
19. Jan 2023
Lesedauer 6 Min.
Die Gruppe der RDF-Stores
Graph-Datenbank Cayley
Bei Cayley Graph Database liegen Licht und Schatten nah beieinander. Eine performante Datenbank mit prominentem Hintergrund zeigt Schwächen an anderer Stelle.
Im letzten Jahr erschien an dieser Stelle ein Vergleich verschiedener Graph-Datenbanken. Damals lag der Fokus eher auf der Gruppe der Allzweck-Graph-Datenbanken. Die Cayley Graph Database, um die sich dieser Artikel dreht, gehört demgegenüber zur Gruppe der RDF-Stores (Bild 1).
Die Homepagedes Open-Source-Projekts CayLey(Bild 1)
Geyer
Die Abkürzung RDF steht hierbei für Resource Description Framework, die Informationen mittels sogenannter Tripel aus Subjekt, Prädikat und Objekt speichert. Aus diesen drei Informationen ergibt sich der kleinstmögliche gerichtete Graph als minimaler Informationsbaustein: Zwei Knoten, die durch eine bestimmte Beziehung miteinander verbunden sind. Durch die Kombination vieler solcher Bausteine lassen sich tatsächlich beliebig komplexe Informationsnetzwerke erschaffen.
Semantisches Web
Eng mit diesem Konzept verflochten ist der Begriff »Semantisches Web«. Auf die diesbezüglichen Standards einzugehen, die sich vor allem mit Überlegungen zum syntaktischen Aufbau der zu speichernden Informationen beschäftigen, würde den Rahmen dieses eher praxisorientierten Artikels jedoch deutlich sprengen, weshalb an dieser Stelle zum Einstieg lediglich auf die W3C-Aufühungen unter https://www.w3.org/TR/rdf11-concepts/ verwiesen sei.Die Open-Source-Datenbank Cayley Graph Database, im weiteren Verlauf nur noch als Cayley bezeichnet, gibt auf der Webseite zwei Inspirationsquellen an: Google Knowledge Graph von Google und dessen Vorgänger Freebase, ein von Google mitsamt der Firma Metaweb 2010 aquiriertes Produkt. Der initiale Commit des Projektes auf Github ist datiert auf den 21. Juni 2014. Der Initiator Barak Michener war laut seines LinkedIn-Profiles bis Oktober 2014 bei Google beschäftigt, wohin er aufgrund der Übernahme von Metaweb gelangte. Bei Metaweb begann er 2008 eine Anstellung als Graph Database Engineer.An anderer Stelle wird noch erwähnt, daß das Open-Source-Projekt unter anderem auch mit aktiver Hilfe von Google an den Start gebracht wurde.Der mit Abstand schnellste und bequemste Weg zu einer funktionierenden Cayley-Installation ist Docker. Über die Eingabe vondocker run -p 64210:64210 cayleygraph/cayley
auf der Kommandozeile verfügt man in kürzester Zeit über eine laufende Instanz, die unter http://localhost:64210 auch eine recht einfache, aber funktionale Web-UI bereitstellt. Für die ersten Gehversuche mit einem RDF-Store lassen sich dort auch interaktiv Daten erfassen oder importieren. Anleitungen dafür finden sich in der durchaus brauchbaren Dokumentation auf der Projektwebseite, auch wenn man dort gelegentlich auf den einen oder anderen toten Link stößt.Als Alternativen zum Docker-Image werden auch ein Snap-Paket oder eine Installation mittels Homebrew offeriert. Last not least gibt es selbstredend auch eine Anleitung zum Eigenbau aus den Quellen. Warum gerade diese letztere Option auch für den Nur-Anwender durchaus interessant ist, darauf werden wir später noch zurückkommen.
Gremlin vs Gizmo
g.addV("foo")
g.addV("bar")
g.addE("edge").from("foo").to("bar")
Da Cayley selbst über keinerlei Absicherung oder Rechteverwaltung verfügt, wäre eine Installation auf einer öffentlich sichtbaren Maschine, zum Beispiel einem Webserver, eine wirklich außerdordentlich schlechte, ja geradezu fatale Idee. Auch ein Ausweichen auf einen anderen als den voreingestellten Port 64210 kann man getrost unter Augenwischerei verbuchen. So etwas ist kein wirkliches Hindernis für einen halbwegs gewieften Angreifer.
Bulk-Import von Daten
Für den Bulk-Import von Daten bietet sich bei Vorhandensein entsprechender Optionen auch immer deren Nutzung an. Cayley unterstützt hier neben N-Quads-Dateien auch Linked Data Files, letztere allerdings nur indirekt über einen vorher anzuwendenden Konverter. Für die normale Datenpflege gibt es spezielle Write- und Delete-APIs, die mitsamt allen anderen von Cayley bereitgestellten APIs unter HTTP Methods auf der Webseite dokumentiert sind. Ebenso werden dort auch einige Bibliotheken gelistet, deren Aktualität jedoch mit Vorsicht zu genießen ist.Speziell betrifft das die dort verlinkte NET-Library. Die noch auf dem Stand des alten NET-Frameworks stehende Bibliothek läßt sich zwar mit wenig Aufwand auf NET-Standard 2.0 anheben. Leider ist das aber noch nicht alles, denn die dort implementierte Abfragesprache ist noch Gremlin. Mittlerweile hat Cayley allerdings zu Gizmo gewechselt, und das unterscheidet sich eben in einigen Details von Gremlin. Last not least muss auch der API-Endpunkt entsprechend modifiziert werden. Die unter https://github.com/Jens-G/Cayley.Net verfügbare Version hat diese minimalen Änderungen implementiert. Die optional zu verwendenden Hilfsklassen zur Query-Generierung in dieser Bibliothek repräsentieren allerdings mit Sicherheit noch nicht den kompletten Gizmo-Sprachumfang und sind darüber hinaus auch noch nicht zu einhundert Prozent getestet. Wissenswert ist an dieser Stelle noch, dass Cayley neben Gizmo auch einen GraphQL-Dialekt und das proprietäre Freebase MQL unterstützt.Das für unsere Tests schon fast traditionell verwendete Datensatz-Subset aus den bekannten DataCharmer-Beispieldaten in das N-Quads- oder Linked Data Format umzuwandeln, wäre möglich (Bild 2).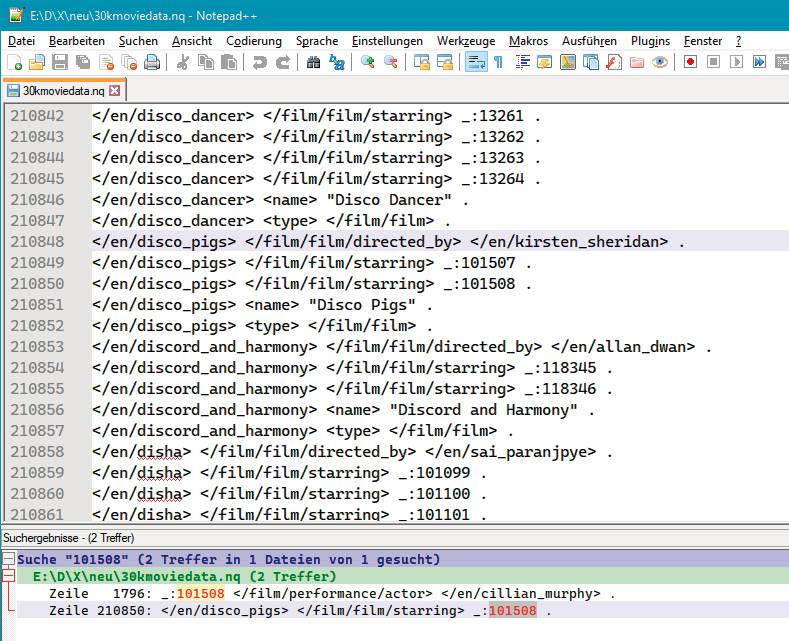
Auschnittaus der NQuads-Datei ‚30kmoviedata.nq‘(Bild 2)
Geyer
Da aber auch die Performance der Datenpflege-APIs bei unseren Betrachtungen eine Rolle spielt, kommt wieder eine angepasste Version unseres C#-Codes zum Einsatz, welcher die DataCharmer-Daten einfach Datensatz für Datensatz einliest und on the fly über die normale Write-API in das System einspeist. Diesen ersten Test bestand Cayley recht ordentlich: das simple Standard-Docker-Image ohne weitere Anpassungen oder spezielles Tuning importierte die 631636 Datensätze, die insgesamt circa 2,5 Millionen RDF-Tripel ergeben, klaglos in weniger als 4 Minuten. Zum Vergleich: die auffallend schlechte Performance der Azure Cosmos-DB eines bekannten Herstellers sorgte beim Import derselben Daten für eine Wartezeit von mehreren Stunden.
Abfrage-Performance
Hat man die Daten einmal importiert, kann man allerlei Abfragen darauf anwenden. Wie in nahezu allen Systemen sind einfache Anfragen innerhalb von Millisekunden abgearbeitet. Mit wachsender Komplexität, also primär mit der Anzahl der berührten Knoten und Kanten, steigt aber auch die Antwortzeit an. Während die Abfrage aller am 30. März 1992 begonnenen Arbeitsverträgeg.V("1992-03-30").in("from").all()
noch im Millisekundenbereich mit 64 Datensätzen beantwortet wird, werden die vier Nachnamen der am selben Tag nur in der Abteilung d001 Marketing eingestellten Personen erst nach über acht Sekunden geliefert:
x = g.V("1992-03-30").in("from")
y = g.V("dept/d001").in("department")
z = x.intersect(y)
z.out("employee").out("last_name").all()
Die Anfrage wurde aus Gründen der Übersichtlichkeit in mehrere Teilausdrücke zerlegt, das Ergebnis wird aber durch eine Zusammenfassung selbiger in eine einzelne Abfragezeile nicht beeinflusst (Bild 3). Was die Performance allerdings ändert, wäre das Weglassen des letzten Teilausdruckes. Das reine Ermitteln der Employment-Knoten-IDs ist nämlich wieder im Sekundenbruchteil erledigt. Hat man diese vier Knoten, ist es ähnlich schnell, die dazugehörigen Nachnamen mit weiteren Abfragen zu ermitteln. Warum dann also dieselbe Abfrage aus einem Guß derart bummelig daherkommt, bleibt ein Mysterium.
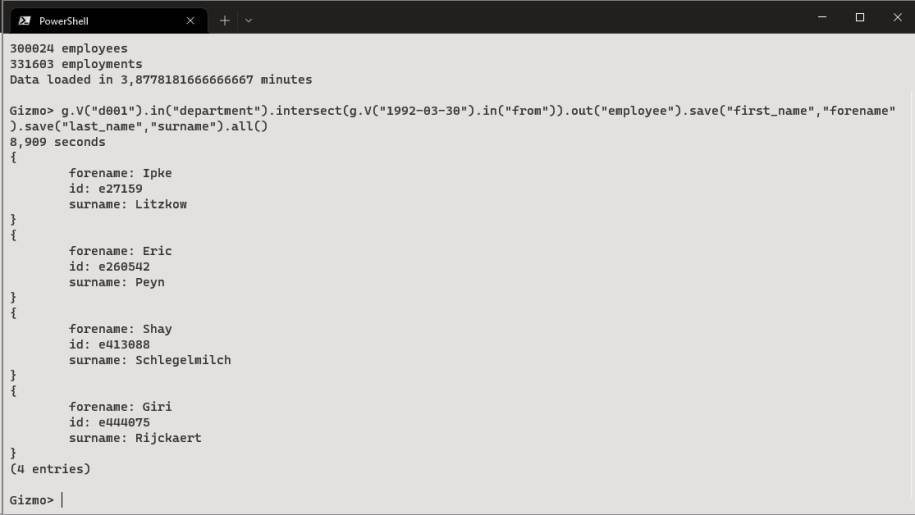
Komplexere Abfragendauern schon mal ein paar Sekunden(Bild 3)
Geyer
Eine Anfrage wie die nach der Anzahl aller Knoten im System hat schon unerwartete Ergebnisse geliefert. Im Falle von Cayley ist auch das immerhin nach 6 Sekunden erledigt. Als Fazit gilt also auch hier wieder die bei allen Datenbanken anzuwendende Regel, dass man seine Abfragen vor Produktionsfreigabe auch mal mit wirklich vielen Daten testen sollte.
Fazit
Weil Cayley ein Open-Source-Projekt ist, ist die Aktivität der Community und die Frequenz der Releases ein durchaus interessantes Kriterium. Tatsächlich ist die Community um Cayley seit dem letzten Release 0.7.7 vom Oktober 2019 eher semi-aktiv. Es wäre nun natürlich möglich, dass der angestrebte Entwicklungszustand erreicht ist und Cayley damit in eine Art stabilen Endzustand übergegangen ist.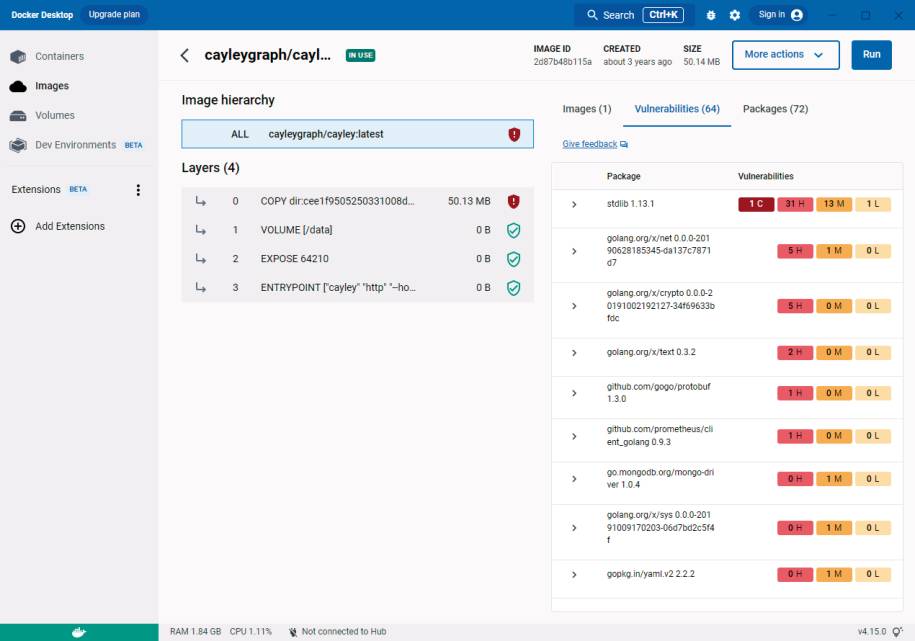
Installation:Der schnellste Weg zu einer funktionierenden Cayley-Installation ist Docker(Bild 4)
Geyer
In der Praxis erweist sich solche Theorie aber bekanntlich häufig als reines Wunschdenken. Meist sind es äußere Einflüsse, die mindestens irgend eine Art von Wartung erfordern. Ein guter Indikator dafür ist die Tatsache, dass das ebenfalls drei Jahre alte Docker-Image aktuell mit immerhin 64 automatisch erkannten CVEs in den diversen verwendeten Bibliotheken glänzt (Bild 4). Ein direkter produktiver Betrieb dieses Images ist also definitiv nicht ratsam. Im Zweifelsfall sollte man daher in Betracht ziehen, die nötigen Go-Language-Tools und Bibliotheken gemäß Anleitung in einer aktuellen Version zu installieren und alles aus den Quellen selber zu bauen.Abgesehen von solcherlei kleineren Schwächen und falls man mit der schaumgebremsten Community und den in speziellen Dialekten vorliegenden Abfragesprachen leben kann, ist Cayley ein erfrischend unkomplizierter und durchaus performanter Vertreter aus der Gruppe der Open-Source-RDF-Stores.
Links zum Thema
<b>◼ <a href="https://www.w3.org/TR/rdf11-concepts/" rel="noopener" target="_blank">W3C: "RDF 1.1 Concepts and Abstract Syntax"; W3C Recommendation 25 February 2014</a> <br/></b>









