typischen CRUD-Operatoren bietet MongoDB noch eine Reihe weiterer Operationen an, die für moderne Anwendungen äußerst sinnvoll sein können.Beispiel 1:Geoinformationen. MongoDB unterstützt die Verwendung von GeoJSON, womit Punkte, Linien oder Polygone in einem Koordinatensystem verarbeitet werden können. Dadurch ist es möglich, Geospatial-Applikationen umzusetzen, ohne eigene Berechnungen und Filtermethoden in der Geschäftslogik umsetzen zu müssen. Als weiteren Aspekt kann man ebenfalls Indizes auf entsprechende Daten legen und so einen geologischen Index (2d oder 2dsphere) setzen. Damit kann auch definiert werden, ob das Koordinatensystem auf einer flachen Geometrie fußt oder eben auf einer sphärischen Kugel. Dies hilft dem Datenbanksystem, die Berechnungen von Distanzen korrekt durchzuführen.Das folgende Beispiel führt eine Abfrage von Dokumenten durch, die eine Eigenschaft location haben. Diese sollen im Umkreis von 10 km um eine definierte Koordinate liegen.
// Geospatial-Abfrage durchführen
var queryPoint = new GeoJsonPoint<GeoJson2DGeographic
Coordinates>(new GeoJson2DGeographicCoordinates(
10.897, 48.370));
var filter = Builders<BsonDocument>.Filter.Near(
"location",
new GeoJsonPoint<GeoJson2DGeographicCoordinates>(
new GeoJson2DGeographicCoordinates(
queryPoint.Coordinates.Longitude,
queryPoint.Coordinates.Latitude)),
maxDistance: 10000); // Suchradius von 10 km
var results = collection.Find(filter).ToList();
Neben der Umkreissuche ist es möglich, boolesche Operatoren anzuwenden, um zu definieren, ob gewisse Polygone im Koordinatensystem eine Schnittmenge bilden, Punkte innerhalb einer Fläche liegen und vieles mehr.Beispiel 2: Volltext-Index. Neben den üblichen Indizes verfügt MongoDB auch über einen Text-Index, der die ungenaue Abfrage von Texten optimiert. Dies führt dazu, dass hochperformante Abfragen auf unstrukturierten Texten durchgeführt werden können. Empfehlenswert ist dies unter anderem für unser Beispiel des Blog-Systems.
// Volltextsuche durchführen
var searchText = "MongoDB .NET-Treiber";
var filter =
Builders<BsonDocument>.Filter.Text(searchText);
var results = collection.Find(filter).ToList();
Als Ergebnis erhält man hier die entsprechenden Dokumente inklusive der Information, wie hoch die „Trefferquote“ ist. Hierbei ist es jedoch wichtig, genau zu analysieren, welche Vorteile eine solche Volltextsuche mit sich bringt und ob diese sich für den gewünschten Anwendungszweck und Inhalt eignet. Dieser Index arbeitet auf Wortbasis und teils einem Wörterbuch, was bedeutet, dass dies für natürlich geschriebenen Text gut funktioniert. Will man jedoch damit eine Suche für Keywords oder Ähnliches aufsetzen und nutzt man Kürzel oder Fachbegriffe, kann die Qualität der ermittelten Ergebnisse schlagartig sinken.Demnach gilt: Bevor dieser Index eingesetzt wird, sollten eine entsprechende Testmenge und eine Evaluation durchgeführt werden. Oft empfiehlt es sich dann, Arrays an Stichwörtern zu erstellen und diese zum Beispiel via Regular Expressions zu filtern.Beispiel 3: Timeseries-Collection. Für eventbasierte, zeitgebundene Informationen eignen sich die sogenannten Timeseries-Collections und -Indizes.Dadurch werden die Daten anhand eines definierten Zeitpunkes innerhalb der Collection sortiert und gruppiert. Die entsprechende Gruppierung kann über die Definition der „Granularität“ des Index konfiguriert werden. Sollten Daten also nach Stunden gruppiert werden, werden diese trotz eines detaillierten Zeitstempels, der bis auf die Genauigkeit von Millisekunden reicht, innerhalb dieser Gruppe zusammengeführt. Das beschleunigt die Abfragen und ermöglicht die Verwaltung von vielen Millionen kleinen Datensätzen.Wichtig ist hierbei, dass diese Einstellungen beim Anlegen der Collection definiert werden. Danach kann über das übliche API nach Zeitstempel et cetera gefiltert werden.
Weitere Tipps und Tricks
Bei der Verwendung des MongoDB-Treibers für .NET gibt es einige bewährte Praktiken und Kniffe, die Ihnen helfen können, effizientere und sauberere Codebasen zu erstellen. In diesem Kapitel werden wir einige dieser Tipps und Tricks vorstellen, die dabei helfen können, das Beste aus dem Datenmodell herauszuholen.Tipp 1: Attribute für Mapping und Validierung verwenden. Der .NET-Treiber unterstützt Attribute, die das Mapping von C#-Klassen auf MongoDB-Dokumente steuern. Nutzen Sie Attribute wie [BsonId], [BsonRepresentation] und [BsonElement] für präzises und explizit definiertes Mapping. Darüber hinaus können Sie Datenvalidierungs-Attribute wie [Required], [Range] und so weiter verwenden, um die Validierung auf Modellebene zu erleichtern, sofern diese benötigt werden.Tipp 2: Konfiguration von Collections. Für fortgeschrittene Konfigurationen und das Definieren von Indizes bietet der Treiber ein Fluent-API. Dies ermöglicht eine detaillierte Steuerung der Datenbank- und Sammlungseinstellungen. Zum Beispiel:
var collectionSettings = new MongoCollectionSettings
{
AssignIdOnInsert = true,
WriteConcern = WriteConcern.WMajority
};
var collection = database.GetCollection<Product>(
"products", collectionSettings);
Hierbei wird definiert, dass die IDs beim Hinzufügen eines Objekts automatisch erstellt werden sollen, sowie dass im Fall eines Clusters (Replica-Set) der Schreibvorgang erst als „erfolgreich“ gilt, wenn mindestens die Hälfte der eingesetzten Datenbank-Instanzen diese Änderung gespiegelt haben.Tipp 3: Massenverarbeitung, wo immer möglich. Werden viele Daten in das Datenmodell übertragen, so empfiehlt es sich, dies über Batch-Inserts umzusetzen, um die Leistung erheblich zu verbessern. Hierbei kann die Methode InsertMany genutzt werden, die ein Array an Dokumenten entgegennimmt:
var productsToInsert = new List<Product>
{
new Product { Name = "Produkt 1", Price = 10 },
new Product { Name = "Produkt 2", Price = 20 }
};
collection.InsertMany(productsToInsert); Fazit
Die sehr intuitive Integration von MongoDB durch den offiziellen Treiber ermöglicht es, ganz natürlich objektorientierte Datenmodelle aufzubauen, ohne sich mit den Hindernissen und Einschränkungen von relationalen, zweidimensionalen Tabellen auseinandersetzen zu müssen.Durch die unterschiedlichen Spezialanwendungen, die MongoDB unterstützt, lassen sich mit hoher Geschwindigkeit auch Millionen von Datensätzen ohne größere Schwierigkeiten verwalten.Aus diesem Grund nutzen wir bereits seit über fünf Jahren in unserer Agentur erfolgreich MongoDB. Die typischen Schwierigkeiten, die wir zum Beispiel mit der Arbeit mit üblichen SQL-Datenbanken hatten (Migrationen, Update-Skripte et cetera) konnten so erheblich reduziert werden. Durch das Weglassen von OR-Mappern wie Entity Framework wurden ebenfalls ein gewisser Overhead und potenzielle Fehlerquellen abgebaut. Erfahrungsgemäß können wir sagen, dass 80 Prozent der Neuprojekte sich für MongoDB oder andere NoSQL-Datenbanken empfehlen, und können dies durch erfolgreiche Bestandsprojekte, Evaluationen und Proof-of-Concepts beweisen. ◾
Inhalt
- MongoDB als Allzweckwaffe
- Dokumentenorientierte Datenbanken versus relationale Datenbanken
- Eingesetzte Konzepte
- MongoDB in .NET einsetzen
- Installation und Einrichtung des Treibers
- Connection erstellen und verbinden
- Datenmodellierung in .NET für NoSQL-Systeme
- Hierarchie oder Referenz?
- IDs – Dos and Don’ts
- Mit Indizes und Aggregationen blitzschnelle Abfragen zaubern
- CRUD – das Herzstück
- Die MongoDB-„Specials“
- Weitere Tipps und Tricks
- Fazit











