
16. Sep 2024
Lesedauer 11 Min.
Primitive Obsession in C# vermeiden
Open-Source-Bibliothek StrongOf
Wie Sie mit einfachen Mitteln und einer zusätzlichen Zeile Code schon heute fehlende C#-Sprachfeatures ausgleichen und die Qualität des Quellcodes verbessern können.
Primitive Obsession (zu Deutsch ebenfalls primitive Obsession) ist programmiersprachenübergreifend ein Anti-Pattern beziehungsweise Code Smell [1] in der Softwareentwicklung, das dennoch in fast jeder C#-Codebase zu finden ist – und in der Regel zu hohen Aufwänden oder gar gravierenden und gleichzeitig schwer zu findenden Fehlern führt.Dieses Anti-Pattern ist dann erfüllt, wenn einfache Basis-Datentypen wie Booleans, Strings oder Integer verwendet werden, um komplexe Konzepte, Geschäftswerte beziehungsweise technische Werte zu repräsentieren, und sie damit folgende Probleme verursachen:
- Primitive Datentypen sind nicht eindeutig; die Ausdruckskraft des Wertes ist nicht gegeben.
- Ungültige Zustände entstehen durch invalide Werte.
- Logik muss zwangsweise in weiteren Klassen umgesetzt werden, was oft zu Redundanzen führt.
- Die Wartbarkeit des Codes leidet immens.
- Massiv erhöhte Aufwände bei der Refaktorisierung, Erweiterung und/oder Fehlersuche sowie beim Testen des Codes.
public class Problemstellung
{
// Vereinfachtes Benutzer-Objekt mit
// Eigenschaften als primitive Datentypen
public class User(int userId, string name, int age,
int height, int weight)
{
public int UserId { get; set; } = userId;
public string Name { get; set; } = name;
public int Age { get; set; } = age;
public int Height { get; set; } = height;
public int Weight { get; set; } = weight;
}
Die Benutzer-Klasse User besteht aus vier Eigenschaften, deklariert mit primitiven Datentypen. Vier dieser Datentypen sind als Integer definiert, eine Eigenschaft – der Benutzername – als String.Des Weiteren verfügt diese Klasse über einen Primary Constructor, eine Syntax-Schreibweise, die seit C# 12 zur Verfügung steht [2]. Eine Instanz dieser Klasse kann demnach nur erstellt werden, wenn alle Parameter gegeben sind.Die Instanzierung dieser Klasse und damit die Übergabe der Parameter birgt nun das Risiko, dass Parameter vertauscht werden, da deren Typ identisch ist:
public void Code()
{
UserId userId = new(1);
UserName name = new("Batman");
Age age = new(47);
Centimeters height = new(183);
Kilograms weight = new(84);
// Die Parameter "weight" und "height" sind
// vertauscht.
// Durch die verschiedenen Typen gibt es vom Compiler
// eine Fehlermeldung
User user = new User(userId, name, age, weight,
height);
}
Aus Compiler-Sicht wurden alle Parameter und deren Werte korrekt übergeben – doch aus Logiksicht wurden die Parameter weight und height vertauscht.Oft fällt dieser Fehler während der Entwicklung nicht auf, sondern erst während der Nutzung der Software – oder wenn für jede Parameterübergabe entsprechende Unit-Tests geschrieben werden, was jedoch den Aufwand des Testens erhöht. Eine direkte Compiler-Unterstützung ist an dieser Stelle nicht möglich: Die Datentypen wurden schließlich korrekt behandelt.Ein weiteres Problem dieses Vorgehens ist, dass die Bedeutung der Parameter für den Entwickler ohne weitere Dokumentation nicht eindeutig gegeben ist. Der Parameter name sagt nicht aus, ob dies der Vorname ist, der Nachname oder der vollständige Name – oder eben der Benutzername. Hinzu kommt die Identifikation von Werten, denn allein an der Bezeichnung height beziehungsweise weight wird nicht klar, welche Einheiten – eben Zentimeter beziehungsweise Kilogramm – die Werte besitzen.
Das Konzept der Value Objects
Die konzeptionell einfachste und durchweg sicherste Lösung, solche potenziellen Fehler implizit zu vermeiden und auf diese Weise Folgeaufwände zu verhindern, ist, dass eigene Typen definiert werden; in diesem Fall sogenannte Value Objects [3]. Dabei handelt es sich um Typen, die sich durch drei Eigenschaften maßgeblich von anderen Typ-Implementierungen unterscheiden:- Sie repräsentieren einen eindeutigen Wert, der jedoch auch aus mehreren Werten kombiniert sein kann.
- Ihr beinhalteter Wert ist immutable, der zugewiesene Wert ist nach der Instanzierung also unveränderlich.
- Sie besitzen keine direkte Identität, also zum Beispiel keine ID.
// Value Objects
public record UserId(int Value);
public record class UserName(string Value);
public record class Age(int Value);
public record class Centimeters(int Value);
public record class Kilograms(int Value);
Das Benutzerobjekt verwendet nun keine primitiven Datentypen für die Eigenschaften mehr, sondern die neu definierten Value Objects:
// Definition des Benutzers mit Value Objects
public class User(UserId userId, UserName name, Age age,
Centimeters height, Kilograms weight)
{
public UserId UserId { get; set; } = userId;
public UserName Name { get; set; } = name;
public Age Age { get; set; } = age;
public Centimeters Height { get; set; } = height;
public Kilograms Weight { get; set; } = weight;
}
Werden Parameter beziehungsweise deren Werte bei der Instanzierung vertauscht, kann der Compiler dies nun erkennen und quittiert es, wie in Bild 1 gezeigt, mit entsprechender roter Unterringelung sowie der obligatorischen CS1503-Fehlermeldung, dass die Typen nicht korrekt übergeben wurden.
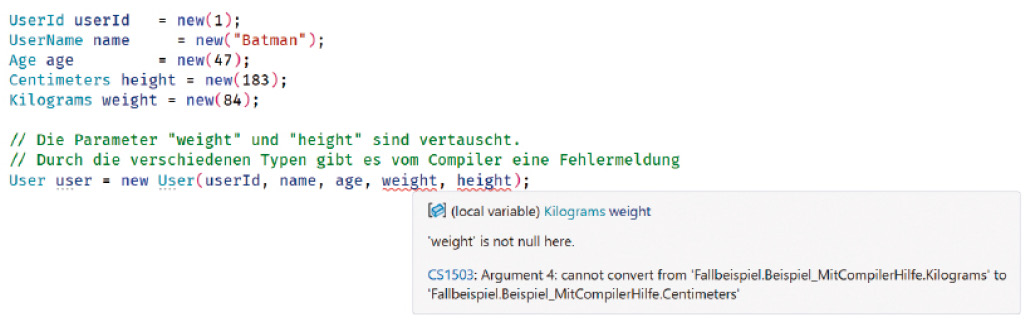
Compiler-Unterstützung bei vertauschten Value Objects (Bild 1)
Autor
Value Objects sind also ein sehr bequemes und zugleich sehr effizientes Mittel, um einfache Flüchtigkeitsfehler zu verhindern und Werten einen eindeutigen Bezeichner zu geben.
Der Overhead von Value Objects
Value Objects als eigener, starker Typ der Klassendefinition haben einen bedeutenden Nachteil: Die Instanzierung erzeugt ein Objekt zur Laufzeit und damit entsprechend auch einen Overhead bei der Allokation von Speicher – wie bei grundlegend jeder Klasse. Bei besonders Performance-relevanten Operationen, bei denen Hunderttausende von Objekten innerhalb kürzester Zeit erzeugt werden, kann sich dies unter Umständen nachteilig auswirken.Die Umsetzung durch Strukturen (struct) statt Klassen wäre hier eine mögliche Abhilfe, jedoch werden Strukturen nicht immer unterstützt – zum Beispiel beim Einsatz mit dem Entity Framework.Besserer Code durch StrongOf
Abhilfe schafft hier die auf GitHub veröffentliche Open-Source-Bibliothek StrongOf [4], die den Umgang mit Value Objects vereinfacht und standardisiert. Jede in StrongOf zur Verfügung stehende Klasse – sowohl für die Definition von eigenen Typen und statischen Klassen als auch von Erweiterungsklassen – verfolgt dabei das grundlegende Ziel, den Umgang mit eigenen Typen beziehungsweise Value Objects zu vereinfachen. Denn der Hauptgrund, warum Primitive Obsession in C#-Quellcode so verbreitet ist, ist vermutlich, dass jeder eigene Typ entsprechend eigene Methoden bräuchte – zum Beispiel Vergleichsmethoden –, um mit ihnen ähnlich bequem umgehen zu können, wie es der Umgang mit primitiven Datentypen bereits ist.StrongOf kann direkt über die .NET-Paketverwaltung NuGet installiert werden, zum Beispiel via Visual Studio (Bild 2). Neben der Hauptbibliothek StrongOf existieren derzeit drei weitere Pakete, die individuelle Szenarien fokussieren: der Umgang mit System.Text.Json für die JSON-Serialisierung, Integration in das ASP.NET-Core-Modelbinding-System, sowie die Verwendung zusammen mit der sehr beliebten Bibliothek FluentValidation.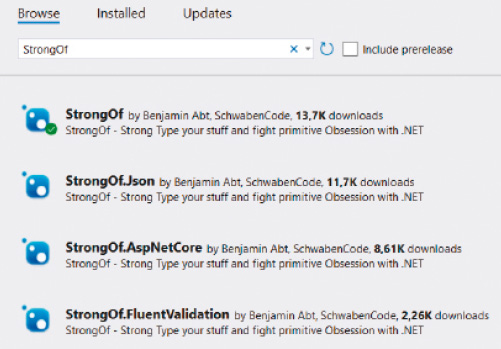
StrongOf-Pakete im Visual Studio NuGet-Explorer (Bild 2)
Autor
Das Hauptpaket StrongOf liefert verschiedene Basisklassen für die Abstraktion eigener Value Objects der primitiven Datentypen, zum Beispiel StrongGuid für die Abstraktion der Benutzer-ID.
// StrongOf
using System.Diagnostics.CodeAnalysis;
using StrongOf;
public class StrongOfSamples
{
public class UserId(Guid Value) :
StrongGuid<UserId>(Value);
public class Kilograms(int Value) :
StrongInt32<Kilograms>(Value);
public class Age(int Value) :
StrongInt32<Age>(Value);
public class UserName(string Value) :
StrongString<UserName>(Value);
StrongOf setzt dabei auf das Prinzip der Vererbung, wobei der definierte Typ – zum Beispiel UserName – als generischer Parameter an den Basistyp – hier StrongString<T> – übergeben wird. StrongString besitzt hier als Basis eine Vielzahl von Methoden, mit denen man beim Umgang mit einem String vertraut ist; dazu gehören Vergleichsmethoden wie Equals, aber auch Manipulationsmethoden wie Trim, ToLower, ToUpper und Co. Alle Methoden der Basisklasse sind damit implizit in der eigenen Typdefinition verfügbar, wie man es vom darunterliegenden Typ – hier string – gewohnt ist.
public void MethodSample()
{
UserName userName = new UserName("Batman");
UserName lowerUserName =
userName.ToLower(); // "batman"
}
Entsprechende Standardmethoden der jeweiligen primitiven Datentypen werden auch für die weiteren Strong-Typen StrongInt32, StrongInt64, StrongDateTime et cetera zur Verfügung gestellt, sodass die Nutzung möglichst standardisiert, ohne zusätzlichen Aufwand und sehr bequem ist.Alle mit StrongOf definierten Klassen agieren zur Runtime als echte Value Objects; der Vergleich zweier Instanzen erfolgt deshalb ausschließlich auf dem Wert und nicht auf der Referenz.Auch hier ist der Mechanismus die Vererbung: Alle Vergleichsanforderungen prüfen hierbei ausschließlich die Werte – sogar gegen primitive Werte. Das bedeutet, dass sich ein StrongString gegen einen string vergleichen lässt, und ebenso ein StrongInt32 gegen ein Integer oder Double, wie es auch direkt mit den primitiven Datentypen der Fall wäre. Dies vermeidet das zusätzliche Erstellen von Instanzen für Vergleichsoperationen.
public void CompareSamples()
{
UserName userName1 = new UserName("Batman");
string userName2 = "Batman";
bool isSame = userName1 == userName2; // true
}
Durch den generischen Vererbungsansatz der Typdefinitionen kann StrongOf zusätzlich statische Klassen sowie Erweiterungsklassen anbieten. Diese Klassen erleichtern den Umgang, sodass kein beziehungsweise nur wenig weiterer Code-Aufwand investiert werden muss, um mit eigenen Value Objects zu arbeiten.Hat man bisher einen String mithilfe von string.IsNullOrEmpty auf Inhalte geprüft, so steht mit StrongOf Strong.IsNullOrEmpty für alle String-basierten Typdefinitionen zur Verfügung:
public void StaticSamples()
{
// statt string.IsNullOrEmpty()
UserName? userName = null;
if (Strong.IsNullOrEmpty(userName))
{
userName = new UserName("Batman");
}
} Validierung von Value Objects
Ein wichtiger Aspekt des Value-Object-Konzepts ist es, dass diese nur instanziert werden sollten, wenn der Wert gültig ist. StrongOf verzichtet von Haus aus bewusst auf die Validierung der Werte, um die Effizienz der Instanzierung nicht negativ zu beeinflussen. Denn in der realen Welt müssen zum Beispiel aus historischen Gründen Instanzen eines Value Objects erstellt werden, obwohl der Wert nach aktueller Definition gar nicht mehr gültig ist. Ebenso sollten stets Instanzen von Value Objects erzeugt werden können, die bereits zum Beispiel in der Datenbank existieren.Ist eine Validierung aktiv gewünscht, empfiehlt sich die Verwendung des in .NET weithin geläufigen Try-Patterns; eine statische Methode, die einen booleschen Wert zurückliefert, ob die Instanz anhand eines Wertes erzeugt wurde oder nicht:
public class Validierung
{
public class Age(int Value) : StrongInt32<Age>(Value)
{
public static bool TryCreate(
int value, [NotNullWhen(true)] out Age? age)
{
// beispielhafte Validierung
if (value is > -1 and < 100)
{
age = new Age(value);
return true;
}
age = null;
return false;
}
}
Dies ermöglicht die Verwendung des eigenen Value Objects sowohl mit einer Validierung als auch ohne diese. Sollte ein komplexes Validierungsergebnis gewünscht sein, kann auch dies als Value Object umgesetzt werden, zum Beispiel mit einer Eigenschaft, ob die Erzeugung selbst erfolgreich war, und einer zweiten Eigenschaft mit einem detaillierteren Fehler, wenn die Erzeugung durch den Wert nicht möglich war.
public void Sample()
{ StrongOf mit dem Entity Framework
Beim Einsatz von Entity Framework oder anderen Bibliotheken sowie bei der Serialisierung zu JSON, XML und Co. muss beachtet werden, dass Value Objects zur Runtime stets einen eigenen Typ darstellen. Dies bedeutet auch, dass in den meisten Fällen ein Konverter deklariert werden muss, damit bei der Übersetzung der jeweilige Serializer weiß, was er tun muss.Das Entity Framework bietet hier die Möglichkeit, sogenannte ValueConverter [5] zu definieren, sodass das Value Object beim Schreiben in die Datenbank in einen primitiven Datentyp – die UserId zu Integer –, mit dem die Datenbank umgehen kann, übersetzt wird beziehungsweise beim Lesen von einem primitiven Typ der Datenbank in das Value Object – der Integer zu UserId – instanziert werden kann.
namespace EntityFrameworkSample
{
using Microsoft.EntityFrameworkCore.Storage
.ValueConversion;
using StrongOf;
public class UserIdValueConverter :
ValueConverter<UserId, int>
{
public UserIdValueConverter(
ConverterMappingHints? mappingHints = null)
: base(id => id.Value, value => new(value),
mappingHints) { }
}
An dieser Stelle ist zu beachten, dass das Entity Framework ausschließlich mit Referenz- und nicht mit Wertvergleichen arbeitet, sodass mit dem Entity Framework nur Klassen und keine Records verwendet werden können [6]. Value Objects mit Wertvergleichen können daher nur für Einzelwerte wie die Abstraktion einer ID – hier UserId – verwendet werden; nicht aber für Relationen beziehungsweise Navigation Properties.
Die Performance von Value Objects
Unweigerlich taucht die Frage auf, wie es um die Performance steht. Denn jeder eigene Typ geht, wie beschrieben, mit einem gewissen Overhead einher, der durch die Instanzierung zustande kommt. Einige mit StrongOf vergleichbare Bibliotheken setzen hierbei auf eine generische Instanzerzeugung; sie verwenden also Varianten wie Activator.CreateInstance() oder Expression.New(), um eine Instanz zu erzeugen.StrongOf bietet zwar mit einer statischen From-Methode eine generische Erzeugung durch Expression.New() an, die für gewisse Szenarien notwendig ist, sieht aber für die generelle Nutzung die Instanzierung der eigenen Typen durch den Konstruktor vor. Die Konstruktor-Varianten sind durchweg mindestens um den Faktor drei effizienter und performanter (Bild 3).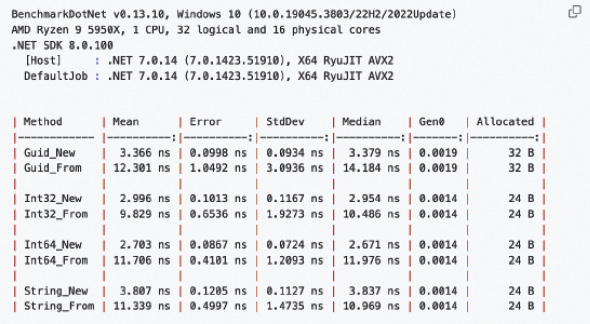
Instanzerzeugungs-Benchmark: Konstruktor versus Expression.New (Bild 3)
Autor
StrongOf im Vergleich
Neben StrongOf existieren weitere Bibliotheken wie Vogen [7] oder StronglyTypedId [8]; doch von diesen unterscheidet sich StrongOf deutlich:- StrongOf setzt auf das Prinzip der Vererbung statt auf Code-Generatoren, um generische Erweiterungen auf einfache Art und Weise zu ermöglichen.
- StrongOf bietet durch die Instanzierung über den Konstruktor eine effizientere Umsetzung an.
- StrongOf bietet bewusst keine direkt eingebauten Validierungsmöglichkeiten, um die Runtime-Effizienz hoch zu halten. Diese müssen bei Bedarf selbst umgesetzt werden (siehe Validierungsbeispiel).
- StrongOf bietet eine eingebaute Unterstützung für alle aktuell existierenden primitiven Datentypen.
- Eigene StrongOf-Ableitungen mit eigenen komplexen Typen sind einfach umsetzbar.
- StrongOf ist leichtgewichtig und besitzt keine eingebetteten Abhängigkeiten zu anderen Bibliotheken.
Extension Types mit C#
Die einfache Vermeidung von Primitive Obsession, wie sie beispielsweise in F# mit Type Abbreviations [9] möglich ist, ist eines der am längsten ersehnten Sprachfeatures von C#. Der früheste aktuell auffindbare Feature Request stammt von 2017 [10] und wurde immer wieder in der Community heiß diskutiert, auf GitHub ebenso wie auf Reddit, aber auch auf Twitter.Mads Torgersen – Lead Designer für C# bei Microsoft – hat es sich nun nicht nehmen lassen, auf der Microsoft Build 2024 im Rahmen der Session „What’s new in C#13“ [11] selbst die wohl größte Neuerung der letzten Jahre vorzustellen: die C# Extension Types (siehe auch [12]). Sie wurden das erste Mal als Sprachfeature – hier noch als simple Bezeichnung „Extensions“ – im November 2021 genannt [13] und seit Dezember 2021 in der Community offen diskutiert [14] [15].Extension Types sind nun genau das, was die Community sich sehr lange gewünscht hat; sie können jedoch viel mehr als bisher bekannte Lösungen wie Type Abbreviations. Mit ihnen wird es zukünftig möglich, einen eigenen Typ im Sinne einer echten Typ-Erweiterung deklarieren zu können.Extension Types werden mit zwei verschiedenen Schlüsselwörtern kommen: implicit beziehungsweise explicit. Die impliziten Deklarationen dienen dazu, bestehende Typen zu erweitern: Sie verhalten sich also ähnlich wie die bereits bekannten Extension Methods [16]. Die jedoch deutlich wichtigere Neuerung sind die explicit extensions: Mit ihnen lassen sich eigene Typen als „leichtgewichtiger Typ“ deklarieren. Hierzu wird ein Typ mit einer neuen Schreibweise deklariert:
public class ExtensionTypes
{
// Es gibt noch keine Compilerunterstützung, daher
// werden Schlüsselwörter rot als Fehler gekennzeichnet.
public explicit extension UserId for Guid
{
public static UserId New() => UserId.NewGuid();
}
Der Extension Type – hier UserId – erweitert den primitiven Datentyp Guid; besitzt also die exakt gleichen Runtime-Eigenschaften und erhält auch alle Methoden, die der Typ Guid besitzt. Zur Compile-Time sind Guid und UserId jedoch unterschiedliche Typen, sodass eine entsprechende Compiler-Unterstützung gewährleistet wird und die Probleme der Primitive Obsession vollständig gelöst sind.Diese eigenen Typen können nun wie gewohnt – wie alle anderen Typen (Klassen, Strukturen, Werte et cetera) – behandelt und in eigenen Value Objects verwendet werden:
public class User
{
public UserId Id { get; set; }
}
Extension Types sollen sich dabei nicht nur auf primitive Datentypen beschränken; vielmehr wird es – nach aktuellem Designstand – zukünftig möglich sein, jede Art von Typen zu erweitern, was immense Auswirkungen auf bisherige Implementierungen in C# hat. Statt einer Vererbung wie
// record Schreibweise
public record class Tier(string Name);
public record class Hund(string Name) : Tier(Name);
public record class Katze(string Name) : Tier(Name);
public record class Maus(string Name) : Tier(Name);
werden – mit allen Vor- und Nachteilen – diese Situationen auch mit Extension Types umsetzbar sein:
public record class Tier(string Name);
public explicit extension Hund for Tier;
public explicit extension Katze for Tier;
public explicit extension Maus for Tier;
Extension Types sind also womöglich wirklich die disruptivste Neuerung – im positiven Sinne – in C#, die wir in den letzten Jahren erhalten haben. Eigentlich angekündigt für den Release von .NET 9 zusammen mit C# 13, werden Extension Types nun voraussichtlich erst mit C# 14 und den ersten Previews von .NET 10 [17] erscheinen.
Fussnoten
- [1] Mark Seemann, Design Smell: Primitive Obsession,
- [2] Microsoft Learn, Primary Constructor,
- [3] Microsoft Learn, Value Objects,
- [4] StrongOf auf GitHub,
- [5] Microsoft Learn, ValueConverter,
- [6] Microsoft Learn, When to use records,
- [7] Vogen auf GitHub,
- [8] StronglyTypedId auf GitHub,
- [9] Microsoft Learn, Type Abbreviations,
- Proposal 410, Type aliases/abbreviations/newtype,
- Dustin Campbell, Mads Torgersen, What’s new in C# 13,
- Microsoft Learn, What’s new in C# 13,
- Proposal 5497, Extensions,
- Proposal 5496, Roles and extensions,
- C# Language Design Meeting for December 11th, 2023,
- Microsoft Learn, Extension Methods,
- Kathleen Dollard, C# 13: Explore the latest preview features,











