
17. Feb 2025
Lesedauer 17 Min.
Offene Alternative
Open-Source-Datenbank PostgreSQL, Teil 1
Installation der objektrelationalen Datenbank PostgreSQL

Auf der Microsoft-Plattform ist der SQL Server seit Jahrzehnten die meistgenutzte Datenbank. Doch in den zurückliegenden Jahren hat die leistungsstarke und kostenlose Open-Source-Datenbank PostgreSQL massiv an Bedeutung gewonnen. Immer mehr Unternehmen, darunter auch große Organisationen, entscheiden sich für den Umstieg von SQL Server auf PostgreSQL, vor allem aufgrund der geringeren Kosten und der hohen Flexibilität. Dieser Artikel bildet den Auftakt einer Artikelserie, die einen genauen Blick auf PostgreSQL wirft und die Unterschiede zum SQL Server zeigt.Die Anfänge von PostgreSQL reichen bis in die 1980er-Jahre zurück. Das Datenbanksystem hat sich im Lauf der Jahrzehnte von einem akademischen Forschungsprojekt zu einer der weltweit leistungsfähigsten und meistgenutzten Open-Source-Datenbanken entwickelt.Die Ursprünge von PostgreSQL liegen im Postgres-Projekt, das 1986 an der University of California, Berkeley vom Informatiker Michael Stonebraker ins Leben gerufen wurde. Er und sein Team entwickelten Postgres als Nachfolger der populären Ingres-Datenbank, die ebenfalls in Berkeley als Forschungsprojekt entstanden war. Der Name Postgres leitet sich von Post-Ingres ab, da das System viele der Konzepte von Ingres weiterentwickeln sollte. Stonebrakers Ziel war es, eine Datenbank zu schaffen, die mit objektorientierten Konzepten arbeitet und somit über die damals üblichen relationalen Datenbanken hinausgeht.Postgres führte einige (für die damalige Zeit) revolutionäre Funktionen ein, wie zum Beispiel das Multiversion Concurrency Control System (MVCC), das auch heute noch eine der Kernfunktionen von PostgreSQL ist. MVCC ist vergleichbar mit Optimistic Concurrency, das mit dem SQL Server 2005 eingeführt wurde. Es ermöglicht, lesende Transaktionen ohne Shared Locks auszuführen, indem mehrere Versionen von Datensätzen gleichzeitig verwaltet werden. Dies sorgt für eine hohe Effizienz in Mehrbenutzerumgebungen und gilt als einer der Hauptgründe für die Performance-Vorteile von PostgreSQL in komplexen Szenarien.In den frühen 1990ern erhielt Postgres einige Erweiterungen, darunter die Implementierung der Structured Query Language (SQL) als Abfragesprache, wodurch der Grundstein für das heutige PostgreSQL gelegt wurde. 1996 wurde das Projekt offiziell in PostgreSQL umbenannt. Seitdem hat sich das System zu einer vollwertigen relationalen Datenbank mit umfassender SQL-Unterstützung und einer Vielzahl moderner Funktionen entwickelt.Im Gegensatz zu kommerziellen Datenbanken wird PostgreSQL von einer globalen Entwickler-Community gepflegt und kontinuierlich weiterentwickelt. Dadurch hat PostgreSQL viele Funktionen erhalten, die oft erst Jahre später in kommerziellen Systemen auftauchten. Dazu gehören neben MVCC auch die Unterstützung für erweiterbare Datentypen, Indizes (wie GIN und GiST) und Replikationsmechanismen.Heute gilt PostgreSQL als eine der leistungsfähigsten Open-Source-Datenbanken und wird von großen Unternehmen weltweit eingesetzt. Die kontinuierliche Weiterentwicklung durch eine engagierte Community, die robuste Architektur und die weitreichenden Anpassungsmöglichkeiten machen PostgreSQL zu einer ausgezeichneten Wahl für verschiedenste Anwendungsfälle – von kleinen Anwendungen bis hin zu großen, verteilten Systemen.
PostgreSQL versus Microsoft SQL Server
Werfen wir zunächst einen Blick auf die Unterschiede der Architekturen von PostgreSQL und SQL Server, da wir auf diese im weiteren Verlauf dieser Artikelserie immer wieder zu sprechen kommen werden.Ein fundamentaler Unterschied zwischen Microsofts SQL Server und PostgreSQL liegt darin, wie die Datenbanksysteme Anfragen verarbeiten. SQL Server setzt dabei auf eine Thread-basierte Architektur, während PostgreSQL prozessbasiert arbeitet.Jede Client-Verbindung im SQL Server wird durch einen Thread innerhalb eines einzelnen Prozesses verwaltet. Dies führt zu einer effizienteren Speicherverwaltung, da Threads weniger Speicher erfordern als Prozesse. Threads können vom Betriebssystem auch um einiges schneller erzeugt werden als Prozesse. Diese Architektur ermöglicht es SQL Server, eine große Anzahl von Verbindungen und parallelen Anfragen zu verarbeiten, ohne zu viel Overhead zu generieren.Im Gegensatz dazu startet PostgreSQL für jede eingehende Verbindung einen separaten Prozess. Diese laufen unabhängig voneinander, was zu einer stärkeren Isolation führt. Sollte ein Prozess abstürzen, bleiben die anderen Verbindungen davon unberührt. Das führt zu einer höheren Stabilität. Der Nachteil liegt darin, dass Prozesse mehr Ressourcen erfordern, insbesondere mehr Speicher.Ein weiterer großer Unterschied besteht in der Implementierung des Write Ahead Logging (WAL). Darunter versteht man einen Mechanismus, der sicherstellt, dass alle Datenbankänderungen erst in ein Protokoll geschrieben werden, bevor die Änderungen permanent in die Datenbank übernommen werden. Dies schützt vor Datenverlust bei Systemabstürzen und erlaubt es im Fehlerfall, die Daten wiederherzustellen. SQL Server und PostgreSQL implementieren diesen Mechanismus auf unterschiedliche Arten.Im SQL Server hat jede Datenbank ihr eigenes Transaktions-Log. Dies bedeutet, dass alle Datenbanken einer SQL-Server-Instanz ihre Änderungen unabhängig voneinander protokollieren. Daraus ergibt sich der Vorteil, dass man eine einzelne Datenbank zurücksetzen oder wiederherstellen kann, ohne dass die anderen Datenbanken davon betroffen sind. Zudem erlaubt es ein Point-In-Time-Recovery (PITR) auf der Ebene einer einzelnen Datenbank.PostgreSQL hingegen verwendet ein einheitliches WAL-Log für die komplette PostgreSQL-Installation. Das bedeutet, dass alle Datenbanken innerhalb der gleichen PostgreSQL-Installation in dasselbe WAL-Log schreiben. Der Vorteil dieses Ansatzes liegt in der vereinfachten Verwaltung – es gibt nur ein einziges Log, das überwacht und gesichert werden muss. Der Nachteil ist jedoch, dass ein Point-In-Time-Recovery immer die komplette PostgreSQL-Installation betrifft. Sie können folglich eine einzelne Datenbank nicht unabhängig von den anderen Datenbanken wiederherstellen. Die vierte Folge dieser Serie wird sich näher mit dem WAL-Log und der Hochverfügbarkeit von PostgreSQL-Installationen beschäftigen.Die Unterstützung von gleichzeitig aktiven Benutzern ist ein weiterer Bereich, in dem sich SQL Server und PostgreSQL deutlich unterscheiden. Dies beeinflusst, wie Transaktionen abgewickelt werden und wie sie sich aufeinander auswirken, insbesondere in Bezug auf Sperren und Blockierungen.SQL Server verwendet als Standardeinstellung das Pessimistic-Concurrency-Control-Modell, bei dem Transaktionen Locks auf Datensätze setzen, um die Datenkonsistenz sicherzustellen. Diese Locks werden sowohl beim Lesen (Shared Lock) als auch beim Schreiben (Exclusive Lock) von Datensätzen gesetzt. Dadurch kann es jedoch zu Blockaden kommen, wenn mehrere Transaktionen gleichzeitig auf dieselben Datensätze lesend und schreibend zugreifen möchten.Um das zu umgehen, bietet SQL Server seit 2005 das Optimistic-Concurrency-Modell an, das mit einer Datensatz-Versionierung arbeitet: Jede schreibende Transaktion kopiert die alte Datensatzversion in den sogenannten Version Store (der in der TempDb gehalten wird), damit lesende Transaktionen auf die Daten zugreifen können, ohne Shared Locks anfordern zu müssen. Damit können Blockaden zwischen lesenden und schreibenden Transaktionen vermieden werden.PostgreSQL setzt hier Multiversion Concurrency Control (MVCC) ein, das die Möglichkeiten von Optimistic Concurrency ohne Zuhilfenahme von Shared Locks bei lesenden Zugriffen ermöglicht. MVCC erlaubt es, dass Transaktionen auf unterschiedlichen Versionen von Datensätzen arbeiten. Es gibt keine expliziten Locks für lesende Transaktionen, wodurch sich lesende und schreibende Transaktionen gegenseitig nicht blockieren können.Jede Transaktion arbeitet auf einer eigenen Datensatzversion. Das verbessert die Leistung insbesondere bei vielen gleichzeitigen Lese- und Schreiboperationen. Ein Nachteil von MVCC ist, dass die Datenbank regelmäßig sogenannte VACUUM-Operationen durchführen muss, um alte, nicht mehr benötigte Datensatzversionen aufzuräumen. Mehr dazu erfahren Sie im dritten Teil der Artikelserie.Die Art und Weise, wie Daten im SQL Server und in PostgreSQL gespeichert und indiziert werden, ist ebenfalls ein zentraler Unterschied zwischen den beiden Datenbanksystemen.Im SQL Server können Tabellen entweder als Clustered Tables oder als Heap Tables gespeichert werden. Eine Clustered Table bedeutet, dass die Tabellendaten physisch in der Reihenfolge des Clustered Keys abgelegt werden. Jede Tabelle kann nur einen solchen Clustered Index haben, der definiert, wie die Daten physisch sortiert werden.Alternativ können Heap Tables genutzt werden, welche die Datensätze in keiner spezifischen Reihenfolge speichern. In beiden Varianten lassen sich zusätzliche Non-Clustered Indizes verwenden, die auf die Datensätze in der eigentlichen Tabelle verweisen.PostgreSQL speichert Tabellendaten immer in Heap Tables ab. Das bedeutet, dass die physische Speicherung der Daten nicht auf Basis eines Indexes erfolgt. Stattdessen verwendet PostgreSQL sekundäre Indizes wie B-Tree, GIN, GiST und andere, um in Heap Tables gespeicherte Datensätze effizient abfragen zu können.Es gibt zwar den Befehl CLUSTER, mit dem eine Tabelle basierend auf einem Index physisch neu sortiert werden kann, dies ist jedoch eine einmalige Operation, deren Ergebnis bei späteren Änderungen nicht automatisch aufrechterhalten wird. Der zweite Teil dieser Artikelserie wird sich näher mit den Themen Indizierung und Performance-Tuning von PostgreSQL-Datenbanken beschäftigen.Schon dieser kurze Überblick zeigt, dass sich SQL Server und PostgreSQL deutlich voneinander unterscheiden. Beide sind zwar klassische relationale Datenbanken, implementieren jedoch die Grundkonzepte in einer anderen Art und Weise.PostgreSQL installieren
PostgreSQL läuft auf allen modernen Betriebssystemen: Windows, Linux, macOS, BSD und Solaris. Darüber hinaus werden auch Hardware-Plattformen wie der ARM-basierende Raspberry Pi unterstützt. PostgreSQL lässt sich einerseits direkt über einen Installer einrichten oder auch direkt aus dem C-Quellcode kompilieren [1].Die einfachste Möglichkeit, PostgreSQL auszuprobieren, ist die lokale Installation in einem Docker-Container, den Sie bei Bedarf einfach wegwerfen und neu aufbauen können.Da die Beschreibung aller notwendigen Schritte einer Installation von PostgreSQL in einer virtuellen oder physischen Maschine diesen Artikel sprengen würde, habe ich diese in einen Blogpost ausgelagert, den Sie unter [2] finden.Einfacher geht es mit Docker. Hier die erforderlichen Docker-Befehle, um PostgreSQL lokal in einem Container zu installieren:
docker pull postgres
docker run
--name postgres
-e POSTGRES_PASSWORD=passw0rd1!
-p 5432:5432
-d postgres
Im ersten Schritt wird das Docker-Image postgres geladen. Anschließend instanziert der Befehl docker run daraus einen Docker-Container. Diesem Container wird der Name postgres zugewiesen, und über die Umgebungsvariable POSTGRES_PASSWORD wird das Passwort für den postgres-Benutzer gesetzt. Diesen Benutzer können Sie sich wie den sa-Benutzer beim SQL Server vorstellen.Eine PostgreSQL-Installation ist unter dem Port 5432 erreichbar (Standardeinstellung). Daher wird über den Parameter -p auch dieser Port auf den lokalen Port 5432 gemappt, wodurch die PostgreSQL-Installation unter localhost:5432 erreichbar ist.Durch den Parameter -d wird der Docker-Container im Hintergrund im sogenannten Detached-Modus ausgeführt. Der sorgt dafür, dass der Docker-Container so lange aktiv bleibt, bis Sie ihn über den Befehl docker stop postgres stoppen. Der Befehl docker start postgres startet ihn erneut.Nachdem Sie nun eine laufende Installation von PostgreSQL in Betrieb haben, stellt sich die Frage, wie Sie auf PostgreSQL zugreifen können. Hierzu gibt es mehrere Möglichkeiten:
- mit dem Kommandozeilen-Tool psql,
- per Azure Data Studio,
- über DBeaver,
- mit pgAdmin.
docker exec
-it --user postgres postgres /bin/bash
Innerhalb der Shell-Session können Sie anschließend das Werkzeug psql starten, das Sie mit der laufenden PostgreSQL-Installation verbindet.Wie Sie in Bild 1 sehen, läuft PostgreSQL im Docker-Container in einer auf Debian basierenden Linux-Distribution. Verwendet wird dabei die PostgreSQL-Version 17, die im Oktober 2024 erschienen ist.
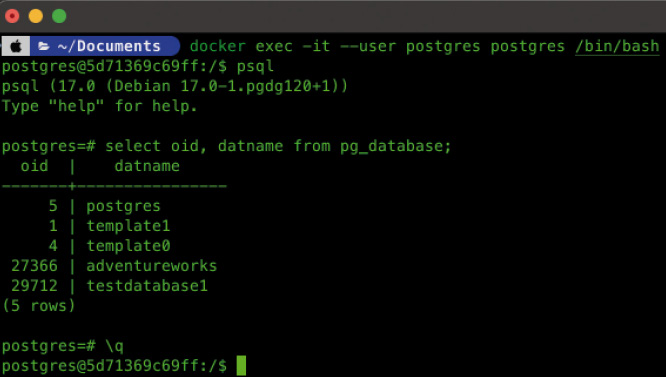
Die laufende PostgreSQL-Installation, angezeigt vom Tool psql (Bild 1)
Autor
Nach dem Aufruf von psql besteht eine aktive Verbindung zur PostgreSQL-Installation, die in einem eigenen Prozess läuft, und Sie können nun SQL-Statements ausführen. Wichtig ist dabei, dass jedes SQL-Statement mit einem Strichpunkt abgeschlossen werden muss. Fehlt der Strichpunkt, gibt es eine Fehlermeldung und das eingegebene Statement wird nicht ausgeführt. Um zu sehen, welche Datenbanken auf der PostgreSQL-Installation vorhanden sind, können Sie durch Abfrage von pg_database die Catalog View einschalten. Jeder Datensatz darin steht für eine Datenbank. pg_database ist vergleichbar mit sys.databases beim SQL Server.Die PostgreSQL-Installation in Bild 1 enthält fünf Datenbanken. Drei davon sind System-Datenbanken und in jeder PostgreSQL-Installation enthalten: postgres, template1 und template0. Die Datenbanken adventureworks und testdatabase1 wurden manuell angelegt. Über den Befehl \q wird das Kommandozeilen-Tool psql beendet, und es erscheint wieder die Kommandozeile des Docker-Containers.Eine weitere Möglichkeit des Zugriffs auf PostgreSQL bietet Azure Data Studio von Microsoft, welches eine passende Extension für PostgreSQL anbietet [3], siehe Bild 2.
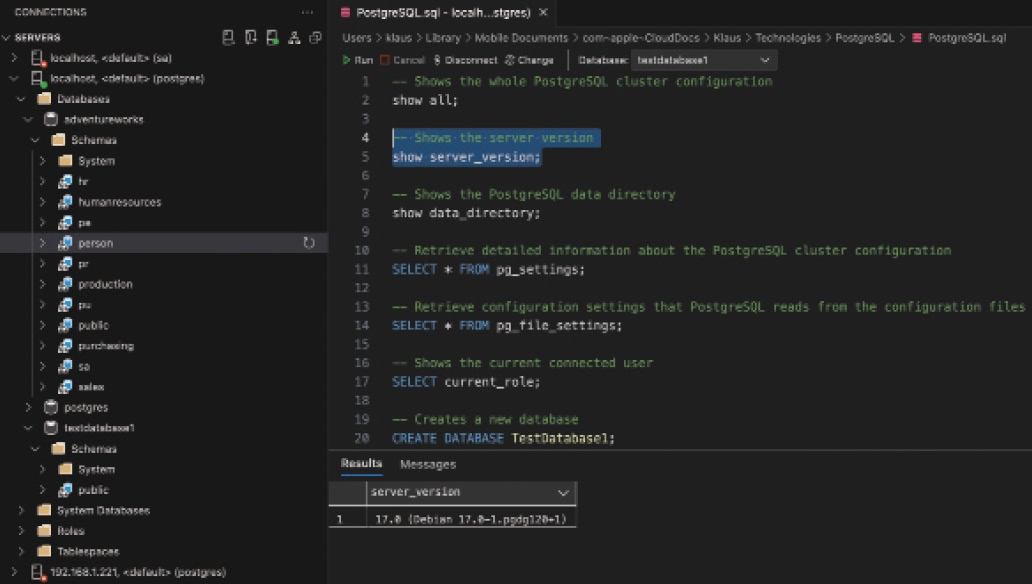
Zugriff auf eine PostgreSQL-Datenbank mit Azure Data Studio (Bild 2)
Autor
Auch das Tool DBeaver bietet Ihnen Zugriff auf PostgreSQL, und es unterstützt überdies weitere Datenbanken – auch den SQL Server. PostgreSQL bietet für diesen Zweck ein eigenes Tool namens pgAdmin [5] an, das Sie auch in einem Docker-Container laufen lassen können.Ich persönlich setze primär auf Azure Data Studio und wechsle für Aufgaben, die Azure Data Studio nicht unterstützt, zu DBeaver oder pgAdmin.
Der PostgreSQL Cluster
Nun wird beleuchtet, wie eine PostgreSQL-Installation aufgebaut ist und wie sie sich von SQL-Server-Installationen unterscheidet.Es beginnt schon beim Namen: Eine komplette PostgreSQL-Installation wird als PostgreSQL Cluster bezeichnet. Dieser Cluster besteht aus den System- und Anwendungs-Datenbanken. Der Begriff Cluster hat damit in PostgreSQL eine andere Bedeutung als beim SQL Server. Ab jetzt werde ich nur mehr von einem PostgreSQL Cluster sprechen und nicht mehr von einer PostgreSQL-Installation.Ein wichtiges Werkzeug zum Management eines PostgreSQL Clusters ist pg_ctl. Es erlaubt, den Cluster zu starten, zu stoppen sowie einen Restart durchzuführen. Außerdem können Sie über die Option initdb das Datenverzeichnis des Clusters initialisieren oder mithilfe der Option promote einen Failover von einem Primary Server auf einen Secondary Server durchführen. Bild 3 zeigt die Optionen.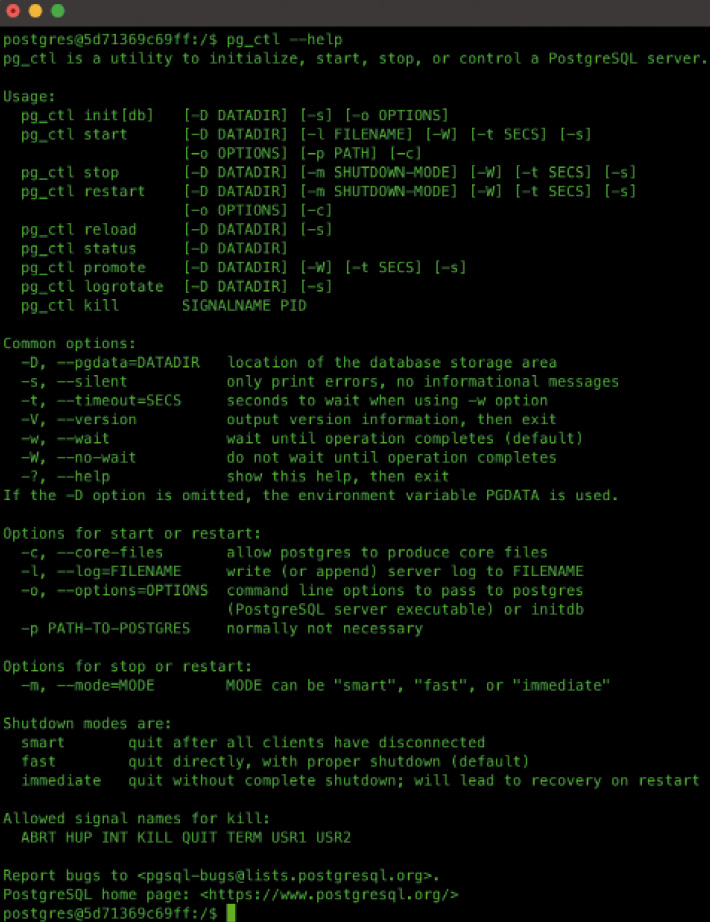
Für diese Aufgaben taugt das Kommandozeilenwerkzeug pg_ctl (Bild 3)
Autor
Sobald Sie den Cluster starten, wird der Hauptprozess von PostgreSQL (der postmaster-Prozess) gestartet. Dieser hat innerhalb eines Docker-Containers immer die PID 1. Neben dem Hauptprozess laufen noch einige andere Prozesse, die regelmäßige Aktivitäten durchführen:
- checkpointer,
- background writer,
- walwriter,
- autovacuum launcher,
- logical replication launcher.
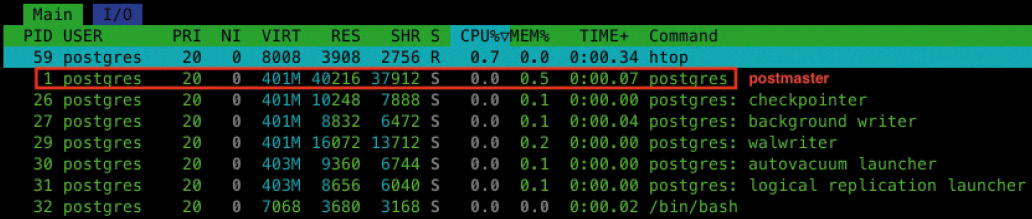
Das Tool htop zeigt die aktiven Prozesse (Bild 4)
Autor
Immer dann, wenn eine neue Datenbankverbindung zu PostgreSQL aufgebaut wird, erstellt der postmaster-Prozess einen neuen Backend-Prozess, der dann exklusiv für diese Datenbankverbindung zuständig ist. Bild 5 zeigt verschiedene Backend-Prozesse für aktive Datenbankverbindungen. Wie Sie in der Abbildung sehen, wurden Backend-Prozesse für zwölf aktive Datenbankverbindungen erzeugt. Ein großer Vorteil dieses Ansatzes ist, dass Datenbankverbindungen voneinander isoliert sind, was bedeutet, dass ein Fehler in einer Datenbankverbindung keinen Einfluss auf andere Verbindungen hat. Die aktuellen Verbindungen können Sie sich auch über die Catalog View pg_stat_activity ausgeben lassen (Bild 6) – diese ist vergleichbar mit sys.dm_exec_connections im SQL Server.
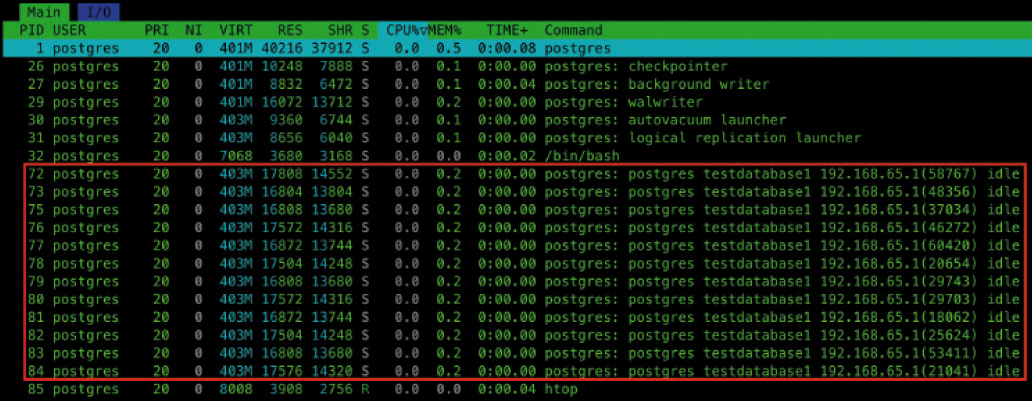
Diverse Backend-Prozesse für aktive Datenbankverbindungen (Bild 5)
Autor
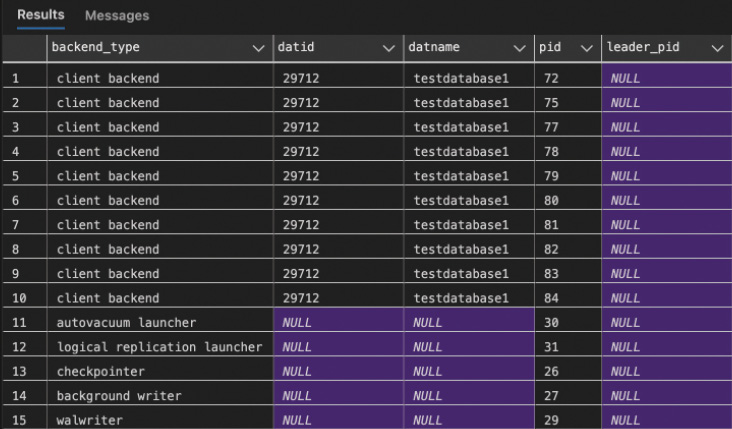
Ausgabe zu * FROM pg_stat_activity (Bild 6)
Autor
SELECT backend_type,
* FROM pg_stat_activity;
Wenn Sie eine neue Verbindung in PostgreSQL öffnen, ist es wichtig zu wissen, dass diese immer auf eine bestimmte Datenbank zielt.Weil es in PostgreSQL keine Master-Datenbank gibt, müssen Sie für den Aufbau einer Verbindung immer auch eine Datenbank angeben.Der Pfad im Dateisystem, in dem sämtliche Daten eines PostgreSQL Clusters gespeichert werden, wird in einer Umgebungsvariablen namens PGDATA gespeichert. Diese zeigt in einem Docker-Container auf das Verzeichnis /var/lib/postgresql/data, bei einer virtuellen beziehungsweise physischen Installation jedoch auf das Verzeichnis /var/lib/postgresql/17/main, siehe Bild 7. Dieser Ordner enthält alle Daten, die vom PostgreSQL Cluster verwaltet werden, einschließlich der Konfigurationsdateien, des WAL-Logs, der Tabellen- und Indexdaten sowie anderer wichtigen Systeminformationen.
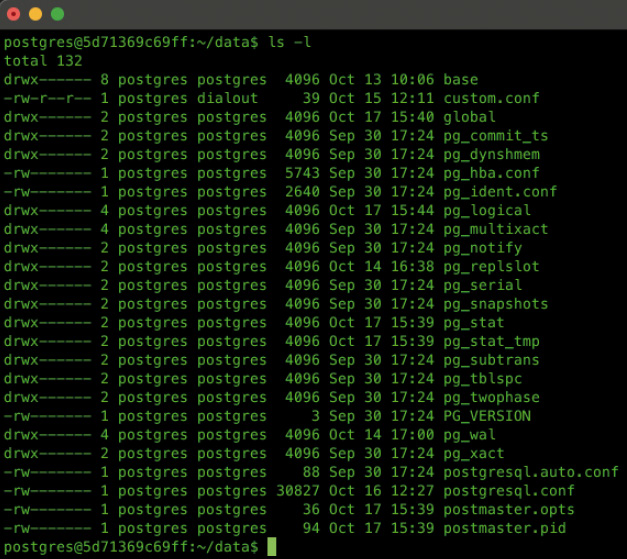
Verzeichnis, das die Daten des PostgreSQL Clusters enthält (Bild 7)
Autor
Bei der Installation eines PostgreSQL Clusters wird das Verzeichnis PGDATA mit dem Befehl inidb initialisiert; entsprechend muss das Verzeichnis beim Start von PostgreSQL als Parameter angegeben werden. Diese Schritte erfolgen beim Erzeugen des Docker-Containers automatisch, müssen aber bei einer virtuellen oder physischen Installation von Hand durchgeführt werden. Tabelle 1 gibt einen Überblick über die wichtigsten Verzeichnisse und deren Zweck.
Tabelle 1: Die wichtigsten Ordner eines PostgreSQL Clusters
|
Die PostgreSQL-Konfiguration
Das Verzeichnis PGDATA enthältneben den Unterverzeichnissen auch die für den Betrieb von PostgreSQL erforderlichen Konfigurationsdateien:- postgresql.conf und
- pg_hba.conf.
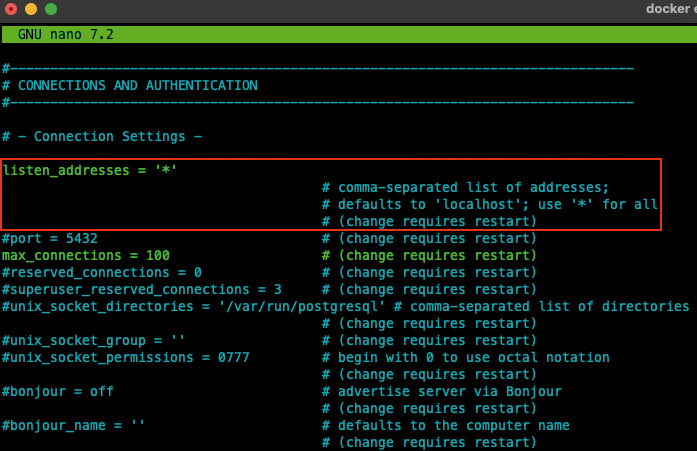
Eine Änderung des Eintrags listen_addresses wird erst nach einem Neustart des Clusters wirksam (Bild 8)
Autor
Die Konfiguration des PostgreSQL Clusters können Sie sich auch mit dem SQL-Befehl show anzeigen lassen. show all liefert alle Konfigurationseinstellungen, und show <setting> beschränkt die Ausgabe auf die angegebene Einstellung. Hier ein paar Beispiele, deren Ausgabe Sie in Bild 9 sehen:
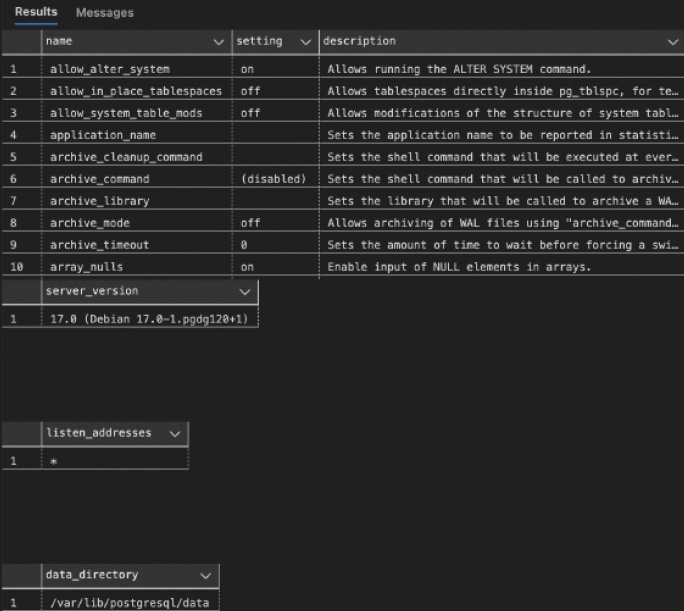
Die Konfiguration mit show anzeigen (Bild 9)
Autor
-- Shows the whole PostgreSQL cluster configuration
show all;
-- Shows the server version
show server_version;
-- Shows the IP addresses under which PostgreSQL
-- is accessible
show listen_addresses;
-- Shows the PostgreSQL data directory
show data_directory;
Damit sich ein Benutzer erfolgreich mit einem PostgreSQL Cluster verbinden kann, muss der Host-Based Access (HBA) in der Datei pg_hba.conf richtig konfiguriert sein. Standard ist in PostgreSQL die Peer Authentication für den Benutzer postgres, wodurch sich dieser nur lokal über das Unix-Konto postgres anmelden kann.Um beispielsweise jedem Benutzer aus dem Subnetz 192.168.1.0/24 den Zugriff auf jede Datenbank zu erlauben, müssen Sie in der Datei pg_hba.conf den in Bild 10 rot markierten Eintrag hinzufügen.
In der Datei pg_hba.conf den Zugriff über das Subnetz 192.168.1.0/24 freischalten (Bild 10)
Autor
Eine weitere Besonderheit besteht darin, dass bei einer Installation, die nicht mit Docker durchgeführt wurde, der Datenbankbenutzer postgres kein Passwort hat. Für eine erfolgreiche Datenbankverbindung muss allerdings ein Passwort angegeben werden. Daher müssen Sie sich lokal mithilfe von psqlmit dem PostgreSQL Cluster verbinden und mit den folgenden Zeilen ein Passwort setzen:
sudo -u postgres psql
ALTER USER postgres PASSWORD 'passw0rd1!';
\q Speicherverwaltung bei PostgreSQL und SQL Server
Die Speicherverwaltung ist ein zentraler Aspekt der Leistung jeder Datenbank und stellt sicher, dass Daten effizient im Arbeitsspeicher bereitgehalten werden, um langsame Zugriffe auf das Storage-Subsystem zu vermeiden.PostgreSQL stellt dazu die Einstellung shared_buffers und SQL Server die Einstellung max_server_memory zur Verfügung. Diese beiden Einstellungen erfüllen ähnliche Zwecke, werden jedoch auf grundlegend unterschiedliche Weise gehandhabt.Die Einstellung shared_buffers in PostgreSQL bestimmt die Größe des Hauptspeichers, den PostgreSQL für den Buffer-Pool reserviert, in denen oft angeforderte Daten und Indexseiten zwischengespeichert werden. Dieser Hauptspeicherbereich wird zwischen den PostgreSQL-Prozessen über Shared Memory geteilt.Der Speicherbereich dient dazu, Daten direkt aus dem Arbeitsspeicher zu lesen, indem die Daten vorübergehend im Speicher gehalten werden, bevor auf das Storage-Subsystem zugegriffen wird.Im Gegensatz zum SQL Server verwendet PostgreSQL den Page Cache des Betriebssystems, der einen Großteil des Cachings der Daten übernimmt, die aus dem Storage-Subsystem gelesen werden.Daher ist die allgemeine Empfehlung, die Einstellung shared_buffers auf etwa 25 Prozent des verfügbaren Arbeitsspeichers zu setzen, während der Rest des Speichers dem Betriebssystem überlassen wird, um die Datei- und Speicherverwaltung zu optimieren. Dieser Ansatz stellt sicher, dass das Betriebssystem über ausreichend Speicher verfügt, um Daten zwischenspeichern zu können, die nicht im Buffer Pool gehalten werden.Im Vergleich mit PostgreSQL verfolgt SQL Server einen deutlich anderen Ansatz für die Speicherverwaltung. Die Einstellung max_server_memory legt den maximalen Speicher fest, den SQL Server für sich selbst reservieren darf. Dieser Speicher umfasst den Buffer Pool, der für die Zwischenspeicherung von Tabellen- und Indexdaten im Speicher verantwortlich ist. Microsoft SQL Server versucht, den Großteil des für Daten benötigten Speichers im eigenen Buffer Pool zu verwalten, anstatt sich auf das Betriebssystem zu verlassen.Die Empfehlung beim Betrieb des SQL Servers ist es, 80 bis 90 Prozent des verfügbaren Arbeitsspeichers für den Buffer Pool zu reservieren. Dies liegt daran, dass SQL Server seine Speicherverwaltung selbst übernimmt und den Page Cache des Betriebssystems umgeht. Durch diese Arbeitsweise kann SQL Server seine Speicherressourcen besser kontrollieren und optimieren.Nach einer Standard-Installation von PostgreSQL ist die Einstellung shared_buffers auf 128 MB gesetzt, siehe Bild 11.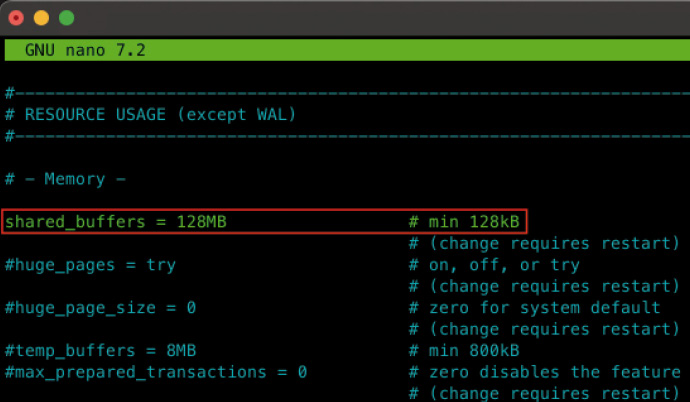
Die Standardeinstellung für shared_buffers: 128 MB (Bild 11)
Autor
Ihre erste PostgreSQL-Datenbank
Nachdem Sie die Grundkonzepte von PostgreSQL kennengelernt haben und auch die wichtigsten Unterschiede zum SQL Server bekannt sind, geht es nun darum, wie Sie Ihre erste Datenbank mit PostgreSQL erstellen.Jeder neu installierte PostgreSQL Cluster besitzt die Datenbank postgres, mit der Sie sich verbinden können, um per SQL-Befehl CREATE DATABASE eine neue Datenbank anzulegen. Listing 1 zeigt ein Beispiel dazu.Listing 1: Eine neue Datenbank anlegen
-- Creates a new database
CREATE DATABASE TestDatabase1;
-- Lists all the databases
SELECT * FROM pg_database
WHERE datistemplate = false;
-- Returns the size of a given database
SELECT
pg_database_size('testdatabase1'),
pg_size_pretty(
pg_database_size('testdatabase1'));
Sobald die neue Datenbank angelegt ist, listet die Catalog View pg_database einen Eintrag dafür. Die aktuelle Größe der Datenbank lässt sich zum Beispiel durch Aufruf von pg_database_size ermitteln.Jedes Objekt (Datenbank, Tabelle, Index, et cetera) wird in PostgreSQL über einen Object Identifier (OID) eindeutig identifiziert. Hierbei handelt es sich um einen fortlaufenden Integer-Wert.Legen Sie eine neue Datenbank an, wird anhand der OID der Datenbank ein neues Unterverzeichnis im Ordner $PGDATA/base angelegt. In unserem Beispiel hat die Datenbank testdatabase1 die OID 29783, daher trägt auch das neu angelegte Unterverzeichnis diesen Namen, vergleiche Bild 12.
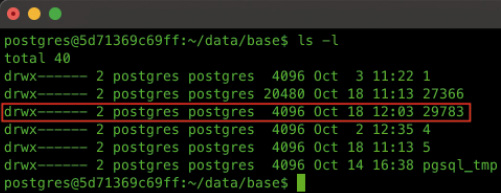
Das Verzeichnis für die neu angelegte Datenbank (Bild 12)
Autor
Innerhalb dieses Verzeichnisses werden nun sämtliche Daten (Tabellendaten, Indexdaten) dieser Tabelle in Form von Dateien abgespeichert. Das ist wieder ein großer Unterschied zum SQL Server, der sämtliche Daten in einem oder mehreren Daten-Files (.mdf, .ndf) abspeichert. Listing 2 zeigt, wie Sie mithilfe des Befehls CREATE TABLE eine neue Tabelle anlegen. Wichtig ist hierbei, dass Sie Ihre Datenbankverbindung zur neu angelegten Datenbank manuell ändern, weil PostgreSQL den Befehl USE nicht kennt, mit dem man beim SQL Server die aktive Datenbank wählt.
Listing 2: Eine neue Tabelle anlegen
-- Create a new table
CREATE TABLE TestTable1
(
Col1 INT NOT NULL,
Col2 VARCHAR(80),
Col3 DATE,
Col4 TIME
);
-- Insert a new record into the table
INSERT INTO TestTable1 (Col1, Col2, Col3, Col4)
VALUES (1, 'Klaus', '2024-01-16', '21:09');
-- Return the records from the table
SELECT * FROM TestTable1;
-- Return the records from the table
SELECT * FROM TestTable1;
-- Retrieve more information of the previous
-- created table
SELECT
oid,
relname,
pg_size_pretty(pg_relation_size('testtable1')),
reltuples,
relpages,
*
FROM pg_class WHERE relname = 'testtable1';
-- Retrieve the file path for the table
SELECT * FROM pg_relation_filepath('testtable1');
Wie Sie im Listing sehen, hat jede erstellte Tabelle einen Eintrag in der Catalog View pg_class und wird über eine OID eindeutig innerhalb der Datenbank identifiziert. Mithilfe der Funktion pg_relation_filepath() ermitteln Sie das Verzeichnis (inklusive Datei), in dem der Inhalt der Tabelle gespeichert wird. In meinem Fall hat die neue Tabelle TestTable1 die OID 29784, daher gibt es auch im Ordner $PGDATA/base/29783 (OID der Datenbank) eine neue Datei. Wie Sie in Bild 13 sehen, hat diese Datei anfangs eine Größe von 8 Kilobyte. Dies entspricht der Standard-Page-Größe von PostgreSQL, die auf Wunsch ebenfalls auf einen anderen Wert gesetzt werden kann.
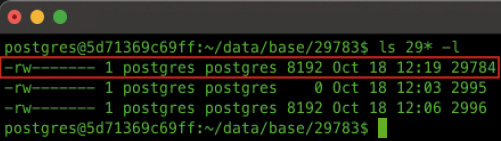
Für die neue Tabelle hat PostgreSQL die neue Datei 29784 erstellt (Bild 13)
Autor
Jede Datei einer Tabelle darf maximal 1 GByte groß werden. Erfordern Tabellen beziehungsweise Indizes mehr Datenspeicher, wird einfach eine neue Datei mit der Dateinamenserweiterung .1, .2, … angelegt. Listing 3 zeigt wie Sie eine größere Tabelle erstellen und mit Daten befüllen. Das Statement INSERT INTO befüllt die Tabelle mit 100 Millionen Datensätzen, wodurch sich eine Gesamtgröße von rund 3,5 GByte für die Tabelle ergibt. Im Dateisystem erfordert diese Tabelle insgesamt vier Dateien (mit der OID 29788), wie Bild 14 zeigt. Neben den Datendateien werden noch zwei weitere Dateien angelegt, nämlich die Free-Space-Map-Datei (.fsm) und die Visibility-Map-Datei (.vm). Die Free-Space-Map-Datei nutzt PostgreSQL, um den freien Speicherplatz auf den Pages einer Tabelle zu verwalten. Diese ist vergleichbar mit der PFS Page (Page Free Space) einer Heap-Tabelle im SQL Server.
Listing 3: Befüllen einer größeren Tabelle
-- Create a larger table
CREATE TABLE LargerTable
(
ID INT GENERATED ALWAYS AS
IDENTITY PRIMARY KEY NOT NULL,
Number INT
);
-- Insert 100m records
INSERT INTO LargerTable (Number)
SELECT generate_series(1, 100000000);
-- Shows the size of a given table
SELECT
pg_size_pretty(pg_relation_size(
'largertable')),
relname,
reltuples,
relpages,
*
FROM pg_class WHERE relname = 'largertable'; 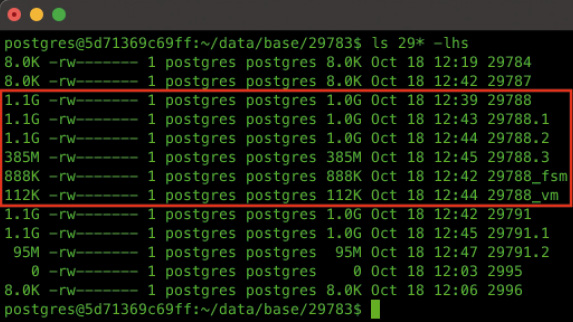
Die 3,5 GByte große Tabelle mit der OID 29788 im Dateisystem erfordert vier Datendateien (Bild 14)
Autor
Die Visibility-Map-Datei speichert, welche Pages einer Tabelle ausschließlich Datensätze enthalten, die für alle aktuellen und zukünftigen Transaktionen sichtbar sind. Diese Datei hilft PostgreSQL dabei, Operationen wie VACUUM und sogenannte Index Only Scans zu optimieren. Mehr dazu erfahren Sie in den nächsten beiden Folgen dieser Serie.
Fazit
Im Rahmen dieses Einführungsartikels haben Sie die Grundlagen von PostgreSQL kennengelernt und gesehen, in welchen Bereichen es sehr große Unterschiede zum SQL Server gibt. Die nächste Folge dieser Serie betrachtet die Indizierung von PostgreSQL-Datenbanken und wie man ein Performance-Tuning durchführen kann.Fussnoten
- PostgreSQL Installation, https://www.postgresql.org/download/
- Installation von PostgreSQL in einer virtuellen Maschine,
- PostgreSQL-Extension für das Azure Data Studio,
- DBeaver, https://dbeaver.io
- pgAdmin, https://www.pgadmin.org











