
9. Dez 2024
Lesedauer 27 Min.
Kurs auf Kubernetes!
ASP.NET-Core-Applikationen in der Cloud
Erfolgreicher Betrieb von ASP.NET-Core-Applikationen in Kubernetes – Schritt für Schritt.

Kubernetes hat die Cloud-Welt fest im Griff, und fast alle Public-Cloud-Anbieter bieten ihren Kunden Kubernetes als Managed-Lösung an oder setzen intern auf Kubernetes, um ihre PaaS- oder Serverless-Dienste zu betreiben. Oft wird Kubernetes auch im On-Premises Data Center eingesetzt und zeigt genau hier seine Vorteile als Plattform.Zwar unterscheiden sich die Kubernetes-Distributionen und auch die Managed-Service-Angebote in technischen Details zur Installation und unter der Haube mit der Anbindung an Data-Center-Ressourcen wie Netzwerk und Speicher. Für die Applikation hingegen ist die Plattform einheitlich, und bis auf einige Konfigurationsdetails diese kann problemlos auf einem anderen Cluster respektive sowohl in der Cloud als auch in On-Premises-Umgebungen betrieben werden.
.NET-Core-Applikationen ab. Kubernetes ist eine Lösung, um Applikationen in einer Cloud-native-Umgebung zu betreiben. Cloud-native definiert sich mit folgender Charakteristik [1]:
Warum Kubernetes?
Ob und warum man Kubernetes für den Betrieb einer eigenen Applikation einsetzen möchte, ist eine berechtigte Frage, die sich jedes Team unbedingt stellen sollte. Kubernetes hat einen „Coolness“-Faktor, der so manche rationale Entscheidung übersteuern kann und am Ende in viel mehr Aufwand und Komplexität endet. Nicht jedes kleinere Projekt ist zwingend ideal dafür geeignet, in Kubernetes betrieben zu werden. Sind jedoch mehrere Applikationen im Einsatz, die skaliert und ausfallsicher betrieben werden müssen und bei denen feingranulare sicherheitskritische Netzwerkeinstellungen notwendig sind, kann der Betrieb eines Kubernetes-Clusters schnell wieder sinnvoll sein.Beginnen wir aber zunächst ganz von vorne und leiten daraus die Anforderungen und Konsequenzen für unsere ASP-.NET-Core-Applikationen ab. Kubernetes ist eine Lösung, um Applikationen in einer Cloud-native-Umgebung zu betreiben. Cloud-native definiert sich mit folgender Charakteristik [1]:
- On-Demand Self-Service: Der Anwender kann bedarfsabhängig Ressourcen wie Rechenkapazität, Netzwerkzugriff und Speicher bereitstellen. Dies geschieht komplett automatisiert.
- Broad Network Access: Moderne Applikationen sind vernetzt und können von verschiedenen Clients über öffentliche oder private Netzwerke erreicht werden.
- Resource Pooling: Eine Cloud-Plattform stellt ihre Ressourcen abstrahiert in einem Pool mehreren Kunden (bei einer internen Plattform mehreren Teams/Applikationen) zur Verfügung. Diese Ressourcen können bedarfsabhängig gebucht werden, wobei die Details zur physikalischen Infrastruktur nicht bekannt sind.
- Rapid Elasticity: Ressourcen und Funktionen lassen sich rasch und automatisch bereitstellen, damit die Applikationen passend zur aktuellen Nachfrage skaliert werden können.
- Measured Service: Die Ressourcennutzung kann über Schnittstellen überwacht werden und somit auch zur Steuerung verwendet werden.
Architektur
Grundsätzlich lässt sich jeder Applikations-Typ, der im Container läuft, in Kubernetes betreiben. Auch wenn somit klassische Monolithen für Kubernetes kein Problem darstellen, bleiben einem damit viele Vorteile des Clusters fern, und wir schöpfen das Potenzial nicht aus. Mit dem Ziel schneller Skalierbarkeit und Ausfallsicherheit sind Applikationen idealerweise als Microservice-Architekturen konzipiert. Nur so lassen sich individuelle Bereiche dynamisch skalieren, um eine optimale Ressourcenauslastung beziehungsweise -konsumation erreichen. Viele kleine Services tragen auch dazu bei, im Fehlerfall nicht gleich einen Totalausfall der Applikation erleben zu müssen, sondern nur Teilbereiche zu haben, die kurzfristig davon betroffen sind. Ferner können einzelne Services isoliert ausgerollt werden, was das Risiko eines „Big Bang“-Deployments senkt und den Testaufwand massiv reduziert. Wie groß oder klein „Micro“ bei einem Microservice ist, lassen wir hier bewusst offen. Wichtig ist, dass die Services so geschnitten werden, dass sie aus Sicht des Domänenmodells eine logische Kohäsion verfolgen und isoliert ausgeliefert werden können. Kubernetes ist auch in der Lage, kleinste Dienste zu betreiben. Unter Verwendung von KEDA (Kubernetes Event-Driven Autoscaling) [2] können sogar Azure Functions problemlos und effizient betrieben werden. Dies gilt auch bei On-Premises und ganz ohne Azure.Fassen wir die wichtigsten Punkte und Konsequenzen für unsere ASP.NET-Core-Applikation zusammen:- Anstelle eines Monolithen oder eines modularen Monolithen sollten wir die Applikation in Services unterteilen, die isoliert ausgeliefert werden können.
- Ist eine Datenpersistenz notwendig, so ist diese ebenfalls isoliert pro Service zu definieren. Wenn also zum Beispiel eine SQL-Datenbank verwendet werden soll, so hat jeder Service (der Service-Typ, nicht die Instanz) seine eigene Datenbank respektive sein eigenes Datenbankschema. Hätten mehrere Services Zugriff auf die gleiche Datenbank, könnten diese nur zusammen ausgerollt werden, was somit einen impliziten Monolithen darstellen würde.
- Damit wir die Services individuell ausrollen können, sollten alle Schnittstellen immer versioniert werden. Zudem sollte eine Rückwärtskompatibilität für das Gesamtsystem definiert werden, sodass zum Beispiel die letzten drei API-Versionen verfügbar sein sollen. Somit kann auch ein neuer Service noch mit seinem alten Gegenüber sprechen, ohne diesen ebenfalls aktualisieren zu müssen. Wäre dies nicht der Fall, läge ebenfalls ein impliziter Monolith vor.
- Wir überlassen größtenteils Kubernetes die Instanzierung unserer Services. Somit müssen wir bei der Implementierung unserer Applikation davon ausgehen, dass immer eine Vielzahl von Instanzen vorhanden ist, die auch sehr kurzfristig wieder gelöscht werden können. Wir können also keinerlei Persistenz innerhalb des Containers halten und müssen diese über weitere Dienste wie SQL/NoSQL-Datenbanken auslagern. Selbstverständlich bietet Kubernetes die Möglichkeit, persistenten Speicher außerhalb der Container-Instanz zu nutzen.
Health Checks und Monitoring
Im Kubernetes-Umfeld wird oft das Muster „Pets versus Cattle“ referenziert, was also Haustiere und Viehzucht einander gegenüberstellt. Klassisch hat man früher die Applikationen und deren darunterliegende Infrastruktur wie Haustiere gepflegt. Die eine VM mit der Applikationsinstanz wurde über Jahre hinweg unterhalten und aktualisiert und im Fehlerfall wieder zum Laufen gebracht. Bei Kubernetes hingegen sind wir viel distanzierter gegenüber den Applikationsinstanzen und haben in der Regel viele davon. Wir kennzeichnen diese mit einer Ohrmarke und bauen keine persönliche Beziehung zur Instanz auf. Ist die Instanz fehleranfällig, so wechseln wir diese einfach aus, ohne uns groß darüber Gedanken zu machen. Dieses Vorgehen ist weitestgehend automatisiert, da es viel zu viel Arbeit wäre, Hunderte Instanzen zu überwachen und händisch auszutauschen. Damit dies aber funktioniert, benötigt Kubernetes Schnittstellen, damit der Zustand der Applikation ausgelesen und darauf reagiert werden kann. Für die automatische Skalierung brauchen wir zusätzlich noch Metriken, welche die aktuelle Ressourcennutzung bekannt geben.Für Kubernetes ist eine Applikation eine Blackbox. Natürlich kann von außen erkannt werden, ob der Container nicht läuft oder ob das Memory zu 100 Prozent ausgelastet ist. Es gibt jedoch viele Zustände in den Applikationen, die genauso wichtig sind, damit eine korrekte Fehlerbehandlung durchgeführt oder skaliert werden kann. Diese Zustände müssen wir aus unserer Applikation über definierte Schnittstellen nach außen tragen.Als Erstes erweitern wir deshalb unsere Applikation um Health Checks respektive Health Probes. Kubernetes wird unseren Health-Endpunkt periodisch abfragen. Bei einem negativen Liveness-Zustand wird dann Kubernetes den Container respektive den Pod automatisch neu starten. Kubernetes kennt drei verschiedene Health Probes:- Liveness: Mit diesem Check eruiert Kubernetes, ob es der Applikation gut geht, sie also am Leben ist. Ist dieser Check negativ, so wird die Instanz der Applikation neu gestartet.
- Readiness: Es kann sein, dass es unserer Applikation gut geht, jedoch können noch keine Requests verarbeitet werden. Dies ist zum Beispiel der Fall, wenn erst noch Initialisierungslogik durchlaufen werden muss, bevor dann die Endpunkte für die Aufrufer zur Verfügung stehen. Mit diesem Check signalisieren wir, dass der Load Balancer nun Aufrufe auf die Instanz weiterleiten soll.
- � Startup: Gerade bei größeren Services oder Legacy-Anwendungen kann der Applikationsstart ein wenig länger dauern. Wenn nun die Liveness Probe aufgrund des längeren Startups nicht antworten würde, so würde der Container neu gestartet werden, was dann in einer Endlos-Neustart-Schleife enden würde. Über die Startup Probe können wir Kubernetes mitteilen, dass unsere Applikation gestartet wurde und somit die Liveness- und Readiness Probes verwendet werden können.
- Kubernetes stellt ein sehr flexibles Modell für diese Probes zur Verfügung. Es kann mit dem Dateisystem interagiert werden, oder es lassen sich Prozesse im Container ausführen. Zudem gibt es die Möglichkeit, die Probes über einen HTTP-Endpunkt zur Verfügung zu stellen. Da wir eine ASP.NET-Core-Applikation entwickeln, stellt Letzteres klar die einfachste Möglichkeit dar.
Listing 1: Registrierung der Health Checks in der Startup.cs
services.AddHealthChecks()
.AddCheck<StartupHealthCheck>("startup_health_check", tags: new[] { HealthCheckTags.Startup })
.AddCheck<OperationalHealthCheck>("operational_health_check", tags: new[] { HealthCheckTags.Liveness })
.AddCheck<CacheReadyHealthCheck>("cacheready_health_check", tags: new[] { HealthCheckTags.Readiness })
.AddCheck<DatabaseConnectivityHealthCheck>("database_health_check", tags: new[] { HealthCheckTags.Readiness });
Listing 2 enthält die Implementierung eines Health Checks. Die Klasse implementiert das Interface IHealthCheck und muss entsprechend die Methode CheckHealthAsync bereitstellen. Was genau überprüft wird, ist spezifisch für unsere Applikation. Wichtig hierbei ist, dass diese Checks effizient entwickelt werden und durch ihre periodische Ausführung keine zu hohe Last erzeugen. Ferner gilt es dafür zu sorgen, dass nur das überprüft wird, was direkt mit der Applikation zu tun hat, und dass durch die Kubernetes-Aktionen (Restart und Start/Stop Traffic) auch etwas erreicht werden kann. Es bringt also nichts, Service A permanent neu zu starten, wenn Service B nicht erreichbar ist. Dies ist Thema von anderen Mechanismen, um eine Applikation widerstandsfähig zu implementieren. Zu guter Letzt müssen wir nun diese Health Checks noch als Endpunkte zur Verfügung stellen.
Listing 2: Beispiel-Implementierung eines Health Checks
public class DatabaseConnectivityHealthCheck :
IHealthCheck
{
private const string description =
"Sample database ready health check";
private readonly IStorageFactory<IDevFunStorage>
storageFactory;
public DatabaseConnectivityHealthCheck(
IStorageFactory<IDevFunStorage> storageFactory)
{
this.storageFactory = storageFactory ?? throw new
ArgumentNullException(nameof(storageFactory));
}
public async Task<HealthCheckResult>
CheckHealthAsync(HealthCheckContext context,
CancellationToken cancellationToken = new
CancellationToken())
{
using IStorageSession session =
storageFactory.CreateStorageSession();
try
{
IDevJokeRepository repo = session.
ResolveRepository< IDevJokeRepository>();
ReaFx.DataAccess.Common.Repositories.
IPagedEnumerable<Common.Entities.DevJoke>
result = await repo.GetAll(take: 3).
ConfigureAwait(false);
}
catch (Exception ex)
{
return new HealthCheckResult(
HealthStatus.Unhealthy, description, ex);
}
return new HealthCheckResult(
HealthStatus.Healthy, description);
}
}
Listing 3 zeigt die Konfiguration der Endpunkte und weist die verschiedenen Check-Implementierungen anhand ihrer Tags über ein Predicate dem entsprechenden Endpunkt zu. Mittels unserer statischen Methode WriteHealthResponse() können wir die Antwort des Endpunkts anpassen.
Listing 3: Konfiguration der Health-Checks
public void Configure(IApplicationBuilder app,
IWebHostEnvironment env, DevFunStorage storage,
ILogger<Startup> logger)
{
// ...
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
endpoints.MapHealthChecks("/health",
new HealthCheckOptions()
{
ResponseWriter = WriteHealthResponse,
Predicate = (check) => check.Tags.Contains(
HealthCheckTags.Liveness)
});
endpoints.MapHealthChecks("/health/startup",
new HealthCheckOptions()
{
ResponseWriter = WriteHealthResponse,
Predicate = (check) => check.Tags.Contains(
HealthCheckTags.Startup)
});
endpoints.MapHealthChecks("/health/readiness",
new HealthCheckOptions()
{
ResponseWriter = WriteHealthResponse,
Predicate = (check) => check.Tags.Contains(
HealthCheckTags.Liveness) || check.Tags.
Contains(HealthCheckTags.Readiness)
});
endpoints.MapMetrics();
});
// ...
}
private static Task WriteHealthResponse(
HttpContext context, HealthReport result)
{
context.Response.ContentType =
"application/json; charset=utf-8";
JsonWriterOptions options = new()
{
Indented = true
};
using MemoryStream stream = new();
using (Utf8JsonWriter writer = new(stream, options))
{
writer.WriteStartObject();
writer.WriteString("status",
result.Status.ToString());
writer.WriteStartObject("results");
foreach (System.Collections.Generic.KeyValuePair
<string, HealthReportEntry> entry in
result.Entries)
{
writer.WriteStartObject(entry.Key);
writer.WriteString("status",
entry.Value.Status.ToString());
writer.WriteString("description",
entry.Value.Description);
writer.WriteStartObject("data");
foreach (System.Collections.Generic.
KeyValuePair<string, object> item in
entry.Value.Data)
{
writer.WritePropertyName(item.Key);
JsonSerializer.Serialize(
writer, item.Value, item.Value?.GetType() ??
typeof(object));
}
writer.WriteEndObject();
writer.WriteEndObject();
}
writer.WriteEndObject();
writer.WriteEndObject();
}
string json = Encoding.UTF8.GetString(
stream.ToArray());
return context.Response.WriteAsync(json);
}
Mit den Health Checks haben wir die Grundlage für ein System geschaffen, das sich in Kubernetes integrieren kann. Zusätzlich müssen wir uns zwangsläufig auch Gedanken über das Monitoring machen. Monitoring-Lösungen basieren auf drei Pfeilern: Logging, Metriken und Tracing. Hierbei hat sich Open Telemetry als Standard durchgesetzt und deckt die drei Bereiche komplett ab. Open Telemetry kann mittels NuGet der Applikation hinzugefügt werden und sendet dann die Daten entweder über OTLP (Open Telemetry Line Protocol) an einen Collector oder direkt an Dienste wie zum Beispiel Prometheus oder Jaeger.Eine komplette Open-Telemetry-Einführung würde den Rahmen dieses Artikels sprengen, deshalb konzentrieren wir uns auf die Kernkonzepte. Wie wir gelernt haben, sind wir mit einer Vielzahl von Service-Instanzen konfrontiert, die unter anderem auch kurzlebig sein können. Somit wären wir ohne zentrales Logging nicht in der Lage, den Gesamtzustand unserer Applikation zu erfassen. Die einfachste Möglichkeit, Logs aus den Containern zu erhalten, ist, alles auf StdOut und StdErr zu schreiben. Kubernetes speichert die Container-Logs auf dem jeweiligen Node als Datei. Diese Datei kann und wird überschrieben und gelöscht werden. Dementsprechend benötigen wir einen weiteren Dienst, der diese Logs abgreift und zentral speichert. Eine mögliche Variante wäre zum Beispiel der Einsatz von Promtail als Log-Sammler und Loki als zentraler Speicher für die Logs. Bei der Verwendung von Logging-Libraries wie OpenTelemetry oder Serilog lässt sich auch eine entsprechende Sink konfigurieren, welche die Logs direkt in den zentralen Speicher schreibt und nicht auf der Konsole ausgibt. Das Distributed Tracing hilft uns in einer Microservice-Umgebung, die Aufrufe mittels Trace-IDs und Spans zu erweitern, damit wir die Aufrufketten sowie deren Performance analysieren können. Logs können ebenfalls mit den Trace-IDs angereichert werden. Dies hilft uns, die Logs mit den einzelnen Aufrufen zu assoziieren und sie entsprechend für einen spezifischen Aufruf beziehungsweise eine spezifische Aufrufkette zu filtern. Metriken unterstützen uns im Monitoring dabei, die Performance und Auslastung unserer Applikationen zu analysieren. Es gibt Metriken wie zum Beispiel CPU- und Memory Consumption, die ohne Zutun der Applikation erfasst werden können. Interne Request-Laufzeiten sowie benutzerdefinierte Zähler bedingen aber die Integration einer Metrik-Lösung. Somit können wir diejenigen Daten erfassen, die wichtig für unsere Anwendungsfälle sind. Kubernetes kann diese Metriken ebenfalls verwenden, um die Applikation horizontal zu skalieren, also die Anzahl der Instanzen nach oben oder unten zu verändern. Gerade hier ergibt es unter Umständen Sinn, auch eigene Metriken zu berechnen und zu verwenden, da die klassische Skalierung nur auf der Basis von Arbeitsspeicher- und CPU-Auslastung nicht immer ideal ist. Wir können also aus unserem Metrik-System spezifische Werte in das Metrik-API von Kubernetes exportieren, die dann zum Beispiel von einem Horizontal Pod Autoscaler wieder aufgegriffen werden können.
Container
Damit unsere ASP.NET-Core-Applikation in einem Kubernetes-Cluster lauffähig ist, benötigen wir einen Container für unsere Applikation. Generell ist die Containerisierung von Applikationen eine klare Empfehlung, auch ohne den Einsatz von Kubernetes. Ein Container ist das ideale Artefakt, da wir aus unserem CI-Prozess ein versioniertes, unveränderliches Artefakt erhalten, das alle Abhängigkeiten beinhaltet. Die Applikation wird sich somit in der Produktion wie auf dem Testsystem eins zu eins gleich verhalten. Damit eine ASP.NET-Core-Applikation im Container betrieben werden kann, benötigen wir die ASP.NET Core Runtime, die den HTTP-Server Kestrel beinhaltet. Im einfachsten Fall verwenden wir also das ASP.NET-Core-Runtime-Image von Microsoft und fügen eine zusätzliche Applikationsschicht hinzu, welche die Assemblies unserer Applikation im /app-Verzeichnis beinhaltet. Bild 1 veranschaulicht die verschiedenen Schichten eines Containers. Generell ist die Verwendung von Linux-basierten Container-Images zu empfehlen. ASP.NET Core ist Cross-Platform-fähig, und die Linux-basierten Container sind deutlich performanter und ressourcenschonender als ihre Pendants mit Windows. Ein Kubernetes-Cluster kann aber auch mit Windows-Nodes betrieben werden, und somit wären Windows-basierte Container ebenfalls möglich. Diese Option ist jedoch nur dann zu empfehlen, wenn Abhängigkeiten noch nicht auf Linux portiert werden konnten und eine Lift-and-shift-Strategie verfolgt wird, bei der erst einmal alles in einen Cluster migriert wird, bevor die Windows-Abhängigkeiten entfernt werden.
Schichten des Containers (Bild 1)
Autor
Ein Container-Image zu erstellen ist mit verschiedensten Werkzeugen möglich. Das neueste .NET-8-SDK kann direkt Container-Images aus einer Applikation erzeugen, klassisch ist jedoch ein Dockerfile mit einer Docker Build Environment vorhanden, aber auch andere Applikationen wie Podman et cetera sind möglich. Grundsätzlich muss ein OCI-kompatibles Image (Open Container Initiative) erzeugt werden. Die meisten Kubernetes-Distributionen verwenden nicht mehr Docker als Container-Runtime, sondern containerd. Kurzum: Auch wenn man umgangssprachlich von Docker und Docker Images spricht, ist eigentlich immer ein OCI-kompatibles Image oder eine OCI-kompatible Runtime damit gemeint.Im einfachsten Fall kompilieren wir unsere Applikation, kopieren die Assemblies in ein Basis-Image von Microsoft und erstellen ein neues Image daraus. Die Wahl des Basis-Images ist durchaus performance- und sicherheitsrelevant, was wir am Ende des Artikels nochmals aufgreifen werden. Generell gilt: Je kleiner, desto besser, und je weniger Tools und Admin-Rechte, desto sicherer. Zunächst möchten wir uns aber auf den Build-Prozess fokussieren. Da wir ohnehin bereits Container im Einsatz haben, können wir auch gleich unseren gesamten CI-Prozess der Applikation im Container abbilden. Damit unsere Lösung funktioniert, benötigen wir neben dem Kubernetes-Cluster noch eine Container-Registry. Hier werden unsere Images gespeichert. Container-Registries gibt es in allen Formen und Farben. Im Artikel werden wir nicht weiter darauf eingehen und setzen voraus, dass eine entsprechende Container-Registry in unserer Umgebung vorhanden ist. Den Microsoft- und Azure-affinen Lesern sei die Azure Container Registry empfohlen, die alle notwendigen Funktionen zu einem konkurrenzfähigen Preis zur Verfügung stellt.
Optimierung des Build-Prozesses
Bei den meisten Unternehmen hat sich Docker im Entwicklungs-Toolstack eingenistet, und auch Microsoft bietet auf den gehosteten Azure Pipelines Agents oder GitHub Actions Runners einen Docker-Host per Default an. Die Bauanleitung für ein Docker-Image ist das Dockerfile. Darin wird definiert, welches Image als Basis verwendet wird und wie das aktuelle Image darüber gebaut werden muss. Es können einerseits Dateien vom Docker Build Context (also der lokalen Umgebung außerhalb des Containers, zum Beispiel Source-Code-Repository) hineinkopiert werden, oder es lassen sich auch Programme in diesem Layer ausführen.Beim Bauen von Container-Images speichert Docker jeden Zwischenlayer ab. Jedes Kommando, wie etwa RUN dotnet build ”myapp.csproj”, erzeugt einen solchen Zwischenlayer. Wird diese Zeile in einem Build-Prozess erneut ausgeführt, so sieht der Docker-Build erst nach, ob dieser Zwischenlayer bereits im Cache ist, und falls ja, wird direkt der Layer verwendet und das Kommando nicht erneut ausgeführt. Bei einem RUN-Kommando wird der Befehl in String-Form als Cache Key verwendet (Hash). Bei COPY-Befehlen werden alle betroffenen Dateien samt Inhalt in einen Hashwert berechnet. Sobald eine Zeile keinen Cache-Hit hat, werden alle darauffolgenden Zeilen stets zwingend ausgeführt. Dieses Verhalten können wir uns nun zunutze machen und das Dockerfile so schreiben, dass wir bei jedem CI-Prozess möglichst viel aus dem Cache lesen können und somit die Build-Zeit deutlich optimieren können. Da wir sehr oft Code-Änderungen haben, sich jedoch die NuGet-Abhängigkeiten eher selten ändern, können wir den NuGet-Restore in einen eigenen Zwischenlayer auslagern, bevor wir dann kompilieren. So sparen wir uns in einigen Fällen die Zeit für den NuGet-Restore und kompilieren direkt auf dem Zwischenlayer mit den NuGet-Paketen.Damit wir den CI-Build-Prozess in das Dockerfile auslagern können, benötigen wir noch ein zweites Feature: das Multi-Stage-Dockerfile. Ein Dockerfile definiert mit der FROM-Anweisung das Basis-Image, auf dem wir das neue Image bauen. Würden wir also mit einem einzigen Image die Applikation bauen und ausliefern, hätten wir in unserem Ziel-Image auch Compiler-Tools und Entwicklungsabhängigkeiten. Dies wollen wir aber tunlichst vermeiden, da das Image einerseits zu groß werden würde und Entwicklungswerkzeuge auch ein Sicherheitsrisiko im Produktivbetrieb darstellen. Multi-Stage bietet uns die Möglichkeit, im gleichen Dockerfile an mehreren Images zu arbeiten und Dateien zwischen den verschiedenen Images zu kopieren. Einfach gesagt haben wir also ein Build-Image und ein Runtime-Image im Dockerfile. Die kompilierte Applikation wird dann vom Build-Image in das Runtime-Image kopiert, und wir liefern lediglich das Runtime-Image aus. Das Runtime-Image beinhaltet dann nur das Nötigste, was von unserer Applikation gebraucht wird, und ist auch sicherheitstechnisch gehärtet.Listing 4 zeigt das Dockerfile unserer Demo-Applikation „DevFun“ [4], das ein API beinhaltet, um Entwickler-Witze aus einer Datenbank zu lesen und per REST-API einem Frontend zur Verfügung zu stellen. Auf Zeile 8 definieren wir das Build-Image und kopieren auf den Zeilen 11 bis 20 die Projektdateien hinein. Warum nicht den ganzen Source-Code? Wegen des Cachings. Meistens ändert sich der Source-Code, aber nicht die Projektstruktur respektive die NuGet-Dependencies, die ebenfalls in den Projektdateien enthalten sind. Wenn sich diese also nicht geändert haben, kommen diese Zwischenlayer direkt und sehr schnell vom Image-Cache. Die Zeilen 22 bis 31 führen den NuGet-Restore durch, der ebenfalls vom Cache kommen wird, sofern sich die Projektdateien nicht verändert haben. Auf Zeile 32 wird dann der gesamte Source-Code in das Image kopiert und auf Zeile 34 und 35 dann auch kompiliert und auf Zeile 58 in einer eigenen Stage publiziert. Das finale Image wird dann auf Zeile 60 definiert. Mittels des COPY-Befehls mit dem ”--from=publish”-Argument werden die Assemblies aus dem Publish-Image in das Final-Image kopiert. Somit beinhaltet das finale Image lediglich unsere Applikationsdateien. Mit dem Entry Point auf Zeile 68 geben wir noch bekannt, wie unsere Applikation gestartet wird.Listing 4: Dockerfile für eine Backend-Applikation
ARG IMAGE_NET_ASPNET_VERSION=latest
ARG IMAGE_NET_SDK_VERSION=latest
FROM mcr.microsoft.com/dotnet/aspnet:${
IMAGE_NET_ASPNET_VERSION} AS base
WORKDIR /app
EXPOSE 80
FROM mcr.microsoft.com/dotnet/sdk:${
IMAGE_NET_SDK_VERSION} AS build
WORKDIR /src
COPY ["nuget.config", "./"]
COPY ["*.props", "./"]
COPY ["DevFun.Api/DevFun.Api.csproj", "DevFun.Api/"]
COPY ["DevFun.Logic/DevFun.Logic.csproj",
"DevFun.Logic/"]
COPY ["DevFun.Common/DevFun.Common.csproj",
"DevFun.Common/"]
COPY ["DevFun.Storage/DevFun.Storage.csproj",
"DevFun.Storage/"]
COPY ["DevFun.DB.Build/DevFun.DB.Build.csproj",
"DevFun.DB.Build/"]
COPY ["DevFun.Common.Model/DevFun.Common.Model.
csproj", "DevFun.Common.Model/"]
COPY ["DevFun.Clients/DevFun.Clients.csproj",
"DevFun.Clients/"]
COPY ["DevFun.Logic.Unit.Tests/DevFun.Logic.Unit.
Tests.csproj", "DevFun.Logic.Unit.Tests/"]
RUN --mount=type=secret,id=nugetconfig \
dotnet restore --configfile "/run/secrets/
nugetconfig" "DevFun.Api/DevFun.Api.csproj"
RUN --mount=type=secret,id=nugetconfig \
dotnet restore --configfile "/run/secrets/
nugetconfig" "DevFun.Logic.Unit.Tests/
DevFun.Logic.Unit.Tests.csproj"
RUN --mount=type=secret,id=nugetconfig \
dotnet restore --configfile "/run/secrets/nugetconfig"
"DevFun.DB.Build/DevFun.DB.Build.csproj"
RUN --mount=type=secret,id=nugetconfig \
dotnet restore --configfile
"/run/secrets/nugetconfig" "DevFun.Common.Model/
DevFun.Common.Model.csproj"
RUN --mount=type=secret,id=nugetconfig \
dotnet restore --configfile "/run/secrets/
nugetconfig" "DevFun.Clients/DevFun.Clients.csproj"
COPY . .
RUN dotnet build "DevFun.Api/DevFun.Api.csproj"
-c Release -o /app/build --no-restore
RUN dotnet build "DevFun.Logic.Unit.Tests/DevFun.
Logic.Unit.Tests.csproj" -c Release --no-restore
FROM build AS client
ARG BUILDID=localbuild
LABEL client=${BUILDID}
WORKDIR /src
RUN dotnet build "DevFun.Common.Model/DevFun.Common.
Model.csproj" -c Release --no-restore
RUN dotnet pack "DevFun.Common.Model/DevFun.Common.
Model.csproj" -c Release -o /nupkgs --no-restore
RUN dotnet build "DevFun.Clients/DevFun.Clients.csproj"
-c Release --no-restore
RUN dotnet pack "DevFun.Clients/DevFun.Clients.csproj"
-c Release -o /nupkgs --no-restore
FROM build AS dacpac
ARG BUILDID=localbuild
LABEL dacpac=${BUILDID}
WORKDIR /src
RUN dotnet build "DevFun.DB.Build/DevFun.DB.Build.
csproj" -c Release -o /dacpacs --no-restore
FROM build AS test
ARG BUILDID=localbuild
LABEL testresults=${BUILDID}
RUN dotnet test --no-build -c Release --results-
directory /testresults --logger "trx;LogFileName=
test_results.trx" /p:CollectCoverage=true
/p:CoverletOutputFormat=json%2cCobertura
/p:CoverletOutput=/testresults/coverage/
-p:MergeWith=/testresults/coverage/coverage.json
DevFun.Logic.Unit.Tests/DevFun.Logic.Unit.Tests.csproj
FROM test AS publish
RUN dotnet publish "DevFun.Api/DevFun.Api.csproj"
-c Release -o /app/publish --no-restore
FROM base AS final
WORKDIR /app
# Set environment variables for GC (enable server mode # and dynamic adaptation [DATAS])
ENV DOTNET_gcServer=1
ENV DOTNET_GCDynamicAdaptationMode=1
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "DevFun.Api.dll"]
Damit wir den gesamten CI-Prozess im Dockerfile implementieren können, fehlen uns jedoch noch zwei Punkte. Der Docker-Build ist ein isolierter Kontext, der nichts von der Außenwelt respektive der Build-Umgebung weiß. Wenn wir dies zum Beispiel mit Azure Pipelines automatisieren, hat der Agent Zugriff auf Secrets als Environment-Variablen oder auch Zugriff auf Secret Files. Diese Geheimnisse müssen wir dem Docker-Build zur Verfügung stellen. Die NuGet-Feeds, von denen wir unsere Abhängigkeiten beziehen, sind authentisiert. Somit müssen wir diese Credentials dem Docker-Build zur Verfügung stellen. Am einfachsten und sichersten geht dies über Secrets, die seit der Einführung von BuildKit einem Docker-Build zur Verfügung stehen. Auf den Zeilen 22 bis 31 sehen wir, wie wir die NuGet-Konfiguration mit der ID nugetconfig aus den Secrets lesen. Diese Datei steht für den Aufruf unter /run/secrets/<id> zur Verfügung, was wir in diesem Fall als Zielpfad für den --configfile-Parameter definieren. Dem Docker-Build können wir wiederum seitens Pipeline-Automatisierung mittels docker build ---secret id=<mysecretid> die Datei zur Verfügung stellen. Gepaart mit Secret Files in Azure Pipelines haben wir somit eine effiziente und sichere Verwendung der kritischen Konfigurationswerte.Der letzte Punkt, den wir noch lösen müssen, ist das Herauskopieren von Artefakten, die vom Build-Prozess verwendet werden, jedoch nicht im Ziel-Image auftauchen sollten. Unter anderem sind das zum Beispiel Testresultate unserer Whitebox-Tests während des Builds oder das Datenbankschema der Applikation.Am Ende des Docker-Builds erhalten wir unser Ziel-Image mit dem gewünschten Tag in der lokalen Image-Registry, das wir dann in unsere Container-Registry „pushen“ können. Alles, was während des Builds in den Build-Images liegt, liegt in Zwischenimages, die nicht über ein Tag adressiert werden können. Hierzu behelfen wir uns mit einem kleinen Trick. Die Zeilen 52 bis 55 zeigen die Ausführung der Whitebox Test in einer dedizierten Stage. Die Resultate inklusive Coverage werden im Verzeichnis /testresults gespeichert. Damit wir nun diese Dateien von unserer Pipeline her herauskopieren können, setzen wir in diesem Zwischenimage ein Label, wie auf Zeile 54 ersichtlich ist. Das Label verwendet ein Build-Argument. Oft verwenden wir die Build-ID von Azure Pipelines oder GitHub Actions. Hierbei handelt es sich um einen eindeutigen Wert, der bei jeder Pipeline-Ausführung hochgezählt wird. Somit könnten auch mehrere Pipelines auf dem gleichen Docker-Host ausgeführt werden, und wir können dennoch das Zwischenimage zweifelsfrei identifizieren. Listing 5 zeigt, wie wir nun dieses Label verwenden, um das Zwischenimage zu identifizieren, indem wir dieses mit der entsprechenden Filterbedingung suchen. Danach erstellen wir aus dem Image einen Container und kopieren mit dem Befehl cp die Dateien auf den Host. Im Fall von Azure Pipelines können wir anschließend die Testresultate über den Task PublishTestResults hochladen. Damit haben wir nun den gesamten CI-Prozess im Dockerfile hinterlegt. Neben dem Caching haben wir auch unsere Build-Tools vollständig als Container-Images versioniert und referenziert. Somit wird jede Version des Source-Codes mit der passenden Version der Build-Tools kompiliert, da das Dockerfile zusammen mit dem Source-Code versioniert wird.
Listing 5: Dateien aus Zwischenimages herauskopieren
$id=docker images --filter "label=testresults=${{
parameters.buildId }}" -q | Select-Object -First 1
docker create --name testcontainer $id
docker cp testcontainer:/testresults ./testresults
docker rm testcontainer
Docker mit BuildKit baut im Gegensatz zu seinem Vorgänger nur immer einen Pfad bei einem Multi-Stage-Dockerfile. Mit einem einzelnen docker build-Befehl würde somit nur das erste erreichbare Target gebaut werden, oder bei einer expliziten Definition des Targets nur dieses. Wir müssen also den Docker-Build mit gleichem Kontext auf verschiedene Targets mehrfach ausführen. Über das --target-Argument definieren wir, welches Target gebaut werden soll, und bauen tests, clients, dacpac und final. Da wiederum alle bereits erstellten Zwischenimages aus dem Cache kommen, verlieren wir keine zusätzliche Zeit.
Kubernetes-Deployments
Unsere Applikation ist nun bereit für das Kubernetes-Deployment und den Betrieb im Cluster. Die Applikation kann mit mehreren Instanzen betrieben werden, sie hat entsprechende Health-Endpunkte und Monitoring, und unser CI-Prozess erstellt ein optimiertes Container-Image unserer Applikation. Nun müssen wir Kubernetes mitteilen, wie die Applikation zur Laufzeit betrieben werden soll. Kubernetes besteht aus mehreren Nodes, hierbei wird zwischen Master-Nodes und Worker-Nodes unterschieden. Auf den Worker-Nodes läuft unsere Anwendung innerhalb eines Pods. Für jede Instanz der Applikation wird ein Pod erstellt. Wenn also unser Backend-Service aus dem vorherigen Beispiel mit drei Instanzen laufen soll, so sind drei Pods mit dieser Applikation zu Failover- und Lastverteilungszwecken möglichst auf verschiedenen Nodes verteilt. Wie diese Verteilung genau erfolgt, ist Sache der Master-Nodes. Bild 2 veranschaulicht den Aufbau eines Kubernetes-Clusters in einer stark vereinfachten Form. Über den API-Server kommunizieren wir mit dem Cluster und erstellen oder aktualisieren die Konfiguration unserer Applikation. Der Cluster Store speichert die gesamte Cluster-Konfiguration. Kubernetes funktioniert mittels einer Desired-State-Konfiguration, was bedeutet, dass wir den Zielzustand definieren, und der Controller Manager gleicht die Zielkonfiguration mit der Ist-Konfiguration ab und leitet allenfalls Maßnahmen ein, um diesen Zielzustand zu erreichen. Der Scheduler verteilt die Workload auf die zur Verfügung stehenden und passenden Nodes. Auf einem Worker-Node haben wir ebenfalls noch Kubernetes-spezifische Dienste am Laufen. Das Kubelet ist quasi der Agent des Cluster-Controller-Managers; es ist für das Status-Reporting des Nodes verantwortlich und setzt dann die Befehle um. Der cAdvisor verwaltet die Zuteilung der Ressourcen (CPU, RAM) an einen Container. Für die Netzwerkkommunikation ist der Kube-Proxy zuständig. Somit kann über einen Netzwerktreiber ein softwarebasiertes Netzwerk konfiguriert werden.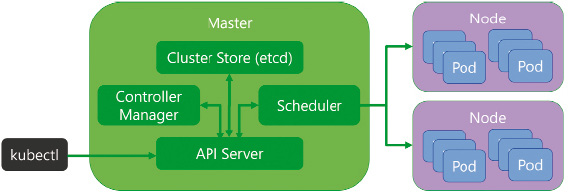
Aufbau eines Kubernetes-Clusters (Bild 2)
Autor
Für unsere Applikation benötigen wir also Kubernetes-Konfigurationsdateien, welche die verschiedenen Eigenschaften beschreiben, die wir für den Betrieb unserer Applikation benötigen. Diese Konfigurationsdateien können wir mit Platzhaltern zur Anpassung während des Deployments direkt zusammen mit dem Source-Code unserer Applikation ablegen. So passt die Applikationsversion auch immer zum Zielzustand des Deployments. Doch welche Konfigurationen benötigen wir? Bild 3 zeigt die Objekte, die klassischerweise für die meisten Applikationen definiert werden müssen. Bevor wir diese geschickt verwalten, klären wir aber erst einmal einige Konzepte, die wir für den Betrieb benötigen.
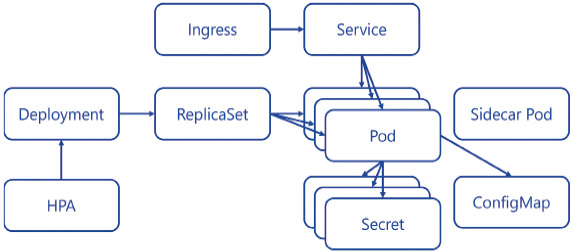
Klassische Kubernetes-Konfiguration für eine Applikation (Bild 3)
Autor
Unser Applikations-Container läuft in einem Pod, der über eine IP-Adresse verfügbar ist. Grundsätzlich können in einem Pod mehrere Container laufen, jedoch nicht zum Zweck der Skalierung (Bild 4). Bei mehreren Containern sind sogenannte Sidecar-Container im Einsatz, die den Haupt-Container unterstützen und zum Beispiel als Proxy eine mTLS-Verbindung mit anderen Pods aufbauen oder aber Building Blocks wie bei Dapr bereitstellen. Generell gilt, dass wir pro Applikationsinstanz einen Pod haben. Diese Pods manuell zu verwalten wäre jedoch viel zu aufwendig, da ja Kubernetes diese überwacht und nötigenfalls austauscht oder skaliert. Entsprechend müssen wir lediglich das Ziel-Deployment mittels eines ReplicaSets oder Deployments beschreiben. Das Deployment bietet gegenüber dem ReplicaSet noch Zusatzfunktionalität wie zum Beispiel die Updatestrategie von Applikationen (Bild 5). Somit ist es möglich, ein Rolling Update zu implementieren, bei dem Pods mit der alten Applikationsversion gegen Pods mit der neuen Version ausgetauscht werden. Darüber hinaus gibt es noch DaemonSets, StatefulSets und CronJobs, was wir jedoch im Rahmen dieses Artikels nicht behandeln. Wir werden ein Deployment verwenden, das definiert, wie die Pods zu konfigurieren sind, und nötigenfalls noch, welche statische Anzahl von Pods wir wünschen. Benötigen wir eine dynamische Skalierung, so ist eine zusätzliche Konfiguration in Form eines Horizontal Pod Autoscalers (HPA) notwendig. Dieser definiert untere und obere Limits der Instanzanzahl sowie eine oder mehrere Metriken, anhand derer automatisch skaliert werden soll. Mit all den dynamischen Pods haben wir ein Problem, wenn wir von Service A nach Service B kommunizieren möchten. Alle diese Pod-Instanzen mit IP-Adressen händisch in der Konfiguration nachzutragen wäre ebenfalls unmöglich. Hier kommt die Service-Konfiguration ins Spiel. Ein Service ist ein statischer Netzwerkendpunkt, welcher die Pods anhand eines Labels identifiziert. Somit können wir einen Service A definieren, der den Traffic an alle Pods der Applikation A weiterleitet (Bild 6). Der Service agiert zudem als Load Balancer und verteilt die Last auf alle Pods. Wann ein Pod für die Netzwerkkommunikation verwendet werden kann, definiert die Readiness Probe, die wir zu Beginn mittels Health Checks implementiert haben. Der Service bietet jedoch lediglich einen Cluster-internen Endpunkt an. Möchten wir den Zugriff auf die Applikation von außen ermöglichen, so benötigen wir eine zusätzliche Ingress-Definition. Dies leitet den öffentlichen Load Balancer an, wie zum Beispiel anhand der Domäne und/oder eines URL-Pfades der Traffic an den entsprechenden Service weitergeleitet wird. Bild 7 veranschaulicht das Zusammenspiel der Komponenten, um unser API im Cluster öffentlich verfügbar zu machen.
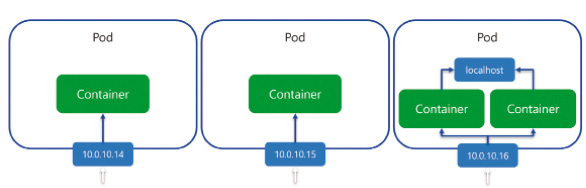
Pods und Container (Bild 4)
Autor
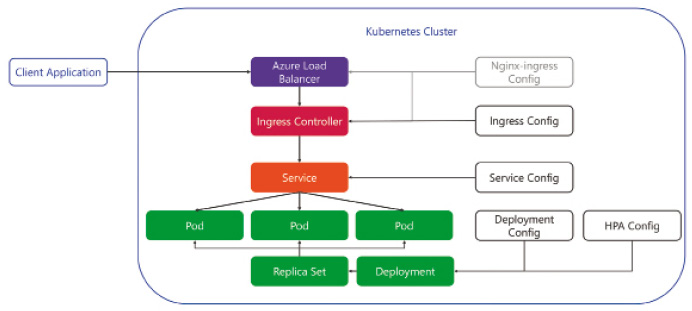
Logische Kubernetes-Komponenten für den Betrieb des API (Bild 7)
Autor
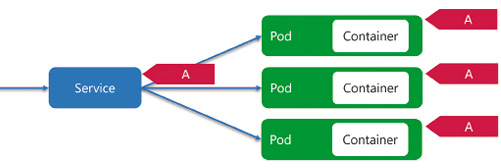
Statischer Netzwerkendpunkt mittels Services (Bild 6)
Autor
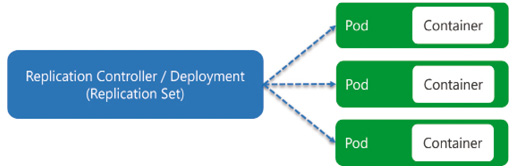
Deployment von Pods (Bild 5)
Autor
Für das Ausliefern unserer Applikation müssen wir nun all diese Konfigurationsdaten an Kubernetes senden. In der Deployment-Konfiguration ist das Container-Image referenziert, das dann von Kubernetes aus unserer Container-Registry geladen wird. Diese Konfigurationsdateien müssen wir dem API-Endpunkt von Kubernetes senden, um den Desired-State unserer Applikation im Cluster zu definieren. Das API kann entweder direkt über REST angesprochen werden, viel einfacher geht dies jedoch mit dem CLI von Kubernetes – kubectl. Die Konfigurationsdaten lassen sich als JSON oder YAML definieren, wobei Letzteres häufiger verwendet wird. Diese Konfigurationsdateien können wir pro Applikation direkt im Git-Repository hinterlegen, damit die Konfiguration ebenfalls versioniert ist.Für jedes Deployment müssen wir jedoch bestimmte Werte ändern, weil sich Werte wie URLs, Connection-Strings oder dergleichen für Deployments in verschiedene Stages oder bei verschiedenen Kunden pro Zielumgebung verändern. Kubectl beinhaltet seit einiger Zeit Kustomize, ein weiteres Werkzeug, um die Konfigurationsdateien zu prozessieren und mittels Overlays, welche die für die Zielumgebung spezifischen Werte enthalten, zu überschreiben.Eine weitere Möglichkeit ist, ein Helm-Paket zu erstellen. Helm ist ein Paketmanager für Kubernetes-Konfigurationen. Alle zusammengehörenden Konfigurationsdateien können versioniert in einem Paket abgelegt und installiert werden. Helm verfügt über eine Template-Engine, die das dynamische Ersetzen von Werten in den Konfigurationsdateien ermöglicht. Über values.yaml lassen sich die konfigurierbaren Werte definieren. Dies dokumentiert gleich auch die Schnittstelle für Anpassungen und beschreibt, welche Werte im Paket konfiguriert werden können. Helm bietet noch viele weitere Vorteile, wie zum Beispiel, dass alle Releases in Kubernetes gespeichert werden und so ein Rollback auf eine ältere Version mit nur einem Kommando möglich ist. Hinzu kommt, dass das Helm-Paket, ein TGZ-Archiv, ebenfalls in einer Container-Registry – als OCI-Artefakt – gespeichert werden kann. Das Helm-CLI kann direkt mit der Container-Registry interagieren und die Pakete auflisten und herunterladen. So erzielen wir einen Zustand, bei dem alle Kubernetes-Artefakte, also die Container-Images sowie die Helm-Pakete zur Konfiguration, allesamt aus einer einzigen Registry geladen werden können.Bild 8 zeigt den Ablauf eines Kubernetes-Deployments mittels Helm. Bild 9 zeigt unsere Beispiel-Solution mit der entsprechenden Helm-Paket-Definition. Jeder der beiden Microservices hat ein Unterverzeichnis charts, das dann das entsprechende Chart – das Helm-Paket – der Applikation beinhaltet. Das Chart verfügt über Metadaten, Konfigurationsparameter und Templates, was die oben genannten Konfigurationsdateien abbilden. Die Template-Dateien enthalten Blöcke mit geschweiften Klammern. Diese sind Anweisungen für die Template-Engine von Helm und werden vor dem Deployment ausgeführt und ersetzt. Entsprechend können Werte aus dem .Values-Objekt gelesen werden, die während des Deployments mit den effektiven Werten entweder per Kommandozeilenparameter (--set) oder über eine dedizierte Overlay-Datei überlagert werden. Wird ein Wert nicht überlagert, so liest die Template-Engine diesen aus der values.yaml-Datei, die im Paket enthalten ist. Aufgrund dessen, dass die Konfigurationsdateien viele Zeilen beinhalten, stellen wir diese wie auch den gesamten Source-Code der Demo-Applikation online auf GitHub zur Verfügung [4].
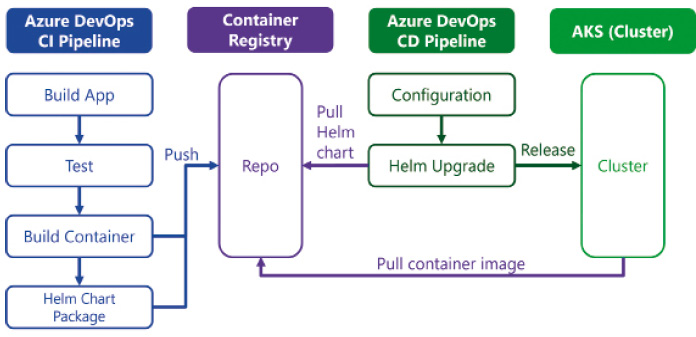
Deployment-Prozess mittels Helm und Container-Registry (Bild 8)
Autor
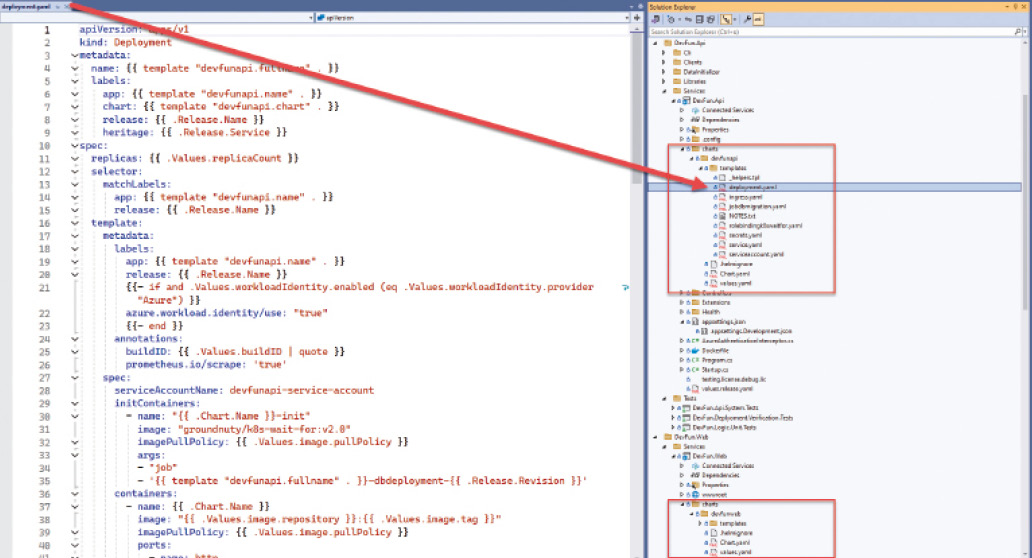
Helm-Charts in der Beispiel-Solution (Bild 9)
Autor
Sicherheit
Der Artikel hat gezeigt, wie wir unsere ASP.NET-Core-Applikation für den Einsatz in einem Kubernetes-Cluster erweitern und den Zielzustand der Applikation im Cluster mittels Helm definieren und ausliefern. Einen Cluster sicher zu betreiben sowie gehärtete Container-Images zu verwenden ist gerade in der heutigen von vielen Angriffen geprägten Zeit enorm wichtig. Die Komplexität all dieser Aspekte sprengt wiederum den Rahmen dieses Artikels, dennoch möchte ich die wichtigsten Punkte im Bereich der Sicherheit von Kubernetes-Anwendungen allen Lesern mit auf den Weg geben.Wie so oft verleitet einen der schnelle Start mit Kubernetes dazu, alles mit einem Super-Admin-Account auf dem öffentlichen API-Endpunkt des Clusters durchzuführen. Gerade bei Clustern in der Public Cloud werden diese Endpunkte von Angreifern gescannt und auf Möglichkeiten der Kompromittierung untersucht. Generell lassen sich in jeder Cloud die API-Endpunkte als private Endpunkte definieren, und sie können somit nur über ein privates virtuelles Netzwerk erreicht werden. Für ein Automatisierungsszenario könnte man so eine kleine VM mit einem Azure Pipelines Agent in dasselbe private Netzwerk ausliefern, und der Agent könnte dann das Cluster-Deployment über den privaten Endpunkt automatisieren. Kubernetes verfügt über eine eigene Benutzer- und Service-Account-Verwaltung (Open ID Connect), welche die Autorisierung über Role-Based Access Control (RBAC) definiert. Somit sollten also bevorzugt spezifische Benutzer für spezifische Anwendungsfälle definiert und konfiguriert werden. Der Cluster sollte in verschiedene Namespaces unterteilt werden, die wiederum durch das RBAC-System spezifisch berechtigt werden können.Neben dem Zugriff auf den Cluster sollten wir auch immer den Betrieb aus Security-Sicht beleuchten. Im Source-Code der Demo-Applikation fällt auf, dass die ASP.NET-Core-Services ohne TLS intern innerhalb des Clusters über Port 8080 verfügbar sind. Die TLS-Terminierung erfolgt zum Beispiel auf dem nginx-ingress-Controller, der den Traffic von außen entgegennimmt und dann intern über HTTP weiterleitet. Natürlich kann man sich nun auf den Standpunkt stellen, dass die Nodes ja in einem privaten virtuellen Netzwerk liegen und man ja kontrolliert, was alles im Cluster läuft. Dennoch könnte eine Drittherstellerkomponente kompromittiert sein und den gesamten unverschlüsselten Kommunikationsverlauf mitlesen. Hier wäre es angebracht, die Cluster-interne Kommunikation ebenfalls zu verschlüsseln. Dies erreicht man relativ leichtgewichtig, in dem man zum Beispiel Dapr einsetzt und mittels Service Invocation eine mTLS-Verbindung von Service zu Service aufbaut. Die Public Key Infrastructure übernimmt hierbei Dapr Sentry.Ähnlich – über Sidecar Proxies –, jedoch mit viel mehr Funktionalität funktionieren Service Meshes. Die Proxies bauen ebenfalls verschlüsselte Tunnels zwischen den einzelnen Pods auf. Ein Service Mesh verfügt über Zusatzfunktionen wie Traffic-Routing und vieles mehr. Beide Varianten unterstützen jedoch Policies, um zu definieren, welche Komponente mit welcher kommunizieren darf. Kubernetes verfügt von Haus aus ebenfalls über Network Policies, mit denen sich wie bei einer Firewall definieren lässt, wo welcher Traffic durch darf. Es kann definiert werden, welcher Pod mit welchem Pod sprechen oder welcher Namespace mit welchem anderen Namespace kommunizieren darf. Es können sowohl Regeln für den eingehenden (ingress) sowie ausgehenden (egress) Traffic konfiguriert werden.Kubernetes verfügt über eine eigene Secret-Verwaltung, damit geheime Werte nicht als Plain Text in den Konfigurationsdateien hinterlegt werden müssen. Über eine SecretRef kann das Secret referenziert und zur Laufzeit eingebunden werden. Zudem können externe Vaults direkt integriert werden. Viel wichtiger ist, dass jeder Pod unter einem dedizierten Service-User läuft. Ist nichts spezifiziert, wird der Default-Service-User verwendet, der für den gesamten Namespace derselbe ist. Somit hätten mehrere Applikationen im gleichen Namespace dieselben Berechtigungen und könnten Konfigurationen auslesen, die nicht die ihrigen sind. Der sicherste Umgang mit Secrets ist ganz einfach, keine Secrets zu haben. Was sich zunächst wie ein Scherz anhört, ist jedoch zum Beispiel im Azure Kubernetes Service (AKS) kein Problem und sollte dort dringend auch so umgesetzt werden. Wie bereits erwähnt hat jeder Kubernetes-Cluster einen eigenen Identity-Endpunkt, und jeder Pod läuft unter einer applikationsspezifischen Identität. Wenn wir jedoch auf externe Dienste wie zum Beispiel einen KeyVault oder eine Azure-SQL-Datenbank zugreifen, wären Secrets im Connection-String notwendig. Dies kann mittels Workload Identity umgangen werden. In Azure kann eine entsprechende Managed Identity eingerichtet werden, die dann mit dem Service-Account des Pods verbunden wird. Somit ist jeder Pod in der Lage, über einen Token Exchange ohne Passwort ein Token vom Entra-Directory zu erhalten. Mit diesem Token kann dann – vorausgesetzt die Managed Identity wurde entsprechend eingerichtet – auf Azure-Ressourcen zugegriffen werden.Auch das Container-Image sollte mit der nötigen Vorsicht erstellt werden. Gerade in der Vergangenheit hatten viele Hersteller ihre Basis-Images direkt mit dem root-Benutzer betrieben. Dies war auch bei Microsoft der Fall und wurde mit .NET 8 korrigiert. Das war auch einer der Gründe, wieso der Default-Port bei ASP.NET Core 8 neu 8080 anstelle von 80 ist. Um den Port 80 zu binden, sind nämlich root-Rechte notwendig. Generell sollten wir also immer anstreben, dass unsere Applikationen ohne root-Rechte im Container lauffähig sind. Zudem sollten wir auch sicherstellen, dass möglichst keine anderen Werkzeuge im Container installiert werden, die ein Angreifer nutzen könnte. Um kleinere Basis-Images zu erhalten und im gleichen Zug die Sicherheit zu erhöhen, hat Microsoft zusammen mit Canonical die „Chiseled Ubuntu Containers“ für ASP.NET Core eingeführt. Diese Chiseled-Container sind auf das Minimum reduziert. Aus Security-Sicht ist hervorzuheben, dass diese Images ohne Shell und ohne Package Manager daherkommen und als Non-root-Images publiziert werden. Ein Angreifer kann keine Skripts ausführen und auch keine Pakete nachinstallieren, da er keine root-Rechte besitzt und kein Package-Manager installiert ist. Zudem werden die App-Files zum Erstellungszeitpunkt als root kopiert, der Applikationsbenutzer hat somit nur Lese- und Ausführungsberechtigungen, was es ebenfalls verunmöglicht, die Applikationsdateien bei einem Angriff auszutauschen oder zu aktualisieren. Um Chiseled Images zu verwenden, muss lediglich das FROM-Statement für das finale Image angepasst werden (siehe Listing 6). Dabei ist zu beachten, dass verschiedene Tags für die Chiseled Images vorhanden sind, die mehr oder weniger Abhängigkeiten beinhalten. Wird zum Beispiel Entity Framework Core verwendet, ist zwingend das -extra-Image zu verwenden, da dieses den ICU-Lib-Support für die notwendige Lokalisierung beinhaltet.Listing 6: Verwendung von Chiseled Images
FROM mcr.microsoft.com/dotnet/aspnet:${IMAGE_NET_
ASPNET_VERSION}-jammy-chiseled-extra AS final
WORKDIR /app
# Set environment variables for GC (enable server
# mode and dynamic adaptation [DATAS])
ENV DOTNET_gcServer=1
ENV DOTNET_GCDynamicAdaptationMode=1
COPY --from=publish /app/publish .
ENTRYPOINT ["dotnet", "DevFun.Api.dll"]
Kubernetes-technisch kann zudem noch der Security Context explizit definiert werden. So ist sichergestellt, dass der Container nicht mit erweiterten Rechten betrieben werden kann, unabhängig davon, was im Container definiert ist. Hierzu wird in der Container-Definition im Deployment der Security Context gesetzt. Listing 7 zeigt eine mögliche Definition des Security Contexts.
Listing 7: Security Context
securityContext:
runAsNonRoot: true
runAsUser: 899
runAsGroup: 899
privileged: false
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL Fazit
Applikationen in Kubernetes zu betreiben ergibt ab einer gewissen Größe und Komplexität der Applikationslandschaft durchaus Sinn. Kubernetes liefert viele Antworten, um gängige Herausforderungen im Betrieb von Microservice-Anwendungen zu meistern.Damit wir unsere ASP.NET-Core-Applikationen optimal in einem Cluster betreiben können, müssen diese die notwendigen Informationen wie Health Probes liefern und sollten über ein Monitoring-System überwachbar sein. Die Zeiten, in denen Applikationen mit nur einer Instanz betrieben wurden, sind mit einem Cluster definitiv vorbei. Wir wollen Ausfallsicherheit, Lastverteilung und bedarfsabhängige Skalierung, was uns Kubernetes vollautomatisiert zur Verfügung stellt. Dies stellt jedoch zusätzliche Anforderungen an unsere Applikationsarchitektur und das detaillierte Design für das Zustandsmanagement und die Persistenz von Daten.Die Konfiguration der Kubernetes-Objekte für das Deployment kann auf den ersten Blick furchteinflößend kompliziert wirken. Sobald aber der Zweck und das Zusammenspiel der einzelnen Objekte klar geworden sind, vergeht die Furcht recht schnell. Ebenso empfehle ich den Einsatz von Helm als Paket-Manager von Beginn an, denn auch diese Komplexität erscheint schlimmer, als sie tatsächlich ist, und nach den ersten Deployments möchte man die Funktionalität von Helm nicht mehr missen.Fussnoten
- The NIST Definition of Cloud Computing,
- Kubernetes Event-driven Autoscaling, https://keda.sh
- Microsoft Learn, Health checks in ASP.NET Core,
- Die Demo-Applikation zum Artikel auf GitHub,










