
15. Jan 2024
Lesedauer 16 Min.
Vielseitiges Speicherformat
Vektordatenbanken und .NET
Im Bereich künstlicher Intelligenz und generativer AI erleben sie eine Renaissance: Vektordatenbanken.

Vektordatenbanken sind eine essenzielle Technologie, die in vielen Bereichen wie maschinellem Lernen, künstlicher Intelligenz und Big Data immer wichtiger wird. Sie unterscheiden sich von herkömmlichen Datenbanken dadurch, dass sie Daten als hochdimensionale Vektoren speichern, die mathematische Merkmale oder Eigenschaften repräsentieren. Der Einsatz betrifft den Kontext zahlreicher Anwendungsfälle, wie beispielsweise das Speichern umfangreicher semantischer Daten über Texte, Bilder, Sprache und andere komplexe Datenformate. Diese Daten dienen als Basis für Operationen und Entscheidungen.Seit dem Auftreten von ChatGPT und dem zunehmenden Erfolg generativer KI ist der Bedarf, Vektordaten zu speichern, enorm gestiegen.In der ersten Jahreshälfte 2023 sind dadurch zahlreiche zusätzliche Projekte entstanden, die insbesondere im Kontext der generativen KI zum Einsatz kommen. Dazu gehört zum Beispiel Chroma, eine Open-Source-Vektordatenbank für sogenannte Embeddings, die unter anderem im Kontext von Large Language Models (LLMs) eine wichtige Rolle spielen.Auch im .NET-Umfeld lassen sich Vektordatenbanken in Anwendungen einbinden. Es gibt verschiedene .NET-Bibliotheken und Frameworks, die den Umgang mit Vektordatenbanken erleichtern und helfen, leistungsstarke und effiziente Anwendungen zu erstellen. Die Verwendung von Vektordatenbanken in .NET-Projekten kann dazu beitragen, die Leistung und Flexibilität von Anwendungen zu verbessern, indem sie schnelle und genaue Suchen sowie effiziente Speicherung und Verwaltung von Vektordaten ermöglichen.Dieser Artikel gibt einen Einblick in die Welt der Vektordatenbanken und zeigt, welche Anwendungsfälle existieren und wie die Integration in .NET-Projekte gelingen kann.
Vektoren, Vektorräume und Vektordatenbanken
Vektordatenbanken sind ein spezieller Typ von Datenbanken, die Wissen in Vektoren übersetzen und es vergleichbar und wieder auffindbar speichern. Sie sind darauf ausgelegt, die Daten effizient zu speichern und abzurufen, um eine schnellere Verarbeitung großer Datensätze zu ermöglichen.Vektoren lassen sich mathematisch auf semantischer Ebene vergleichen, was in anderen Datenbanksystemen in vielen Anwendungsfällen nicht so einfach zu bewerkstelligen ist.Im Unterschied zu herkömmlichen relationalen Datenbanken (SQL) oder NoSQL-Datenbanken wie Key-Value-Stores, Dokumenten- und Graphdatenbanken sind Vektordatenbanken auf eine optimierte Verarbeitung von hochdimensionalen Daten spezialisiert, also Daten mit einer großen Anzahl von Merkmalen (Variablen, Attributen, Eigenschaften und vielem mehr). Die unterschiedlichen Arten stellt Bild 1 gegenüber. Der Kasten Spärliche oder dichte Vektoren erläutert noch einen weiteren Aspekt.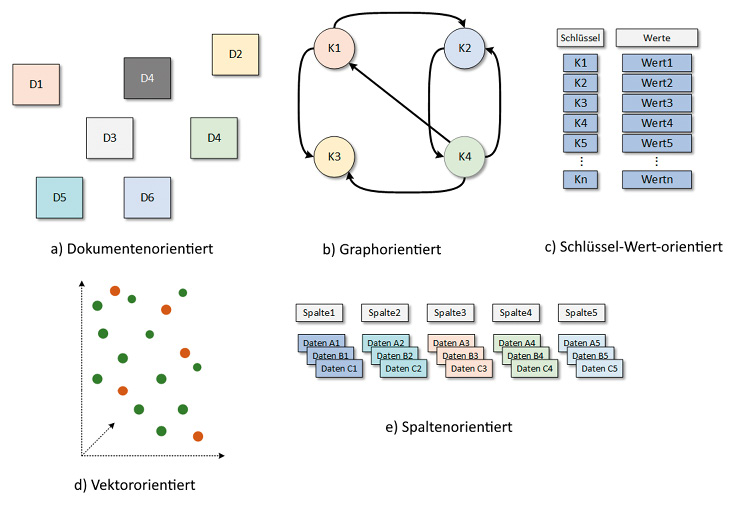
Schematische Darstellung verschiedener Datenbankmodelle: dokumentenorientiert, graph-orientiert, Schlüssel-Wert-orientiert, vektororientiert und spaltenorientiert (Bild 1)
Autor
Spärliche oder dichte Vektoren
Die Auswahl von Sparse- (spärlich besetzte) oder Dense- (dicht besetzte) Vektoren ist in der Praxis eine wichtige Frage. Spärlich besetzte Vektoren lassen sich effizienter speichern, sodass beispielsweise syntaxbasierte Vergleiche von zwei Sequenzen möglich sind. Bei zwei Sätzen wie zum Beispiel „Bill rannte von der Giraffe zum Delphin“ und „Bill rannte vom Delphin zur Giraffe“ würde bei einem Vergleich eine nahezu perfekte Übereinstimmung herauskommen. Das ergibt sich aus der gleichen Syntax, nämlich den Wörtern dieser Sätze.
Diese Datenbanken übersetzen Wissen in Vektoren, um so die Bedeutung und den Kontext von Daten zu erfassen. Die Analyse und Verarbeitung dieser Daten sind besonders nützlich für Anwendungen, die große Mengen an hochdimensionalen Daten verarbeiten müssen; das ist beispielsweise für datengetriebenen Modelle wie Large Language Models (LLMs) notwendig, die als Basis für generative KI dienen. Das bedeutet, dass Vektordatenbanken die Daten nicht in einer Form speichern, die von uns Menschen künstlich konstruiert wurde, wie beispielsweise Dokumente oder Relationen. Vektoren speichern diese Verbindungen von Daten indirekt im genannten mehrdimensionalen Raum ab.Ein Vektor im Sinn einer Vektordatenbank ist eine mathematische Struktur aus sogenannten Embeddings, zu Deutsch „Einbettungen“. Embeddings sind eine numerische Übersetzung von Eigenschaften (Dimensionen) der eigentlichen Daten. Bei einem Bild beispielsweise sind das Farbe, Textur, Stil, Form und so weiter.Die numerische Abbildung erlaubt es, Vektoren zu vergleichen und auf Ähnlichkeit zu untersuchen. Es wird also eine Suche ermöglicht. Im Fall von Zeichenketten/Text sind es Wörter oder andere Symbole, die Häufigkeit von Textbausteinen wie Wörtern, Silben oder Buchstaben. Diese Embeddings bilden somit die Vektoren, die durch die Abbildung beispielsweise eines Textes auf einen Vektorraum entstehen.Daneben speichert eine Vektordatenbank auch sogenannte Annotationen, welche die traditionelle Datenformate enthalten. Auf diese Weise besteht eine Verbindung zwischen den herkömmlichen Daten, zum Beispiel einem Text oder Bild, und dem Vektor.Durch diese Abbildung von Daten als Vektoren in einem Vektorraum wird deutlich, wie nützlich diese Form der Datenrepräsentation sein kann. Es ist möglich, eine ganze Sammlung von Text, Bildern, Videos und Audio als Vektoren darzustellen und anschließend die Ähnlichkeiten zwischen diesen Vektoren zu finden. Dafür gibt es eine ganze Reihe bekannter mathematischer Funktionen, wie Manhattan-Distanz, euklidische Distanz et cetera, wie sie Bild 2 zeigt.
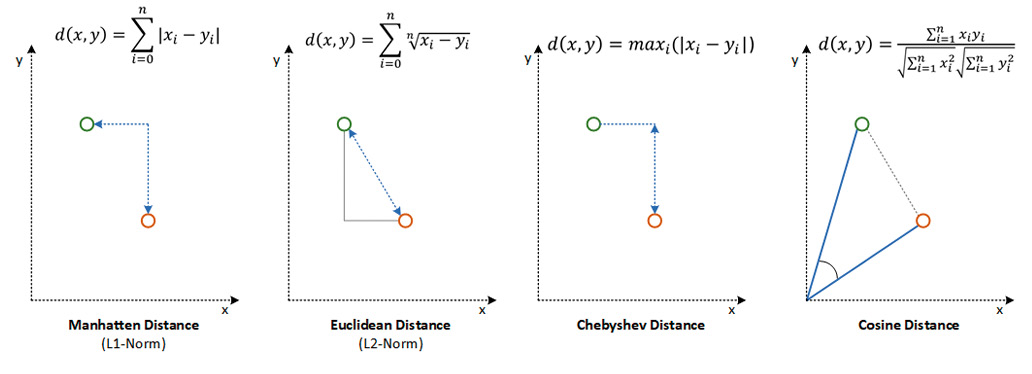
Verschiedene Distanzmaße mit ihrer mathematischen und visuellen Definition (Bild 2)
Autor
Die Manhattan-Distanz wird in der Regel der häufigeren euklidischen Distanz vorgezogen, wenn die Daten eine hohe Dimensionalität aufweisen. Die Kosinus-Distanz wird hauptsächlich verwendet, um den Grad der Ähnlichkeit zwischen zwei Datenpunkten zu ermitteln.
Anwendungsbereiche von Vektordatenbanken
Natural Language Processing (NLP) ist ein Bereich der künstlichen Intelligenz, der sich mit der Verarbeitung und Analyse menschlicher Sprache befasst. Vektordatenbanken sind hierfür besonders nützlich, weil die Embeddings die Bedeutung und den Kontext eines Textes erfassen können. Das ermöglicht eine effiziente Analyse und Verarbeitung von Textdaten, was die Leistung bei Aufgaben wie beispielsweise Textklassifikation und Sentimentanalyse verbessert; siehe auch den Kasten Embeddings.Embeddings
Embeddings sind eine wichtige Technik in der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP). Bei dieser Technik werden Wörter oder Texte als Vektoren in einem kontinuierlichen Vektorraum dargestellt. Diese Vektoren sind in der Regel reellwertig und codieren die Bedeutung eines Wortes so, dass semantisch ähnliche Wörter im Vektorraum nahe beieinander liegen [7]. Embeddings lassen sich mithilfe von Sprachmodellierung und Techniken zur Merkmalsextraktion erzeugen, bei denen Wörter oder Phrasen aus dem Vokabular auf Vektoren reeller Zahlen abgebildet werden [8].
Ein weiterer Vorteil von Vektordatenbanken im Bereich der Textverarbeitung besteht darin, dass sie die effiziente Suche nach ähnlichen Texten ermöglichen. Dies ist besonders nützlich für Anwendungen wie Plagiatsprüfung, automatische Zusammenfassung und Empfehlungssysteme für Textinhalte. Es gibt vielleicht keinen größeren Beitrag zum Erfolg der Technologie für die Verarbeitung natürlicher Sprache (NLP) als Vektordarstellungen von Sprache. Der kometenhafte Aufstieg von NLP lässt sich gut mit der Einführung von word2vec [1] im Jahr 2013 erklären.Die Ähnlichkeitssuche ist ein wichtiger Anwendungsbereich von Vektordatenbanken, bei dem es darum geht, Ähnlichkeiten zwischen verschiedenen Datenpunkten präzise zu identifizieren. Dies ist besonders nützlich für Anwendungen wie Empfehlungssysteme, bei denen Nutzerpräferenzen und empfohlene Artikel auf der Grundlage ihrer Ähnlichkeit zueinander ermittelt werden müssen. Vektordatenbanken ermöglichen diese schnelle Ähnlichkeitssuche.Ganz allgemein sind Anwendungsfälle für die Suche von Daten, also der semantische Vergleich, wie geschaffen für Vektordaten. Als Beispiel sei eine visuelle Suche genannt, die auf der Ähnlichkeit zwischen verschiedenen Bildern oder Videos basiert.Auch eine semantische Suche ist möglich, die auf einer effizienten Verarbeitung und Analyse von Textdaten basiert. Zudem lassen sich multimodale Suchen über Vektordatenbanken realisieren, da sich auf Basis der Vektoren Ähnlichkeiten zwischen verschiedenen Datenpunkten schnell identifizieren lassen. Diese Datenpunkte können auf unterschiedlichen Arten von Daten, wie Text, Bilder und Videos, basieren.Das Erkennen von Anomalien ist ein weiterer Anwendungsbereich von Vektordatenbanken. Hier geht es darum, ungewöhnliche oder auffällige Muster in Daten zu identifizieren. Dies kann beispielsweise nützlich sein, um Betrug zu erkennen, die Netzwerksicherheit zu erhöhen oder Qualität zu kontrollieren. Bei diesem Anwendungsfall werden die anfallenden Daten als Vektoren gespeichert. Wenn ein Vektor entsteht, der weit entfernt von bisherigen Vektoren liegt, dann kann es sich hierbei um eine Anomalie handeln.
semantische Ähnlichkeiten zwischen den gespeicherten Vektoren berücksichtigen.
.NET und Vektordatenbanken
Um Vektordatenbanken in .NET-Anwendungen einzubinden, sind entweder geeignete Bibliotheken oder Frameworks für die Integration auszuwählen, um die Verwaltung von und den Zugriff auf Vektordaten zu unterstützen – oder die Vektordatenbank erlaubt die Ansteuerung über allgemeine APIs wie REST-Schnittstellen.Es gibt verschiedene .NET-Bibliotheken und Frameworks, die den Umgang mit Vektordatenbanken erleichtern. Einige der bekanntesten und am häufigsten verwendeten Bibliotheken und Frameworks sind die nachfolgenden Beispiele.- ML.NET ist ein Open-Source- und plattformübergreifendes maschinelles Lern-Framework von Microsoft, das speziell für .NET-Entwickler gedacht ist. Es ermöglicht das Einbinden von maschinellem Lernen in .NET-Anwendungen, ohne dass Expertenwissen in maschinellem Lernen oder die Verwendung von externen Bibliotheken erforderlich ist. ML.NET unterstützt auch die Arbeit mit Vektordatenbanken, indem es Funktionen für die Verarbeitung und Analyse von Vektordaten bereitstellt.
- TensorFlow.NETist eine .NET-Bindung für das TensorFlow-Framework von Google. Es ermöglicht .NET-Entwicklern, TensorFlow-Modelle in Anwendungen einzubinden und maschinelles Lernen einzusetzen. TensorFlow.NET lässt sich ebenfalls für die Arbeit mit Vektordatenbanken nutzen, indem es Funktionen für das Speichern und Verarbeiten von Vektordaten bereitstellt.
- Accord.NET ist ein umfangreiches maschinelles Lern-Framework für .NET, das eine Vielzahl von Algorithmen und Werkzeugen für maschinelles Lernen, Mathematik, wissenschaftliche Berechnungen und Bildverarbeitung bietet. Das Framework stellt Funktionen für Speichern, Verarbeiten und Analyse von Vektordaten bereit.
- NumSharp ist eine .NET-Bibliothek, die Funktionen für numerische Berechnungen und Datenmanipulationen zur Verfügung stellt. Es ist von NumPy, einer bekannten Python-Bibliothek für numerische Berechnungen, inspiriert und bietet ähnliche Funktionen für .NET-Entwickler. NumSharp bietet ebenfalls Operationen für die Verarbeitung von Vektordaten.
- Math.NET Numerics ist eine Open-Source-Bibliothek, die numerische Funktionen bereitstellt. Dazu gehören Funktionen für lineare Algebra, komplexe Zahlen, numerische Integration, Differenzialgleichungen und vieles mehr, wie beispielsweise Möglichkeiten für den Umgang mit Vektordaten.
Vor- und Nachteile von Vektordatenbanken
Vektordatenbanken bieten gegenüber herkömmlichen Datenbanken eine Reihe von Vorteilen, die sie für bestimmte Anwendungen, beispielsweise im Bereich Deep Learning, zur besseren Wahl machen. Insbesondere in den vergangenen Monaten hat sich eine umfassende Community gebildet, um eine schnelle und unkomplizierte Integration mit Tools wie LangChain, LlamaIndex und ChatGPT-Plug-ins zu ermöglichen.Im Gegensatz zu herkömmlichen Datenbanken, die Probleme mit dem Speichern und Verarbeiten von Daten mit hohen Dimensionen haben können, bieten Vektordatenbanken schnelle Speicher- und Abruffunktionen und ermöglichen so einen schnellen Zugriff auf große Mengen an Vektordaten.Vektordatenbanken lassen sich zudem leicht in bestehende Ökosysteme integrieren, was sie zu einer flexiblen und anpassungsfähigen Lösung für verschiedene Anwendungsfälle macht. Sie unterstützen eine Vielzahl von Datenstrukturen und -formaten und können problemlos mit anderen Datenbanken, Tools und Plattformen zusammenarbeiten.Neben den Vorteilen haben Vektordatenbanken auch Nachteile. Dazu gehört beispielsweise die Komplexität, da Vektordatenbanken aufgrund ihrer spezialisierten Natur komplexer in der Handhabung sein können als herkömmliche Datenbanken. Zudem ist zu prüfen, ob eine Vektordatenbank den angepeilten Anwendungsfall optimal unterstützt oder ob eine herkömmliche Datenbank nicht besser geeignet ist. Darüber hinaus befindet sich der Markt der Vektordatenbanken in einem konstanten Wandel. Es sind unterschiedliche Technologien und Abfragesprachen im Einsatz. Diese fehlende Kategorisierung und Standardisierung führt möglicherweise zu Interoperabilitätsproblemen beim Einsatz mit den eigenen Systemen.Flexibilität und Anpassungsfähigkeit
Vektordatenbanken zeichnen sich durch ihre Flexibilität und Anpassungsfähigkeit aus, insbesondere hinsichtlich der Unterstützung verschiedener Datenformate und -typen. Im Gegensatz zu herkömmlichen relationalen Datenbanken, die auf festgelegten Schemata und Tabellenstrukturen basieren, bieten Vektordatenbanken eine größere Flexibilität beim Speichern und Verarbeiten von Daten.Ein Beispiel für die Flexibilität von Vektordatenbanken ist die Verwendung von NoSQL-Datenbanken in virtuellen Forschungsumgebungen (VREs). NoSQL-Datenbanken können die Flexibilität von VREs beim Speichern von Forschungsdaten erhöhen, da sie sich besser für langfristige und heterogene Datensätze eignen. Diese Art von Datenbanken ermöglicht es, verschiedene Datenformate und -typen zu speichern und zu verarbeiten, ohne dass komplexe Transformationen oder Anpassungen erforderlich sind.Die Flexibilität von Vektordatenbanken zeigt sich auch in der Unterstützung von verschiedenen Suchmodellen, wie zum Beispiel dem Boolean- und Extended-Boolean-Suchmodell. Diese Modelle ermöglichen es, effiziente und präzise Suchanfragen in Vektordatenbanken zu stellen, indem sie auf Vektorrepräsentationen von Daten basieren undsemantische Ähnlichkeiten zwischen den gespeicherten Vektoren berücksichtigen.
Unterschiedliche Vektordatenbanken
Es gibt verschiedene Vektordatenbanken, die sich in ihrer Funktionsweise und den Anwendungsfällen stark unterscheiden. Einige Vertreter sind auf hochverfügbare und skalierbare Systeme ausgelegt und benötigen ein solides technologisches Fundament, beispielsweise in der Cloud, selbst gehostet als Container oder in ähnlichen Umgebungen.Andere Vektordatenbanken sind für den kleinen und schnellen Einsatz bei Prototypen entwofen worden, etwa um Embeddings im Kontext eines Chatbots zu speichern. Diese Datenbanken lassen sich häufig mit wenigen Zeilen Code in Betrieb nehmen und speichern die Daten beispielsweise ausschließlich im Arbeitsspeicher. Die nachfolgende Liste enthält einige Beispiele für Vektordatenbanken.- Elasticsearch / Vector Search: Eine Open-Source-Such- und Analyse-Engine, die auf der Lucene-Bibliothek basiert und speziell für die Verarbeitung von Vektordaten optimiert ist.
- Weaviate: Eine Open-Source-Vektordatenbank, die auf der GraphQL-Schnittstelle basiert und speziell für die Verarbeitung von semantischen Daten und die Suche nach Ähnlichkeiten optimiert ist [2].
- Faiss von Facebook: Eine Open-Source-Bibliothek für die Verarbeitung von Vektordaten, die speziell für die Verarbeitung von großen Datensätzen und die Suche nach Ähnlichkeiten optimiert ist.
- Annoy von Spotify: Eine Open-Source-Bibliothek für die Verarbeitung von Vektordaten, deren Leistungsfokus auf der Suche nach Ähnlichkeiten und der Verarbeitung von großen Datensätzen liegt.
- Qdrant: Eine Vektordatenbank und zugleich Vektorsuchmaschine, die als API-Dienst bereitgestellt wird und die für die Suche nach den nächsten hochdimensionalen Vektoren optimiert ist.
- Supabase (pgvector): Eine Open-Source-Plattform für die Entwicklung von Anwendungen, die auf PostgreSQL basiert. Die Erweiterung pgvector ist dabei speziell für die Verarbeitung von Vektordaten optimiert [3].
- Pinecone: Eine Cloud-basierte Vektordatenbank, deren Fokus auf die Verarbeitung von Vektordaten und die Suche nach Ähnlichkeiten gerichtet ist [4].
- Chroma: Eine Open-Source-Vektordatenbank, die speziell für das Verarbeiten von Textdaten und die Suche nach Ähnlichkeiten optimiert ist.
.NET und pgvector
Das folgende Beispiel zeigt, wie sich mit .NET und der Bibliothek Npgsql [5] Daten in einer PostgreSQL-Vektordatenbank mit der pgvector-Erweiterung speichern und abrufen lassen. Die Npgsql-Bibliothek ist zuerst einzurichten, was aber beispielsweise über die NuGet-Paket-Manager-Konsole simpel ist:
Install-Package Npgsql
Listing 1 zeigt, wie die Bibliothek angewendet wird, um eine Verbindung aufzubauen, die pgvector-Erweiterung zu installieren, wenn sie noch nicht vorhanden ist, und eine Tabelle für Vektordaten zu erstellen. Diese Tabelle erhält eine Spalte für die Vektordaten, die anschließend über den Code mit einem Beispielvektor gefüllt wird. Listing 2 zeigt, wie diese Daten im nächsten Schritt über die gleiche Bibliothek wieder ausgelesen werden können.
Listing 1: Einen Vektor in PostgreSQL (pgvector) speichern
using Npgsql;
using System;
using System.Data;
namespace VectorDatabaseExample
{
class Program
{
static void Main(string[] args)
{
string connectionString = "Host=localhost;" +
"Username=postgres;Password=your_password;" +
"Database=your_database";
using (var connection =
new NpgsqlConnection(connectionString))
{
connection.Open();
// Installieren der pgvector-Erweiterung
using (var command = new NpgsqlCommand(
"CREATE EXTENSION IF NOT EXISTS pgvector;",
connection))
{
command.ExecuteNonQuery();
}
// Erstellen einer Tabelle zur Speicherung von
// Vektordaten
using (var command = new NpgsqlCommand(
"CREATE TABLE IF NOT EXISTS vector_data " +
"(id SERIAL PRIMARY KEY, vector_data " +
"VECTOR(5));", connection))
{
command.ExecuteNonQuery();
}
// Speichern von Vektordaten in der Tabelle
float[] vectorData = new float[] { 1.0f, 2.0f,
3.0f, 4.0f, 5.0f }; // Beispiel-Vektordaten
using (var command = new NpgsqlCommand(
"INSERT INTO vector_data (vector_data) " +
"VALUES (@vector_data);", connection))
{
command.Parameters.AddWithValue(
"vector_data", vectorData);
command.ExecuteNonQuery();
}
}
}
}
} Listing 2: Einen Vektor aus PostgreSQL abrufen
using Npgsql;
using System;
using System.Data;
namespace VectorDatabaseExample
{
class Program
{
static void Main(string[] args)
{
string connectionString = "Host=localhost;" +
"Username=postgres;Password=your_password;" +
"Database=your_database";
using (var connection =
new NpgsqlConnection(connectionString))
{
connection.Open();
// Abrufen von Vektordaten aus der Tabelle
using (var command = new NpgsqlCommand(
"SELECT id, vector_data FROM vector_data;",
connection))
{
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
int id = reader.GetInt32(0);
float[] vectorData = (float[])reader[1];
Console.WriteLine($"ID: {id}, " +
$"Vektordaten: {string.Join(", ",
vectorData)}");
}
}
}
}
}
}
}
In diesem Beispiel wird eine PostgreSQL-Vektordatenbank mit der pgvector-Erweiterung verwendet, um Vektordaten zu speichern und abzurufen. Aufgabe der Npgsql-Bibliothek ist es, eine Verbindung zur Datenbank herzustellen und SQL-Befehle auszuführen. Die Vektordaten werden als VECTOR-Typ in der Datenbank gespeichert.
.NET und Weaviate
Das folgende Beispiel verdeutlicht, wie mit .NET und der Weaviate.Client-Bibliothek Daten in einer Weaviate-Vektordatenbank gespeichert und abgerufen werden. Zunächst ist die Weaviate.Client-Bibliothek mit dem folgenden Befehl in einem .NET-Projekt zu installieren:
Install-Package Weaviate.Client
Das Beispiel hat ein ähnliches Ziel wie die vorherigen Beispiele zu pgvector. Die Ansteuerung der Weaviate-Vektordatenbank erfolgt über den Client, der die notwendigen API-Aufrufe ausführt. Die Vektordaten werden auch in diesem Beispiel als VECTOR-Typ in der Datenbank gespeichert. Listing 3 speichert die Vektordaten über eine eigene C#-Klasse; Listing 4 zeigt den Datenabruf aus der Datenbank.
Listing 3: Vektordaten in Weaviate speichern
using Weaviate.Client;
using System;
using System.Threading.Tasks;
namespace VectorDatabaseExample
{
class Program
{
static async Task Main(string[] args)
{
var client = new WeaviateClient(
"https://your-weaviate-instance-url",
"your-api-key");
// Erstellen einer Klasse zur Speicherung von
// Vektordaten
var classDefinition = new ClassDefinition
{
ClassName = "ExampleClass",
Properties = new List<PropertyDefinition>
{
new PropertyDefinition {
Name = "vectorData", DataType = "vector" }
}
};
await client.Schema.Classes
.CreateAsync(classDefinition);
// Speichern von Vektordaten in der Klasse
var vectorData = new float[] { 1.0f, 2.0f, 3.0f,
4.0f, 5.0f }; // Beispiel-Vektordaten
var dataObject = new DataObject
{
ClassName = "ExampleClass",
Properties = new Dictionary<string, object>
{
{ "vectorData", vectorData }
}
};
await client.Data.Objects
.CreateAsync(dataObject);
}
}
} Listing 4: Vektordaten aus Weaviate abrufen
using Weaviate.Client;
using System;
using System.Threading.Tasks;
namespace VectorDatabaseExample
{
class Program
{
static async Task Main(string[] args)
{
var client = new WeaviateClient(
"https://your-weaviate-instance-url",
"your-api-key");
// Abrufen von Vektordaten aus der Klasse
var objects = await client.Data.Objects
.GetAllAsync("ExampleClass");
foreach (var obj in objects)
{
Console.WriteLine($"ID: {obj.Id}, " +
$"Vektordaten: {string.Join(", ",
(float[])obj.Properties["vectorData"])}");
}
}
}
} Das Ökosystem rund um generative AI
Zusätzlich zu den Vektordatenbanken gibt es ein sehr stark wachsendes Ökosystem aus Anbietern, Plattformen, Programmiersprachen sowie Frameworks und Bibliotheken, die sich gut mit Vektordatenbanken und Vektordaten verstehen. Dazu gehören nicht zuletzt die generativen AI-Systeme in Form von LLMs, die bereits in der ersten Hälfte des Jahres 2023 für die ein oder andere Schlagzeile gesorgt haben. Beispiele für Tools, die mit Vektordatenbanken integriert werden können, bietet die folgende Liste.- LangChain: Ein Framework, welches das Erstellen von Anwendungen auf Basis großer Sprachmodelle vereinfacht und mit Vektordatenbanken wie Chroma zusammenarbeiten kann, um Textverarbeitung und Analyse zu ermöglichen.
- LlamaIndex: Ein KI-basiertes Indexierungssystem, das mit Vektordatenbanken zusammenarbeitet, um schnelle und präzise Ähnlichkeitssuche und Anomalieerkennung zu ermöglichen.
- ChatGPT-Plug-ins: Erweiterungen für das ChatGPT-Modell von OpenAI, welche die Integration von Vektordatenbanken ermöglichen, um die Leistung und Funktionalität des Modells bei der Verarbeitung von Textdaten zu verbessern.
Vektordatenbanken im Kontext von LLMs
Das nächste Codebeispiel zeigt, wie eine Chroma-Instanz in LangChain verwendet werden kann, um dort die Chunks von Dokumenten in Form von Embeddings zu speichern. Diese Embeddings lassen sich dann bei Nutzerabfragen verwenden, um über die Ähnlichkeit passende Stellen in den Dokumenten zu finden. Diese passenden Stellen lassen sich dann für das Kontextfenster der LLM nutzen, um die konkrete Frage zu beantworten. Listing 5 zeigt dazu das Beispiel in Python, um ein Dokument zu laden, in Chunks aufzuteilen, daraus Embeddings zu erstellen und diese in der Vektordatenbank Chroma zu speichern.Listing 5: LLM und Chroma in Python einbinden
# Das Dokument laden.
loader = TextLoader("data.txt")
documents = loader.load()
# Den Inhalt in Chunks aufteilen.
text_splitter = CharacterTextSplitter(
chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)
# Eine Open-Source-Embedding-Funktion nutzen.
embedding_function = SentenceTransformerEmbeddings(
model_name="all-MiniLM-L6-v2")
# Die Dokumente und Embeddings über die Embedding-
# Funktion in Chroma laden.
db = Chroma.from_documents(docs, embedding_function)
# Auf Basis einer Anfrage ähnliche Textstellen im
# Dokument (den Chunks) finden.
query = "..."
docs = db.similarity_search(query)
Auf Basis einer Anfrage lassen sich dann über die Datenbank ähnliche Dokumente finden.Die Fortschritte in der generativen KI haben direkte Auswirkungen auf Vektordatenbanken, da sie die effiziente Verarbeitung und Analyse von hochdimensionalen Daten erfordern, um komplexe Muster und Zusammenhänge zu erkennen. Die Integration von Vektordatenbanken mit Frameworks wie LangChain ermöglicht es, komplexe Anwendungen wie Chatbots auf Basis eigener Dokumente und Daten zu erstellen. Vektordatenbanken spielen hier bei AIs eine entscheidende Rolle, um einen umfangreicheren Kontext zu liefern und Halluzinationen vorzubeugen, siehe Bild 3.
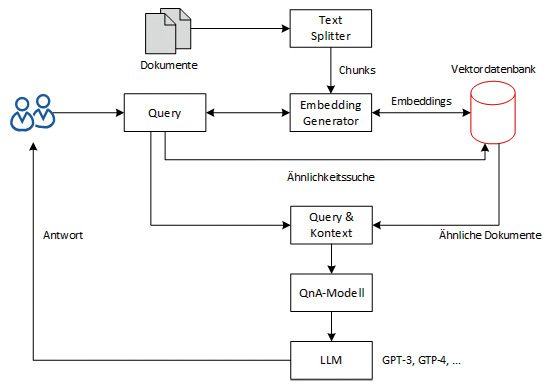
Eine Vektordatenbank im Kontext eines Chatbots (LLM) über eigene Daten (Bild 3)
Autor
Die im Beispiel gespeicherten Embeddings dienen dazu, zu einer Anfrage eines Nutzers die entsprechenden Textstellen in einem Dokument zu finden. Dies erfolgt über den Verleich der Embeddings (Vektoren) der Anfrage mit den Embeddings (Vektoren) der Datenbank. Die gefundenen Textstellen lassen sich dann als Kontext inklusive der Frage an das Large Language Model (LLM) weiterreichen, damit dieses die Frage beantworten kann. Dadurch lassen sich die Fragen zu Textstellen in den Dokumenten stellen und das Kontextfenster der LLM wird nicht überschritten.Auf ähnliche Weise lassen sich Embeddings einsetzen, um Dokumente in Vektoren zu überführen und in einer Vektordatenbank zu speichern, beispielsweise mit Pinecone, wie Bild 4 zeigt. Die Statistiken in dem Bild zeigen, dass der Index mit den Vektoren online ist und über Abfragen angefragt wurde. Die 116 Vektoren besitzen 1536 Dimensionen und speichern die Embeddings aus den Texten von zwei PDF-Dokumenten. Über Anfragen an Pinecone als Vektordatenbank lassen sich nun ähnliche Textstellen in diesen Dokumenten identifizieren:
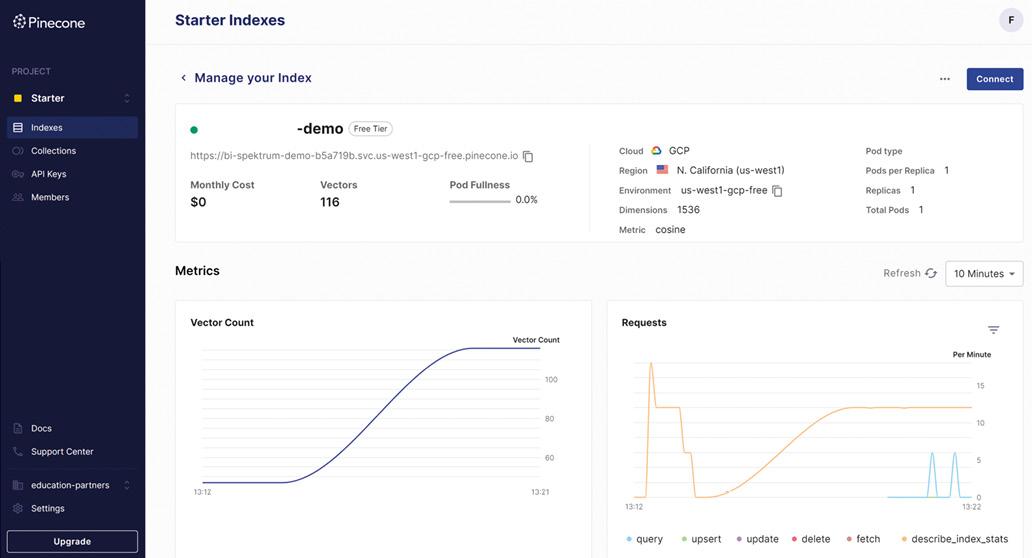
Der Index „bi-spektrum-demo“ mit Vektoren (Embeddings) von zwei PDF-Dokumenten (Bild 4)
Autor
query =
"Was ist Microsoft Teams?"
docs = docsearch
.similarity_search(query)
Das Resultat ist eine Ergebnismenge aus Textstellen im
Dokument. Diese werden mit
Referenz auf das entsprechende Dokument, die Seite und mit der Textstelle selbst ausgegeben. Im nächsten Schritt lassen sich diese Textstellen an eine LLM übergeben, um spezifische Fragen auf Basis dieses Textes zu beantworten.Das ist ein elementarer Schritt, um LLM-Chatbots vor dem Halluzinieren zu bewahren.
Dokument. Diese werden mit
Referenz auf das entsprechende Dokument, die Seite und mit der Textstelle selbst ausgegeben. Im nächsten Schritt lassen sich diese Textstellen an eine LLM übergeben, um spezifische Fragen auf Basis dieses Textes zu beantworten.Das ist ein elementarer Schritt, um LLM-Chatbots vor dem Halluzinieren zu bewahren.
Herausforderungen und Best Practices
Im Zusammenhang mit Vektordatenbanken sind verschiedene Herausforderungen und Best Practices wichtig, um diese Datenbankform korrekt einzusetzen.Dazu gehören Sicherheitsaspekte, Resilienz und die Auswahl der richtigen Datenbank für spezifische Anforderungen. Bewährte Praktiken wie Verschlüsselung, Authentifizierung und die Planung und Implementierung von Resilienzstrategien, einschließlich Backup- und Wiederherstellungsverfahren, sind wichtig, um den Betrieb im Fall eines Ausfalls oder einer Störung aufrechtzuerhalten.Die Auswahl der richtigen Datenbank für spezifische Anforderungen ist zudem entscheidend, um die bestmögliche Leistung und Funktionalität zu erzielen. Dabei gilt es verschiedene Faktoren zu berücksichtigen, wie etwa die Größe der Datenbank, die Dimensionalität der Vektoren und die spezifischen Operationen, die auszuführen sind. Nicht immer ist die leistungsfähigste Vektordatenbank auch die richtige. In zahlreichen Situationen reicht eine einfache Lösung aus, um die Daten zum Beispiel im Arbeitsspeicher zu halten und dadurch kleine und prägnante Tests auszuführen.Visualisierung von Vektordaten als Notwendigkeit
Die Visualisierung von Vektordaten ist ein wichtiger Aspekt bei der Arbeit mit Vektordatenbanken, da sie dazu beiträgt, die Daten besser zu verstehen und zu interpretieren.Es gibt verschiedene Tools und Technologien, die bei der Visualisierung solcher Daten eingesetzt werden können. Drei Beispiele sind:- QGIS: eine Open-Source-Geoinformationssystem-Software, welche die Visualisierung und Analyse von Vektordaten unterstützt.
- D3.js: eine JavaScript-Bibliothek, um interaktive und dynamische Datenvisualisierungen im Web zu erstellen, die auch für die Darstellung von Vektordaten verwendet werden kann.
- Kepler.gl: eine Open-Source-Webanwendung, die geografische Datenvisualisierungen erstellt und auch Vektordaten unterstützt.
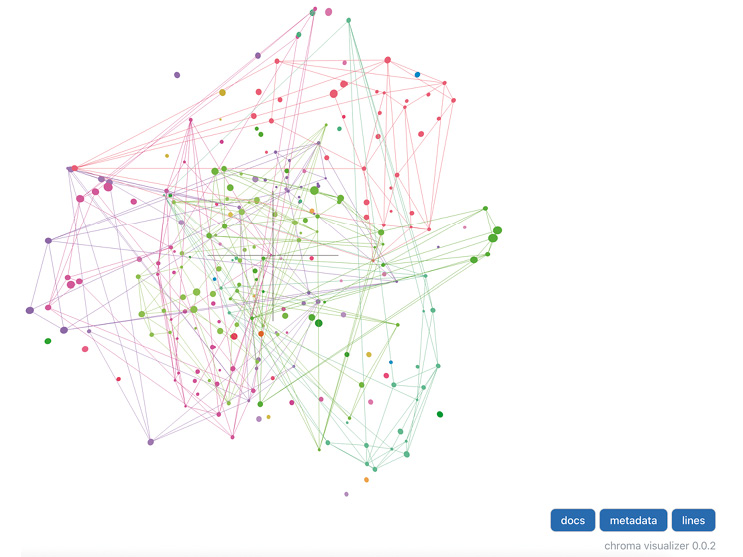
Visualisierung einer Chroma-Instanz in LangChain mit Text-Embeddings (Bild 5)
Autor
Fazit
Vektordatenbanken sind spezialisierte Datenbanken, die darauf ausgelegt sind, hochdimensionale Vektordaten effizient zu speichern, abzurufen und zu verarbeiten. Die Anwendungsbereiche dieser Daten und somit von Vektordatenbanken sind vielfältig und umfassen Datenvorbereitung und Trainingsdatenbanken für Deep Learning, NLP und Textverarbeitung sowie Ähnlichkeitssuche und das Erkennen von Anomalien.Vektordatenbanken sind in verschiedenen Branchen wie Finanzdienstleistungen, Hightech, Medien und Biowissenschaften von wachsender Bedeutung. Die Zukunftsaussichten für ihre Anwendung sind daher gut. Es ist zu erwarten, dass die Integration in Ökosysteme umfangreicher und gleichzeitig einfacher wird. Das ermöglicht weitere Anwendungsfälle in verschiedene Branchen.Diese Vektordatenbanken lassen sich in unterschiedlichen Programmiersprachen und auf unterschiedlichen Plattformen ansteuern; beispielsweise in Python sowie C#/.NET und mit unterschiedlichen Bibliotheken und Frameworks. Häufig gibt es spezifische Clients für Vektordatenbanken, um die Verwaltung der Vektordaten weiter zu vereinfachen. Das Ansteuern einer Vektordatenbank lässt sich mithilfe dieser Clients umsetzen oder über generalisierte REST-Schnittstellen, sodass die Einbindung sehr unabhängig von einer konkreten Programmiersprache ist.Zusammenfassend: Die Technologien und Tools für Vektordatenbanken ermöglichen das Speichern und Verwalten von Vektordaten in verschiedenen Systemen, die Integration mit KI-Tools und die Visualisierung von Vektordaten. Fortschritte in der generativen KI und deren Einfluss auf Vektordatenbanken werden die Entwicklung und Anwendung von Vektordatenbanken weiter vorantreiben. Hier sind in der zweiten Jahreshälfte 2023 und in den kommenden Jahren erhebliche Sprünge zu erwarten. Ein derzeit häufiger Einsatz sind Datenspeicher für Large Language Models (LLMs), um Anwendungen wie Chatbots und Ähnliches zu ermöglichen.Fussnoten
- Informationen und Beschreibungen zu word2vec,
- Weaviate Concepts: Interface,
- pgvector: Embeddings and vector similarity,
- Pinecone, https://www.pinecone.io/
- Npgsql – .NET Access to PostgreSQL, https://www.npgsql.org/
- Atlas: Visualizing a Vector Database – Weaviate,
- Word-Embedding bei Wikipedia,
- A Guide on Word Embeddings in NLP,
- Word Embeddings in NLP,
Inhalt
- Vektoren, Vektorräume und Vektordatenbanken
- Spärliche oder dichte Vektoren
- Embeddings
- .NET und Vektordatenbanken
- Vor- und Nachteile von Vektordatenbanken
- Flexibilität und Anpassungsfähigkeit
- Unterschiedliche Vektordatenbanken
- .NET und pgvector
- .NET und Weaviate
- Das Ökosystem rund um generative AI
- Vektordatenbanken im Kontext von LLMs
- Herausforderungen und Best Practices
- Visualisierung von Vektordaten als Notwendigkeit
- Fazit











