
17. Jun 2024
Lesedauer 14 Min.
KI ohne eigenen Server
Serverless AI mit WebAssembly und Fermyon Cloud
Interagieren mit LLMs wie Llama2 und CodeLlama, ohne dazu eigene Infrastruktur zu betreiben – dank WebAssembly in einer Vielzahl von Programmiersprachen.

Für viele Entwicklerinnen und Entwickler gehört generative KI bereits zum Alltag. Dank Tools wie ChatGPT, GitHub Copilot oder Amazon CodeWhisperer haben AI-basierte Tools innerhalb kürzester Zeit den Einzug in unseren Alltag geschafft und helfen uns dabei, produktiver zu sein. Daher ist es naheliegend, die durch generative KI gebotenen Möglichkeiten und Potenziale in unsere Software zu integrieren. Dadurch können wir die Produktivität der Endanwender unserer Software erhöhen und sowohl wiederkehrende als auch zeitintensive Aufgaben vereinfachen.Sind Szenarien für die Integration gefunden, gelangt man unausweichlich zu Fragen rund um den Betrieb von Large-Language-Modellen (LLMs) und der technischen Integration in die existierende Anwendung.Für die großen Cloud-Anbieter ist – zumindest zum jetzigen Zeitpunkt – die Antwort auf Betriebsfragen in der Regel ein Platform-as-a-Service-Dienst (PaaS). Für uns als Kunden hat dies zur Folge, dass wir einen Grundbetrag für die Bereitstellung der notwendigen Dienste zahlen. Kosten für die konkrete Nutzung des Dienstes, für Traffic und für weitere flankierende Cloud-Bausteine können zusätzlich anfallen.Mit Serverless AI gibt es jedoch einen sehr attraktiven alternativen Weg. Zustandslose Sprachmodelle werden hierbei vom Anbieter global bereitgestellt. Als Anwender erhalten wir keine dedizierte Dienstinstanz und müssen im Umkehrschluss auch keine Bereitstellungsgebühr beziehungsweise keinen monatlichen Grundbetrag dafür entrichten. Auch die komplette Verwaltung, Absicherung und Wartung der Plattform werden vom Cloud-Anbieter übernommen. Als Entwickler interagieren wir lediglich mit einem bereitgestellten API und bezahlen nutzungsbasiert.Dank WebAssembly [1], dem Open-Source Projekt Spin [2] und Fermyon Cloud kann die Integration generativer KI in bestehende Software einfach realisiert werden. Bevor wir in das Thema Serverless AI mit WebAssembly und Fermyon Cloud einsteigen, gilt es allerdings noch kurz die elementaren Technologien und Tools kennenzulernen.
WebAssembly und WASI
Bereits im ersten Artikel zum Open-Source-Projekt Spin [3] haben wir die Details rund um WebAssembly (Wasm) und flankierende Projekte wie das WebAssembly System Interface (WASI) [4] erläutert. Daher an dieser Stelle nur eine kurze Erklärung, was Wasm und WASI uns Entwicklern bieten und warum sie so enorm wichtig für die Entwicklung zukunftssicherer Software sind.Mit Wasm sind wir in der Lage, Anwendungen auf der Basis unterschiedlicher Programmiersprachen zu implementieren. Im Vergleich zu anderen Laufzeitumgebungen bietet Wasm folgende Vorteile:- Portabilität: Wasm-Runtimes stehen für sämtliche Plattformen zur Verfügung – vom Browser über den Server und die Cloud bis hin zu Mikrocontrollern. Dadurch können Anwendungen ohne Cross-Compiling überall – unabhängig vom Betriebssystem und von der Plattformarchitektur – ausgeführt werden. WASI stellt hierzu plattformunabhängige APIs bereit, die die Interaktion mit systemspezifischen Schnittstellen wie beispielsweise dem Netzwerk oder Dateisystem vereinheitlichen.
- Sicherheit: Wasm-Module (Anwendungen) werden in einer strikten Sandbox ausgeführt. Der Zugriff auf Ressourcen wie Netzwerk, Umgebungsvariablen oder das Dateisystem muss explizit gewährt werden. Ohne die Zugriffserlaubnis kann das Wasm-Modul diese Ressourcen nicht verwenden.
- Größe: Im Vergleich zu anderen Formaten oder Distributionsmechanismen sind Wasm-Module winzig. Ähnlich wie Maschinencode werden sie in einem kompakten Binärformat gespeichert.
- Geschwindigkeit: Die Stack-Based Virtual Machine von Wasm kann das optimierte Binärformat eines Moduls schnell laden und zur Laufzeit auf vorhandene Hardware-Ressourcen zur Beschleunigung zurückgreifen. Schlussendlich erlangt Wasm dadurch eine nahezu native Ausführungsgeschwindigkeit, die vor allem im direkten Vergleich zu interpretierten oder verwalteten Sprachen beeindruckend ist.
Wasm-Support der unterschiedlichen Programmiersprachen
Bereits heute bieten viele Programmiersprachen Support für Wasm und WASI an. Neben vielen populären Sprachen wie JavaScript, TypeScript, Python, (Tiny)Go, C, PHP, Swift und Rust bringen auch weitere interessante Sprachen wie Zig oder Grain Wasm-Support mit. Das .NET-Team von Microsoft arbeitet aktuell am Wasm-Support; der Fortschritt der Implementierung wird unter [6] protokolliert.Die stetig wachsende Liste an Programmiersprachen mit Wasm- und WASI-Unterstützung verdanken wir nicht zuletzt großen Unternehmen und Hyperscalern wie Microsoft, Google oder Amazon, die sich von WebAssembly versprechen, vorhandene Cloud-Ressourcen effizienter nutzen und mehr Anwendungen parallel auf der gleichen Menge an Hardware betreiben zu können. Viel Grundlagenarbeit und Innovation rund um WebAssembly – wie beispielsweise Programmiersprachen-Support – wird hierbei in einer Non-Profit-Organisation, der Bytecode Alliance [7], gebündelt.Spin
Spin ist das Developer-Tool für Entwickler, um Serverless- oder reaktive Anwendungen auf Basis von WebAssembly zu erstellen. Das Open-Source-Projekt besteht aus drei elementaren Bausteinen, die wir hierzu nutzen:- Developer Tooling: Das Spin CLI ist ein konsistentes und effizientes Command Line Interface, das uns ermöglicht, unabhängig von der gewählten Programmiersprache sämtliche Aufgaben, die bei der Entwicklung von WebAssembly-Anwendungen anfallen, schnell und einfach zu erledigen.
- SDKs: Die sprachspezifischen Spin-SDKs lassen uns als Entwickler geläufige Anforderungen – wie beispielsweise die Interaktion mit Datenbanksystemen – einfach und schnell lösen, ohne hierbei auf rudimentäre Infrastruktur-APIs von WASI zurückgreifen zu müssen.
- Runtime: Das Spin CLI (spin) beinhaltet auch eine Wasm-Runtime (implementiert auf Grundlage von Wasmtime [8]), die wir verwenden können, um Wasm-Anwendungen (oder konkret Spin-Apps) lokal auszuführen.
Fermyon Cloud
Kommen wir nun zu Fermyon Cloud, einer Cloud-Anwendungsplattform für Serverless Functions und Microservices, die auf WebAssembly basieren. Sie ermöglicht es Ihnen, Spin-Anwendungen effizient zu betreiben, ohne sich hierbei um die Cloud-Infrastruktur oder typische Anforderungen wie horizontale Skalierung kümmern zu müssen. Fermyon Cloud wurde für Entwickler konzipiert und folgt dem NoOps-Prinzip. Dadurch können Sie neben dem Betrieb von Spin-Apps ohne manuelle Verwaltung oder Wartung auf wichtige Dienste wie Key-Value Stores, Datenbanken oder auch Large-Language-Modelle (LLMs) zugreifen. Einen kostenlosen Fermyon-Cloud-Account können Sie unter [10] erstellen. Der Betrieb von bis zu fünf Anwendungen ist und bleibt kostenlos.Auf in die Praxis
Nun, da Sie einen groben Überblick über die wichtigsten Bestandteile erlangt haben, können wir in Serverless AI eintauchen, ein einfaches Beispiel implementieren und die unterschiedlichen Betriebsmodelle kennenlernen.Als konkretes Beispiel werden wir ein kleines API implementieren, das das Sprachmodell Llama2 verwendet, um uns alltägliche Fragen beim Entwickeln von Software zu beantworten. Um den Umfang des Artikels nicht zu sprengen, werden wir curl (oder GUI-Alternativen wie beispielsweise Postman) als Client verwenden.Da wir die Spin-App in TypeScript entwickeln werden, sollten Sie die folgenden Tools auf Ihrem System installieren:- Spin: Unter [11] finden Sie eine detaillierte Anleitung, um Spin auf Ihrem System zu installieren.
- Node.js: Unter [12] finden Sie empfohlene Installationswege, um Node.js auf Ihrem System zu installieren.
# Neue Spin-App erstellen
# Wir verwenden das http-ts Template
spin new -t http-ts --accept-defaults dotnetpro-api
# Wechseln in den Ordner der Spin-App
cd dotnetpro-api
# Installieren der Dependencies
npm install
Sofern Sie noch nie mit Spin gearbeitet haben, empfiehlt es sich, sich das generierte Verzeichnis anzuschauen. Neben den sprachspezifischen Dateien wie package.json, package-lock.json, tsconfig.json, webpack.config.js und src/index.ts sollten Sie auch das Spin-Manifest spin.toml entdecken.Das Spin-Manifest beinhaltet grundlegende Informationen und Konfigurationen unserer Spin-App. Das Spin-Manifest hat eine konsistente, einfache Struktur, die unabhängig von der gewählten Programmiersprache ist. Wir werden das Spin-Manifest im Lauf des Artikels noch anpassen, um unserer Anwendung den Zugriff auf das gewünschte LLM zu erlauben.Ohne weiteres Zutun können wir nun die Anwendung kompilieren und ausführen, um den „Spin-Workflow“ zu verinnerlichen. Sie kompilieren jede Spin-App mit spin build und nutzen spin up, um die Anwendung lokal zu starten:
# Spin-App kompilieren
spin build
Building component dotnetpro-api with `npm run build`
...
Finished building all Spin components
# Spin-App lokal starten
spin up
Logging component stdio to ".spin/logs/"
Serving http://127.0.0.1:3000
Available Routes:
dotnetpro-api: http://127.0.0.1:3000 (wildcard)
In einer neuen Terminal-Instanz können Sie die Spin-App mittels curl aufrufen:
# Die Spin-App aufrufen
curl -iX GET http://localhost:3000
HTTP/1.1 200 OK
content-type: text/plain
content-length: 17
date: Sat, 20 Apr 2024 07:03:56 GMT
Hello from TS-SDK%
Nach dem erfolgreichen Test der Spin-App können Sie den laufenden Befehl spin up mittels [Strg]+[C] abbrechen.Nehmen Sie sich einige Minuten Zeit, um sich mit dem Spin-CLI vertraut zu machen. Es gibt auch einige Shortcuts (zum Beispiel spin up --build), dank derer Sie noch schneller zum Resultat gelangen.Schauen wir uns die durch das Template http-ts bereitgestellte Implementierung der Spin-App an (src/index.ts):
import { HandleRequest, HttpRequest, HttpResponse } from
"@fermyon/spin-sdk"
export const handleRequest: HandleRequest = async function
(request: HttpRequest): Promise<HttpResponse> {
return {
status: 200,
headers: { "content-type": "text/plain" },
body: "Hello from TS-SDK"
}
}
Das TypeScript-Modul exportiert die handleRequest-Funktion, die von der Spin-Runtime aufgerufen wird, sobald ein eingehender HTTP-Request der im Spin-Manifest angegebenen Route (route = ”/...”) entspricht.Die Spin-SDKs (hier TypeScript) bieten viele nützliche APIs, um typische Enterprise-Anwendungen zu implementieren. So gibt es zum Beispiel einen HTTP-Router, wodurch sich auch komplexere HTTP-Routing-Szenarien abbilden lassen. Weitere Funktionalitäten der Spin-SDKs können Sie der Spin-Developer-Dokumentation [13] entnehmen. Alternativ schauen Sie sich unter [14] eine Sammlung von wiederkehrenden Enterprise-Architekturen und -Patterns an, die mit Spin implementiert wurden.Bei der Implementierung von HTTP-APIs empfiehlt es sich grundsätzlich, individuelle Datenstrukturen zu nutzen, um eingehende Anfragen korrekt zu validieren und um Antworten immer in einem festen Schema zu senden. Die Datenstrukturen für unser Beispiel sind denkbar einfach. Ausgehend von einer Eingabe des Nutzers (User-Prompt) wollen wir eine vom LLM generierte Antwort zurückgeben. Erstellen Sie hierzu eine neue TypeScript-Datei namens models.ts im src-Ordner und fügen Sie den folgenden Inhalt hinzu:
// Eingehende Datenstruktur
export interface RequestModel {
question: string
}
// Ausgehende Datenstruktur
export interface ResponseModel {
answer: string
tokens: number
}
Importieren Sie die beiden Interfaces in index.ts, um sie nutzen zu können:
import { RequestModel, ResponseModel } from "./models"
Zunächst kümmern wir uns darum, dass unsere Anwendung nur auf korrekte Anfragen reagiert und dem Aufrufer einen passenden HTTP-Status-Code als Antwort liefert, sofern die Anfrage nicht korrekt ist. Hierzu passen Sie die Implementierung der handleRequest-Funktion wie folgt an:
export const handleRequest: HandleRequest = async function
(request: HttpRequest): Promise<HttpResponse> {
if (request.method !== "POST") {
return {
status: 405
}
}
const model = request.json() as RequestModel;
if (!model || !model.question) {
return {
status: 400
}
}
// TODO mit LLM interagieren
// TODO: Echte Response erstellen
return {
status: 200,
headers: { "content-type": "application/text" },
body: "Hello from TS-SDK"
}
}
Wie die Implementierung zeigt, erlauben wir lediglich HTTP-POST-Anfragen. Sollte eine Anfrage mit einer anderen HTTP-Methode empfangen werden, wird der HTTP-Status-Code 405 (Method Not Allowed) als Antwort gesendet.Darüber hinaus prüfen wir, ob die Payload der HTTP-Anfrage dem Schema des RequestModel Interfaces entspricht. Passen die Payload der HTTP-Anfrage und das Interface RequestModel nicht zusammen, wird der HTTP-Status 400 (Bad Request) als Antwort gesendet.
WebAssembly-Sandboxing – explizite Berechtigungen vergeben
Wie bereits zu Beginn des Artikels zu sehen war, wird jedes Wasm-Modul in einer strikten Sandbox ausgeführt und benötigt explizite Berechtigungen, um Ressourcen zu verwenden. Da die LLMs kein Bestandteil unserer Spin-App sind, muss auch dieser Zugriff explizit gewährt werden. Spin vereinfacht den Berechtigungsvorgang hier enorm, denn es genügt, wenn Sie hier die gewünschte Ressource im Spin-Manifest angeben, um der Anwendung die Berechtigung zu erteilen.In unserem Fall möchten wir den Zugriff auf das LLM vom Typ llama2-chat gewähren. Aktualisieren Sie dazu die Konfiguration der Komponente wie im folgenden Snippet:
[component.dotnetpro-api]
source = "target/dotnetpro-api.wasm"
exclude_files = ["**/node_modules"]
ai_models = ["llama2-chat"] Das Inferencing API
Das Spin-SDK bietet Inferencing APIs, die wir verwenden können, um Prompts an ein gewünschtes Sprachmodell zu senden. Um die Inferencing APIs in TypeScript zu nutzen, fügen Sie in index.ts eine weitere import-Anweisung hinzu:
import { Llm, InferencingModels, InferencingOptions }
from "@fermyon/spin-sdk"
Da der finale Prompt neben der empfangenen Anfrage des Nutzers noch Systemanweisungen (System-Prompt) beinhalten wird, kapseln wir das Erstellen des Prompts in die dedizierte Funktion buildPrompt, die einen einfachen String zurückgibt. Ohne weitere Optimierungen können wir den Rückgabewert von buildPrompt an die Llm.infer-Methode übergeben:
// Prompt generieren
const prompt = buildPrompt(model.question);
// Inferencing API aufrufen
const res =
Llm.infer(InferencingModels.Llama2Chat, prompt);
Der Rückgabewert von infer (Typ InferenceResult) besteht aus der Antwort des Sprachmodells (text) und grundlegenden Informationen über die verwendeten Tokens (usage). Dadurch können Sie die Anzahl der verwendeten Tokens für den Prompt mit usage.promptTokenCount und die Anzahl der Antwort-Tokens mit usage.generatedTokenCount erhalten.
Anpassungen mit InferencingOptions
Als optionales drittes Argument können Sie InferencingOptions an die Llm.infer-Funktion übergeben, um das Verhalten des Sprachmodells anzupassen. So können Sie beispielsweise die Antwort des Sprachmodells auf 100 Tokens limitieren und das LLM beim Erstellen der Antworten kreativ werden lassen, indem Sie den Aufruf der Llm.infer-Funktion wie folgt anpassen:
// InferencingOptions definieren
const options = {
maxTokens: 250,
temperature: .8
} as InferencingOptions
// Inferencing mit InferencingOptions
const res = Llm.infer(InferencingModels.Llama2Chat,
prompt, options)
Eine vollständige Liste aller Eigenschaften der InferencingOptions-Schnittstelle erhalten Sie über die Dokumentation des Spin-SDK für TypeScript [15].Bevor wir nun den Prompt konstruieren, passen Sie zuvor noch die Antwort des API für den Erfolgsfall an. Neben der Antwort des Sprachmodells und der Anzahl an generierten Tokens geben Sie die ermittelte Anzahl der Tokens des Prompts als HTTP-Response-Header zurück:
const payload = {
answer: res.text.trim(),
tokens: res.usage.generatedTokenCount
} as ResponseModel
return {
status: 200,
headers: {
"content-type": "application/json",
"x-prompt-tokens": `${res.usage.promptTokenCount}`
},
body: JSON.stringify(payload)
}
An dieser Stelle möchte ich nicht in die Tiefen des Prompt-Engineerings eintauchen – dazu wurden in der dotnetpro jüngst mehrere Artikel veröffentlicht, etwa unter [16] und [17]. Es geht vielmehr darum, zu veranschaulichen, wie Sie eine eingehende Anfrage vom Nutzer um einen – extrem vereinfachten – System-Prompt erweitern und rudimentäre Bedingungen anfügen. Implementieren Sie hierzu die buildPrompt-Funktion, wie sie im folgenden Snippet gezeigt wird:
const buildPrompt = function (userPrompt: string):
string {
return `\
[INST] <<SYS>>
You are an AI sidekick and you help users deepen their
software development knowledge.
Answer the questions as short as possible.
Never write any kind of introduction, greeting, or
sign-off.
Answer must be plain text without any format
instructions.
<</SYS>>
${userPrompt} [/INST]`;
}
Damit ist die Implementierung abgeschlossen. Zur erfolgreichen Ausführung fehlt jedoch noch ein wichtiger Bestandteil: Wir benötigen ein Llama-2-LLM. Die nachfolgenden Abschnitte veranschaulichen drei unterschiedliche Szenarien für den Betrieb einer Spin-App, die mit einem LLM interagieren muss.
Der lokale Betrieb
Der lokale Betrieb oder die sogenannte Inner Loop ist der erste Schritt, um das Beispiel zu betreiben. Hierbei dürfen wir aufgrund limitierter Hardware-Ressourcen allerdings keine atemberaubende Geschwindigkeit erwarten. Es ist durchaus normal, dass eine einfache Interaktion mit dem Sprachmodell mehr als 20 Sekunden in Anspruch nehmen kann. Dennoch erlaubt uns der lokale Betrieb, erste Schritte zu gehen und eine Anwendung mit generativer KI zu testen, und das auch ohne bestehende Netzwerkverbindung.Beim lokalen Betrieb versucht Spin, das Sprachmodell aus dem Unterordner .spin/ai-models der Spin-App zu verwenden. Damit Sie die Sprachmodelle nicht mehrfach auf Ihrem System vorhalten müssen, empfiehlt es sich, diese an einer zentralen Stelle zu speichern und mit symbolischen Links (Symlinks) in die gewünschte Spin-App zu integrieren.Der Download der Sprachmodelle kann, abhängig von Ihrer Internetverbindung, etwas Zeit in Anspruch nehmen, denn die beiden Sprachmodelle Llama2 und Code Llama sind jeweils circa 7 Gigabyte groß. Das folgende Snippet zeigt, wie Sie die LLMs von Huggingface.co [18] herunterladen und in einem neuen Unterordner namens ai-models im Home-Ordner des aktuellen Nutzers speichern:
# ai-models Ordner im Home-Ordner erstellen
cd ~
mkdir ai-models
# In das ai-models Verzeichnis wechseln
cd ai-models
# Download von Llama2-Chat
wget https://huggingface.co/TheBloke/Llama-2-13B-chat-
GGML/resolve/a17885f653039bd07ed0f8ff4ecc373abf5425fd/
llama-2-13b-chat.ggmlv3.q3_K_L.bin
# Download von Code-Llama
wget https://huggingface.co/TheBloke/CodeLlama-13B-
Instruct-GGML/resolve/b3dc9d8df8b4143ee18407169f09bc1-
2c0ae09ef/codellama-13b-instruct.ggmlv3.Q3_K_L.bin
# Umbenennen der Downloads
mv llama-2-13b-chat.ggmlv3.q3_K_L.bin llama2-chat
mv codellama-13b-instruct.ggmlv3.Q3_K_L.bin
codellama-instruct
Um die Sprachmodelle mittels Symlink in unsere Beispiel-Anwendung zu integrieren, nutzen Sie das ln-Kommando:
# Sprachmodelle in Spin-App linken
# In den Ordner der Spin-App wechseln
cd dotnetpro-api
# In den Unterordner .spin wechseln
cd .spin
# Den symlink erstellen
ln -s ~/ai-models ai-models
# Verifizieren des Symlinks
ls -al
lrwxr-xr-x 29 user 20 Apr 09:58 ai-models ->
/Users/user/ai-models
ls -al ./ai-models
.rw-r--r--@ 7.1G user 20 Apr 09:30 codellama-instruct
.rw-r--r--@ 6.9G user 20 Apr 09:26 llama2-chat
Nun können Sie die Spin-App kompilieren, mit spin up --build lokal starten und direkt eine erste Frage an das Sprachmodell senden:
# Anfrage an die lokale Spin-App senden
curl -iX POST -H "Content-Type: application/json" \
-d '{"question": "What is the purpose of
JSON.stringify() in JavaScript"}' \
http://localhost:3000
HTTP/1.1 200 OK
content-type: application/json
x-prompt-tokens: 87
content-length: 88
date: Sat, 20 Apr 2024 10:58:06 GMT
{"answer":"JSON.stringify() converts a JavaScript
object to a JSON string.","tokens":15}
Beim lokalen Betrieb wird das gewünschte Sprachmodell von Spin geladen und die Inferencing-Anfrage bearbeitet. Die tatsächliche Performance der Anfrage hängt enorm von der verwendeten Hardware ab, da das Inferencing beim lokalen Betrieb von der CPU übernommen wird.
Der hybride Betrieb
Im Hybrid-Betrieb lassen wir unsere Spin-App weiterhin auf der eigenen Hardware laufen, lagern den Betrieb des Sprachmodells allerdings an Fermyon Cloud aus. Dadurch lassen sich – insbesondere im Vergleich zum lokalen Betrieb – beeindruckend schnellere Antwortzeiten erlangen.Neben dem kostenlosen Fermyon-Cloud-Account benötigen Sie hierzu das sogenannte Cloud-GPU-Plug-in für Spin. Dazu können Sie jederzeit mit spin plugins list --installed prüfen, welche Plug-ins auf Ihrem System installiert sind. Sollte das Cloud-GPU-Plug-in noch nicht auf ihrem System installiert sein, installieren Sie es mit dem Befehl spin plugins install cloud-gpu --yes.Mit dem Cloud-GPU-Plug-in erhalten Sie das Kommando spin cloud-gpu init. Bei der Initialisierung wird eine Proxy-App in Ihrem Fermyon-Cloud-Account bereitgestellt, die die notwendigen APIs für das Inferencing enthält und Ihnen die Spin-Konfigurationswerte im Terminal ausgibt:
# Cloud-GPU Plugin installieren
spin plugins install cloud-gpu --yes
# Cloud-GPU initialisieren
spin cloud-gpu init
Deploying fermyon-cloud-gpu Spin app ...
Add the following configuration to your runtime
configuration file.
[llm_compute]
type = "remote_http"
url = "<Insert url from cloud dashboard>"
auth_token = "11111111-1111-1111-1111-111111111111"
Once added, you can spin up with the following
argument --runtime-config-file <path/to/runtime/
config>.
Folgen Sie den Anweisungen und kopieren Sie den URL des Cloud-GPU-Proxys aus dem Fermyon-Cloud-Dashboard [19] (Bild 1).
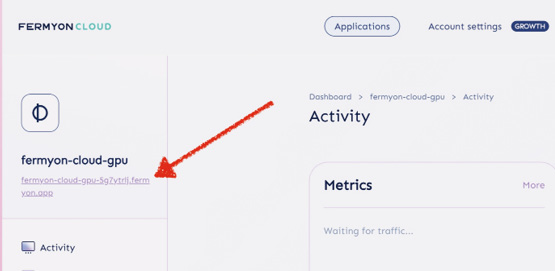
Den URL des Cloud-GPU-Proxys finden Sie im Fermyon-Cloud-Dashboard (Bild 1)
Autor

Erstellen Sie die Datei hybrid.toml im Ordner der Spin-App mit folgendem Inhalt:
[llm_compute]
type = "remote_http"
url = "<Die URL Ihres Cloud-GPU Proxies>"
auth_token = "11111111-1111-1111-1111-111111111111"
Nun starten Sie die Anwendung erneut und geben die neue Runtime-Konfiguration an spin up --runtime-config-file ./hybrid.toml. Senden Sie anschließend eine weitere Anfrage an die lokal laufende Anwendung:
curl -iX POST -H "Content-Type: application/json" \
-d '{"question": "What is the purpose of
object.assign() in JavaScript"}' \
http://localhost:3000
HTTP/1.1 200 OK
content-type: application/json
x-prompt-tokens: 87
content-length: 203
date: Sun, 20 Apr 2024 12:14:19 GMT
{"answer":"In JavaScript, `object.assign()` is used
to copy the properties of one object into another
object. It returns the modified object and can be
used to merge or override properties.","tokens":38}
Im Unterschied zum lokalen Betrieb sollten Sie jetzt innerhalb weniger Sekunden eine Antwort erhalten, da die intensiven Aufgaben an Fermyon Cloud ausgelagert wurden.Mit spin cloud-gpu destroy können Sie den Cloud-GPU-Proxy wieder aus Ihrem Fermyon-Account löschen.
Der Cloud-Betrieb mit Fermyon Cloud
Als dritte Betriebsmöglichkeit steht der gesamte Betrieb in Fermyon Cloud zur Verfügung. Hierbei wird der Cloud-GPU-Proxy nicht benötigt, und auch die Spin-App selbst wird in Fermyon Cloud betrieben.Das Deployment einer Spin-App nach Fermyon Cloud erweist sich hierbei als sehr einfach. Das Spin-CLI stellt die notwendigen Kommandos bereit, um alle Aspekte des Application Lifecycles zu adressieren. Ein einfaches spin deploy genügt, um die Anwendung in Ihren Fermyon-Cloud-Account zu deployen:
# Spin-App nach Fermyon Cloud deployen
spin deploy
Uploading dotnetpro-api version 0.1.0 to Fermyon
Cloud...
Deploying...
Waiting for application to become ready........ ready
View application:
https://dotnetpro-api-zrybfkpg.fermyon.app/
Manage application:
https://cloud.fermyon.com/app/dotnetpro-api
spin deploy ist lediglich ein Alias für spin cloud deploy. Die Liste aller Kommandos zur Interaktion mit Fermyon Cloud erhalten Sie mit spin cloud --help. Passen Sie den curl-Befehl an und senden Sie nun eine Anfrage an die Spin-App in Fermyon Cloud:
# Anfrage an die Spin-App in Fermyon Cloud senden
curl -iX POST -H "Content-Type: application/json" \
-d '{"question": "What is the purpose of macro_rules!
in Rust?"}' \
https://dotnetpro-api-zrybfkpg.fermyon.app/
HTTP/2 200
content-type: application/json
date: Sat, 20 Apr 2024 12:21:21 GMT
x-prompt-tokens: 89
content-length: 148
{"answer":" Macro rules! in Rust serve as a shorthand
for defining a set of macros that can be used to
generate code at compile-time.","tokens":34}
Obgleich curl ein gern genutztes Tool zum Senden von HTTP-Anfragen ist, können Sie die doch sehr bescheidene User Experience zumindest etwas verbessern. Hierzu genügen eine einfache Shell-Funktion sowie das Tool jq:
dnp_ask() {
echo -e ""
payload='{"question": "'$1'"}'
curl -s -X POST -H "Content-Type: application/json"
-d "$payload" https://dotnetpro-api-
zrybfkpg.fermyon.app/ | jq -r ".answer"
}
Wenn Sie die Funktion in Ihrer Shell geladen haben, können Sie wie folgt mit dem kleinen AI-basierten Assistenten interagieren:
dnp_ask "Whats the purpose of io.Writer in Golang?"
In Go, the `io.Writer` type is an interface that pro-
vides a way to write data to a sink, such as a file or
a network connection. It allows for asynchronous I/O
and provides a way to write data in a more flexible
and modular way than using the standard `os` package.
Das Cloud-Betriebsmodell ist natürlich das angenehmste Modell, weil Sie keinerlei Infrastruktur bereitstellen müssen. Darüber hinaus übernimmt Fermyon Cloud die horizontale Skalierung Ihrer Anwendung. Im Fermyon-Cloud-Dashboard können Sie essenzielle Metriken einsehen und Anpassungen an der Spin-App wie beispielsweise die Domain vornehmen.Um die Spin-App aus Fermyon Cloud zu löschen, nutzen Sie das Kommando spin cloud app delete dotnetpro-api.
Zusammenfassung
Serverless AI ist lediglich ein Beispiel, wie WebAssembly und das Open-Source-Projekt Spin es Ihnen ermöglichen, echte Anforderungen zukunftssicher abzubilden. Die bewusst einfach gehaltenen APIs und die Vielzahl unterstützter Programmiersprachen machen auch komplexe Aufgaben wie etwa Inferencing unter Verwendung von Large-Language-Modellen für alle Entwickler zugänglich. Durch die in diesem Artikel gezeigten Betriebsmodelle Lokal, Hybrid und Cloud können Sie generative KI einfach in bestehende, auch verteilte Anwendungsarchitekturen integrieren, ohne hierzu eigene Cloud-Infrastrukturen bereitzustellen, abzusichern und zu warten.Fussnoten
- [1] WebAssembly, https://webassembly.org
- [2] Spin, https://github.com/spinframework/spin
- [3] Thorsten Hans, Wasm außerhalb des Browsers, dotnetpro 3/2024, Seite 46 ff.,
- [4] WebAssembly System Interface (WASI), https://wasi.dev
- [5] Wizer bei GitHub, http://www.dotnetpro.deSL2407ServerlessAI1
- [6] .NET – WASI Developer Experience Goals,
- [7] Bytecode Alliance, https://bytecodealliance.org
- [8] Wasmtime, https://wasmtime.dev
- [9] WebAssembly Component Model,
- Fermyon-Cloud-Account kostenlos einrichten, https://cloud.fermyon.com
- Spin installieren,
- Node.js installieren,
- Spin-Developer-Dokumentation,
- Sammlung wiederkehrender Enterprise-Architekturen und -Patterns in Spin,
- InferencingOptions-Referenz,
- Patrick Schnell, Sparringspartner ChatGPT, dotnetpro 5/2024, Seite 92 ff.,
- Patrick Schnell, Nie mehr lästiges Dokumentieren?, dotnetpro 6/2024, Seite 80 ff.,
- LLM-Download, https://huggingface.co
- Fermyon-Cloud-Dashboard, https://cloud.fermyon.com
Inhalt
- WebAssembly und WASI
- Wasm-Support der unterschiedlichen Programmiersprachen
- Spin
- Fermyon Cloud
- Auf in die Praxis
- WebAssembly-Sandboxing – explizite Berechtigungen vergeben
- Das Inferencing API
- Anpassungen mit InferencingOptions
- Der lokale Betrieb
- Der hybride Betrieb
- Der Cloud-Betrieb mit Fermyon Cloud
- Zusammenfassung









