14. Nov 2022
Lesedauer 13 Min.
CI/CD mit YAML-Pipelines
versionierte und wartbare CI/CD-Automatisierung in Azure DevOps
Mit den YAML-Pipelines bietet Azure DevOps eine umfangreiche Funktionalität für die Build- und Release-Automatisierung. Das Wichtigste im Überblick.
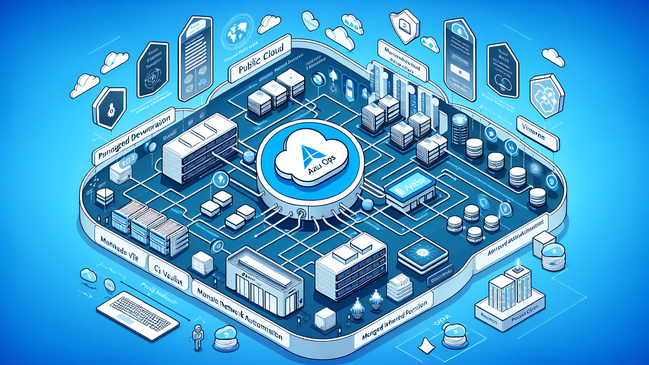
Die erste Preview-Version der heutigen YAML-Pipelines erschien im November 2017; sie stellte die dritte Version der Build- und Release-Automatisierung in Azure DevOps dar. YAML-Pipelines sind seit geraumer Zeit der Standard für die Build-Automatisierung, bei der Release-Automatisierung hat der Benutzer aktuell noch zwei unterstützte Systeme: Classic Releases und die YAML-Pipelines. Viele Wünsche der Benutzer wurden in der aktuellen Version umgesetzt, und der Name „YAML-Pipelines“ ist auch tatsächlich Programm. Mit YAML ist nicht nur eine neue und stark verbreitete Syntax hinzugekommen, die YAML-Definition wird nun auch endlich im Git-Sourcecode-Repository verwaltet. Im Gegensatz zu den Vorgängerversionen der Build- und Release-Definitionen, die nicht mit dem Sourcecode gekoppelt waren, können wir nun eine klare Configuration-as-Code-Strategie fahren. Der Sourcecode sowie die dazugehörige CI/CD-Automatisierung können nun miteinander im gleichen Repository in einem Branch weiterentwickelt und über einen Pull-Request validiert und integriert werden. Schluss mit den Zeiten, als man viele duplizierte Stände gespeichert hatte, um verschiedene Versionen der Software zu erstellen und auszuliefern.Mit „Pipelines“ im Namen wird auch klar, dass man nicht mehr zwischen Build und Release unterscheidet. Wir gewinnen also deutlich mehr Flexibilität, und die starren Strukturen sind Geschichte. Es ist nun dem Anwender überlassen, alles in einer Pipeline mit verschiedenen Stages und Jobs zu implementieren oder mehrere Pipelines aneinanderzuketten. Jede Automatisierung ist eine Pipeline, die Artefakte publizieren kann und wiederum als Trigger oder Artefakt-Lieferant für andere Pipelines verwendet werden kann.Diese Flexibilität bedingt aber auch, ein klares Konzept zur Struktur und Wiederverwendbarkeit der Pipelines zu erstellen. Ein möglicher Ansatz, welcher sich über die letzten Jahre bewährt hat, ist in Bild 1 dargestellt. Wir unterscheiden zwischen Pipelines für die Basisinfrastruktur wie Netzwerk, SQL Cluster et cetera und den eigentlichen Applikations-Pipelines. Für jede Applikation respektive jeden Service wird zwischen Pipelines für Continuous Integration (CI) und Continuous Deployment beziehungsweise Continuous Delivery (CD) unterschieden. Wie bereits angesprochen, könnte man CI und CD auch in einer einzelnen Pipeline implementieren, zwei separate Pipelines mit einem Trigger von CI zu CD sind aber oft praktikabler. So kann auch nur die CD-Pipeline erneut getriggert werden und die bereits erstellten CI-Artefakte werden einfach nochmals verwendet.
Erprobte Aufteilungin verschiedene Pipelines(Bild 1)
Autor
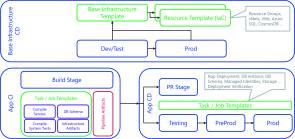
In Bild 2 sehen wir, wie wir Pipelines miteinander verketten (englisch: Pipeline Chaining) und somit bei erfolgreicher Durchführung der ersten Pipeline eine weitere Pipeline starten, die dann Zugriff auf die Informationen und Artefakte der ersten Pipeline erhält.
Verkettungvon zwei Pipelines mit Informationsaustausch(Bild 2)
Autor
Configuration as Code
Bei YAML-Pipelines werden die Definitionen als YAML-Dateien direkt im Sourcecode-Repository gespeichert. Dies ist in Azure DevOps aber lediglich für Git-Repositories und nicht für TFVC (Team Foundation Version Control) verfügbar. Wo und wie die Dateien im Repository gespeichert werden, lässt Microsoft offen. Grundsätzlich verlinkt die Pipeline-Definition in Azure DevOps eine YAML-Datei, die sich irgendwo in einem beliebigen Branch im Repository befinden kann. Eine Pipeline mit dem Namen azure-pipelines.yml auf oberster Ebene wird als Default-Pipeline automatisch erkannt. Alle anderen müssen explizit eingerichtet werden. Da meist mehrere Pipelines in einem Repository vorhanden sind, bringt die Default-Pipeline nicht allzu viel, und man muss sich ohnehin Gedanken zur Verzeichnisstruktur und zu Namenskonventionen machen.Generell ist es sinnvoll, die Pipeline-Definitionen in einem Unterverzeichnis zu speichern. Bei einem Mono-Repository kann dies ein Unterverzeichnis pro Service sein, oder man bildet die Service-Struktur innerhalb eines generellen Pipelines-Verzeichnisses ab. Die Verzeichnisstruktur soll dabei helfen, Pipeline-Änderungen zu erkennen und einfach in die Branch Policies zu integrieren. Die Branch Policies ermöglichen es, spezifische Personen oder Gruppen bei Pipeline-Änderungen in den Pull-Request als erforderliche Reviewer hinzuzufügen und natürlich auch die Pipeline selbst bei einer Änderung als Check im Pull-Request laufen zu lassen. Egal ob wir also Code oder Pipelines überarbeiten, die bewährte Funktionalität von Pull-Requests trägt zur Qualitätssicherung und dem Vier-Augen-Prinzip beider bei.Wer jetzt schon glücklich über die Configuration-as-Code-Funktionalität ist, der wird sich noch mehr freuen, wenn er feststellt, dass wir das Configuration Management für CI/CD noch viel weiter treiben können. Mit YAML-Pipelines sind viele neue Funktionen hinzugekommen, darunter auch die einfache Integration der Pipeline-Ausführung in Containern. Jeder Job – die eigentliche Ausführungseinheit auf einem Agent – kann in einem Container ausgeführt werden. Der Anwender muss hierzu nichts an der Pipeline respektive den Tasks verändern. Es muss lediglich dem Job mitgeteilt werden, welches Container-Image instanziert werden soll, und der Job darin ausgeführt werden. Der Agent stellt das Arbeitsverzeichnis als Volume im Container bereit und führt die Befehle mit einem docker exec direkt im Container aus. Dies geschieht natürlich in einem isolierten Docker-Netzwerk und kann um zusätzliche Hilfscontainer, sogenannte Service Container, erweitert werden.Die Möglichkeiten von Container-Jobs sprengen den Rahmen dieses Artikels, darum möchte ich hier speziell auf das Configuration Management eingehen. Wenn man nun die Bauanleitung dieser Container-Images, das Dockerfile, ebenfalls in der Sourcecode-Verwaltung hinterlegt und die Images sauber versioniert über eine dedizierte Pipeline baut, können diese Images jederzeit wieder erstellt werden. Für die Verwendung in Container-Jobs muss das Image dann entsprechend über das Tag in der eigentlichen Pipeline referenziert werden. Somit ist das gesamte CI/CD-System versioniert. So einfach und gut integriert konnte man Konfigurationsmanagement für CI/CD noch nie in Azure DevOps implementieren.
Templates
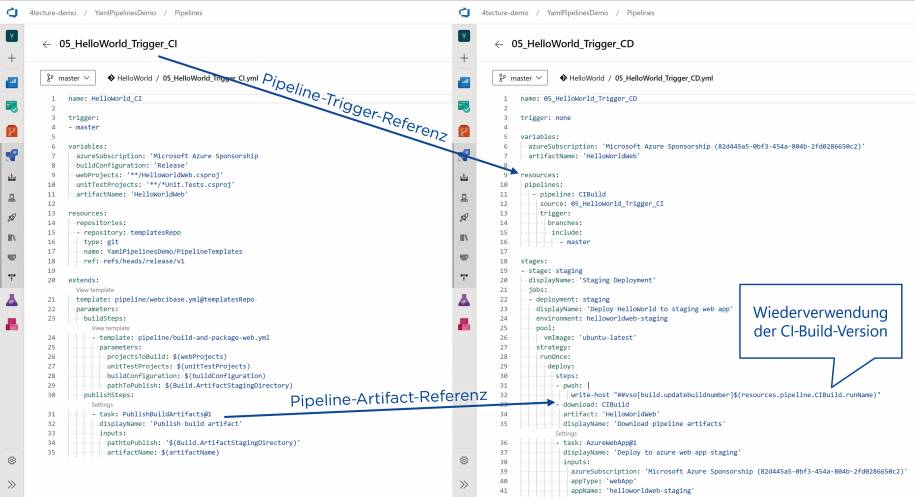
Die Versionierung in Git löst noch nicht das Problem, dass wir auch wartbare Pipelines erstellen und möglichst keine Code-Duplikationen haben wollen. Oft wiederholen sich Tasks oder ganze Abfolgen von Tasks. Zum Beispiel werden der Build und der Release in einem Microservice-Umfeld für jeden Service fast identisch aussehen, lediglich Parameter wie Verzeichnisse und Projektnamen werden sich unterscheiden. Zudem kann es auch sein, dass firmenweit gewisse Standards durchgesetzt werden sollen und somit dieselben Tasks mit den gleichen Settings in verschiedenen Teams verwendet werden müssen.Hierzu kommen die Templates ins Spiel. Templates lagern YAML-Bereiche in separate Dateien aus und können von den Pipelines respektive anderen Templates referenziert werden. Templates können für Steps, Jobs, Stages und Variablen erstellt werden. Nur Ressourcen und Trigger müssen also zwingend in der Pipeline hinterlegt werden, alles andere kann somit ausgelagert und wiederverwendet werden. Die Templates werden zur Laufzeit in eine einzige Runtime-Pipeline zusammengeführt, somit sind zum Ausführungszeitpunkt die Templates nicht mehr zu erkennen. Wichtig zu erwähnen ist, dass Templates nicht unendlich tief verschachtelt werden können. Microsoft gibt hierzu klare Grenzen vor: Nicht mehr als 100 YAML-Dateien lassen sich direkt oder indirekt referenzieren, die Verschachtelungstiefe ist auf 20 Ebenen beschränkt und der YAML-Parser darf nicht mehr als 10 MB Speicher verwenden (was insgesamt circa 600 KB bis 2 MB an YAML-Dateien auf der Festplatte entspricht).Bei der Erstellung von Templates gibt es ebenfalls einiges zu beachten. Grundsätzlich kann man in einem Template auf sämtliche Pipeline-Variablen zugreifen. Jedoch kennt man als Template-Ersteller nicht zwingend alle Aufrufer respektive erkennt man beim Referenzieren von Templates nicht, welche Variablen im Template verwendet werden. Aus diesem Grund sollten in einem Template keine Variablen verwendet werden (bis auf System-Variablen und Task-Variablen innerhalb des Templates). Mittels Parametern können in Templates die Schnittstellen klar definiert werden. Diese Parameter werden beim Referenzieren von einem Template validiert und der Aufrufer bekommt im Editor auch IntelliSense-Informationen beim Schreiben der YAML-Dateien. Parameter sind typisiert und können auch Default-Werte enthalten (siehe Bild 3). Somit gibt es einen klaren Kontrakt zwischen Aufrufer und Template. Laufzeitfehler aufgrund fehlender Variablen gehören damit der Vergangenheit an. Parameter können auch direkt in der Pipeline als sogenannte Runtime-Parameter eingesetzt werden. Dies ist für manuell getriggerte Pipelines ebenfalls sehr interessant, denn der Benutzer bekommt hierbei ein aus der Parameter-Definition gerendertes Formular mit integrierter Validierung. So kann der Aufrufer bequem die Werte für den Pipeline-Run auswählen beziehungsweise eingeben.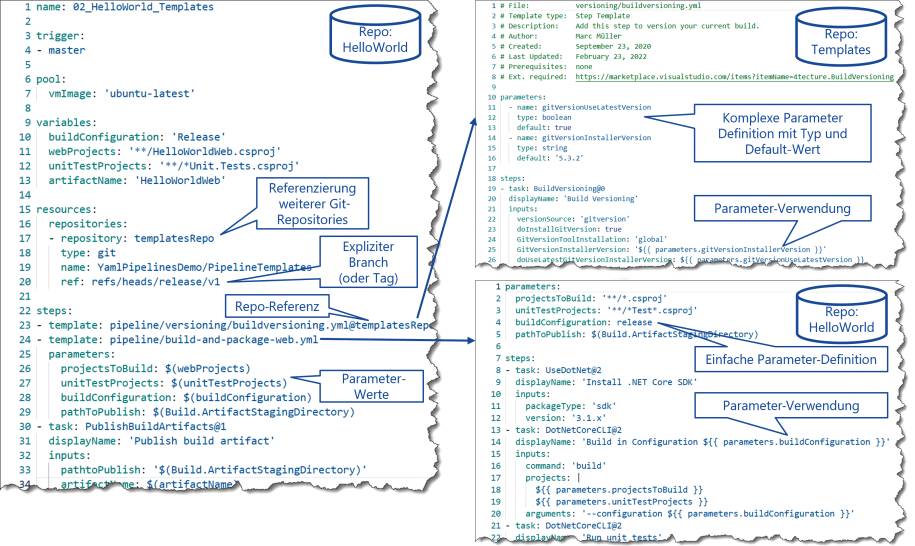
Referenzieren und Anwendenvon Templates über die Git-Repository-Grenze hinaus(Bild 3)
Autor
Die Template-Funktionalität geht aber noch wesentlich weiter. Gerade in größeren Unternehmen gibt es oft Templates, die zentral verwaltet werden und verschiedenen Teams zur Verfügung gestellt werden sollen. Mit YAML-Pipelines ist es möglich, Templates auch von anderen Git-Repositories zu referenzieren. Damit diese zentralen Templates sauber versioniert und weiterentwickelt werden können, kann – und sollte unbedingt – eine Git-Referenz der Respository-Ressource mitgegeben werden. Somit wird ein bestimmtes Tag oder ein bestimmter Branch für die Template-Referenz verwendet. So ist es auch möglich, dass Pipeline A die Version v1 des Templates und Pipeline B die Version v2 desselben Templates verwendet. Hier erkennt man wiederum, dass dieses Feature im Vergleich zu den früheren Task-Gruppen besser umgesetzt wurde. Bild 3 zeigt, wie Templates über mehrere Git-Repositories hinweg referenziert und mittels Parameter-Werten konfiguriert werden.Wem dies immer noch nicht genug ist, der kann noch einen Schritt weitergehen. Möchte man lieber die gesamte Pipeline vorgeben und dem Team nur ermöglichen, eigene Tasks an bestimmten Stellen des Templates einzufügen, so kann man mit der Template-Vererbung arbeiten. Im Gegensatz zur Template-Referenz erbt die Pipeline von einem Template und kann, falls gewünscht, über die Template-Parameter mit zusätzlichen Tasks erweitert werden. Man könnte jetzt sagen, dass es Geschmacksache ist, ob man lieber referenziert oder vererbt. In Sachen Durchsetzungsstärke und sicherheitsrelevante Einschränkungen hat aber die Template-Vererbung die Nase vorn. Auf Environments oder Service Connections können Checks hinzugefügt werden, die sicherstellen, dass zum Beispiel nur auf die Zielressource ausgeliefert werden darf, wenn die aktuelle Pipeline von einem bestimmten Template erbt, und ansonsten nicht. Zudem können im zu vererbenden Template über YAML-Expressions die Wertebereiche der Parameter eingeschränkt werden und zum Beispiel nur bestimmte Typen als benutzerdefinierte Tasks zugelassen werden. Bild 4 zeigt die Verwendung eines vererbten Templates mit der Möglichkeit, eigene projektspezifische Tasks einzufügen. Im Beispiel sind Skript-Tasks vom Typ CMD nicht erlaubt.

Pipeline-Vererbungmittels Template Extends(Bild 4)
Autor
Für das systemseitige Einfügen von zum Beispiel sicherheitsrelevanten Tasks in Pipelines gibt es noch eine weitere Möglichkeit. Wer gewisse Tasks zwingend vorgeben möchte, aber ohne Template-Vererbung arbeiten will oder muss, kann Pipeline Decorators verwenden. Dabei handelt es sich um eine Azure-DevOps-Extension vom Typ ms.azure-pipelines-agent-job.post-job-tasks. Hier kann ein Step-Template hinterlegt werden, welches bei jeder Pipeline das Template als Pre- oder Post-Steps einhängt. Über Expressions kann wiederum dynamisch evaluiert werden, wann welche Steps oder Tasks eingefügt werden sollen. So kann etwa ein Security Scan zwingend für alle CI-Pipelines eingefügt und ausgeführt werden.
Die Welt außerhalb von YAML
Ja, es gibt sie noch, die Welt außerhalb von YAML. Nicht alles soll und kann in YAML-Dateien hinterlegt sein. Was für viele Belange die beste Möglichkeit darstellt, ist für sicherheitsrelevante Informationen absolut keine gute Idee. Alle Dateien in Git-Repositories werden von der Volltextsuche indexiert, somit müsste man sich nicht einmal große Mühe geben, um an geheime Informationen zu kommen. Entsprechend verwaltet Azure DevOps bei den YAML-Pipelines einige Komponenten außerhalb der Textdateien.Primär sind dies Secret-Variablen, Variablen-Gruppen, Service Connections und Environments. Alle Zugangsdaten, Connection-Strings und Credentials verwalten wir somit mit den entsprechenden Entitäten außerhalb der YAML-Pipeline. Werden aus einem Task Zugriffsinformationen für einen externen Dienst benötigt, so empfiehlt sich die Verwendung der Service Credentials. Azure DevOps bietet hier viele vordefinierte Typen an, um einfach die Zugriffsinformationen für die meistgenutzten externen Dienste zu hinterlegen. Beim Zugriff auf Azure können darüber hinaus auch die Tokens für die Service-Principals automatisiert über die Webapplikation erneuert werden. Für alle anderen Geheimnisse bietet sich die Verwendung von Secure-Variablen an, entweder auf der Pipeline-Definition selbst (über Pipeline-Settings) oder in einer Variablen-Gruppe. Letztere Variante ist klar zu bevorzugen, da somit die Variablen in verschiedenen Pipelines wiederverwendet werden können und auch eine Integration in Azure Key Vault einfach möglich ist. Die Kombination von Azure Key Vault und Variablengruppen stellt klar die beste Lösung dar, auch wenn sie mit minimalen Zusatzkosten verbunden ist (circa drei Euro pro eine Million Secret-Zugriffe).Alle diese Entitäten können entsprechend in der YAML-Pipeline referenziert werden. Azure DevOps hat hierbei ein mehrstufiges Rollenkonzept. So kann zum Beispiel die Benutzung einer Variablengruppe (Referenzieren in einer YAML-Pipeline mit späterer Ausführung) von der eigentlichen Verwaltung der Variablen und Werte getrennt werden. Dadurch kann nur ein kleiner Teil der Administratoren sicherheitsrelevante Informationen verwalten und die Build-Administratoren können diese lediglich anwenden. Generell sollten diese Ressourcen auch nicht standardmäßig für alle Pipelines freigegeben werden. Ist diese Option bei der Erstellung deaktiviert, muss bei der erstmaligen Ausführung der Pipeline ein Benutzer mit den notwendigen Rechten erst eine Freigabe erteilen. In Bild 5 ist eine schematische Übersicht dargestellt, wo Secrets gespeichert und verwendet werden.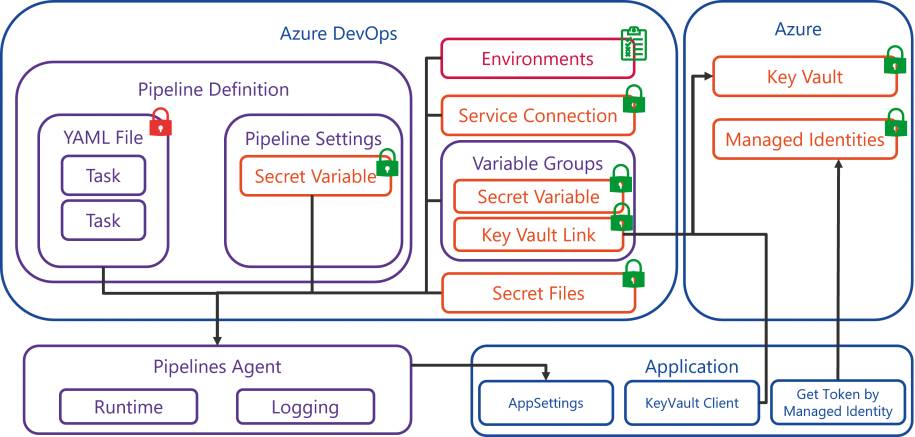
Verwendung von Secretsin YAML-Pipelines(Bild 5)
Autor
Environments stellen eine logische Zielumgebung dar. Oft ist nicht klar definiert, was das Environment abbildet. Es kann als Auslieferungs-Ziel, etwa als Produktivumgebung für mehrere Applikationen, verwendet werden, kann aber auch das Deployment einer einzelnen Applikation darstellen. Das Environment gibt eine Übersicht, welche Deployments auf dieses Ziel bislang durchgeführt wurden. Als Zusatzfunktionalität bieten die Environments „Approvals and Checks“ an. Alles, was man früher in den Classic Releases als Vor- und Nachbedingungen konfigurieren konnte, ist nun in die Environments gewandert. Nebst manuellen Freigaben können Monitoring-Daten über REST-Schnittstellen als automatische Freigabekriterien verwendet werden. Zeitslots für Deployments können definiert werden und das bereits angesprochene Basis-Template (Template-Vererbung) für das Deployment auf dieses Environment kann hier festgelegt werden. Für containerbasierte Anwendungen können zudem noch die Artefakte geprüft werden, bevor diese ausgeliefert werden dürfen.In den Anfängen von YAML-Pipelines gab es einen großen Nachteil: Man konnte einen Stage nicht exklusiv blockieren. Dies war lange Zeit nur den Classic Releases vorbehalten. Ein Stage kann aus mehreren Jobs bestehen. Somit könnte in Job 1 die Applikation ausgeliefert und in Job 2 die Systemtests ausgeführt werden. Nun kann es passieren, dass ohne Lock zwei Releases getriggert werden und dass, noch bevor die Systemtests laufen, das Environment bereits durch eine andere Pipeline auf eine andere Version aktualisiert wurde. Mit der Option Exclusive Lock kann nun genau dies implementiert werden. So warten alle anderen Pipeline-Instanzen, bis der gesamte Stage, also alle zusammenhängenden Jobs, abgearbeitet wurde.Zu guter Letzt gibt es noch zwei Spezialfunktionen. Stellt das Environment einen oder mehrere Zielrechner dar, können auf der Zielmaschine Agents installiert und mit diesem Environment verknüpft werden. Dann wird der Deployment-Job der Pipeline automatisch auf allen Agents ausgeführt, die diesem Environment zugeordnet sind. Diese Funktionalität war als Deployment Groups für Classic Releases bekannt und ist nun über die Environments auch für YAML-Pipelines verfügbar. Im gleichen Sinn kann für Kubernetes-Deployments einem Environment eine Kubernetes-Verbindung hinterlegt werden. Für alle anderen Deployment-Varianten bleibt das Environment ein rein logisches Gebilde ohne Verbindung zu einer physikalischen oder virtuellen Zielumgebung.
<AzureDevOpsHost>/_apis/public/distributedtask/webhooks/ <webhookname>. Dieser URL kann nun als Zieladresse für einen WebHook verwendet werden. Für unser Beispiel verwenden wir den Pull-Request Updated Event, um so nach der Erledigung die Ressourcen aufzuräumen. Der eigentliche Trigger in der YAML-Pipeline erfolgt über eine WebHook-Ressource. Wichtig ist noch zu erwähnen, dass alle Ressourcen-basierten Trigger (WebHook, Pipeline et cetera) erst dann aktiv werden, wenn die YAML-Datei im Default-Branch verfügbar ist. Solange man sich also nur im Feature-Branch bewegt, ohne die YAML-Definition einmal in den Main-Branch integriert zu haben, werden systemseitig keine Trigger aktiviert und man wartet vergebens, dass die Pipeline startet.
Incoming WebHook Trigger
Azure Pipelines fokussiert sich primär auf die Automatisierung von CI/CD-relevanten Aufgaben. Grundsätzlich wäre es aber schön, wenn man diese Plattform auch für allgemeinere Aufgaben nutzen könnte, zumal eine Pipeline alles Erdenkliche ausführen kann. Das Problem stellt grundsätzlich also eher der Trigger dar. Wie kann man zum Beispiel eine Pipeline starten, wenn ein Work Item aktualisiert wird? Wie kann man auf einen Pull-Request-Event reagieren?Azure DevOps implementiert schon seit längerer Zeit eine Event-Notifikation mittels WebHooks; sie ist über das Settings-Menü unter Service Hooks verfügbar. Es steht eine Reihe von vorgegebenen Integrationen zur Verfügung, darunter auch die Option WebHooks, welche mittels eines internen Events einen externen REST-Endpunkt aufruft und den gesamten Event-Kontext als JSON-Dokument mitsendet. Bislang musste man somit eine eigene externe Webapplikation betreiben, die den WebHook-Event entgegennimmt und dann über das Azure-DevOps-API eine Pipeline startet oder direkt über das API Aktionen ausführt. Dies ist sehr umständlich und mühsam zu warten. Umso mehr erstaunt es, dass die neue Funktionalität „Incoming WebHook“ vielen nicht bekannt ist und sich auch eher unscheinbar hinter vielen Settings-Dialogen verbirgt. Über die Service Connections in den Projekt-Settings kann ein Incoming WebHook konfiguriert werden. Dieser tut genau das, was früher mühsam selber gehostet werden musste. Der Incoming WebHook erstellt einen Endpunkt in Azure DevOps, welcher als WebHook-Ziel der Service-Hooks-Events angegeben werden kann. Dieser Service-Connection-Eintrag kann wiederum als Trigger für eine Pipeline verwendet werden. Der Payload des Events, also die Event-Details als JSON-Dokument, steht über die Pipeline-Parameter zur Verfügung. Et voilà – wir können somit mit Azure Pipelines einfach alles automatisieren, was über einen WebHook-Event getriggert werden kann. Jede Pipeline hat ein Access Token als Variable zur Verfügung, um direkt mit dem Azure-DevOps-API zu interagieren. Wer es ein wenig komfortabler mag, kann auch das Azure-DevOps-CLI in einem Task verwenden und so mittels PowerShell oder Bash mit Azure DevOps interagieren.Bild 6 zeigt, wie dieser Incoming WebHook Trigger für das Aufräumen von Pull-Request-Deployments verwendet werden kann. Zunächst wird ein Incoming WebHook Trigger in den Service Connections erstellt. Der WebHook-Name wird entsprechend für das Erstellen des Endpunktes verwendet und ist Bestandteil des generierten URL nach dem Schema: https://<AzureDevOpsHost>/_apis/public/distributedtask/webhooks/ <webhookname>. Dieser URL kann nun als Zieladresse für einen WebHook verwendet werden. Für unser Beispiel verwenden wir den Pull-Request Updated Event, um so nach der Erledigung die Ressourcen aufzuräumen. Der eigentliche Trigger in der YAML-Pipeline erfolgt über eine WebHook-Ressource. Wichtig ist noch zu erwähnen, dass alle Ressourcen-basierten Trigger (WebHook, Pipeline et cetera) erst dann aktiv werden, wenn die YAML-Datei im Default-Branch verfügbar ist. Solange man sich also nur im Feature-Branch bewegt, ohne die YAML-Definition einmal in den Main-Branch integriert zu haben, werden systemseitig keine Trigger aktiviert und man wartet vergebens, dass die Pipeline startet.
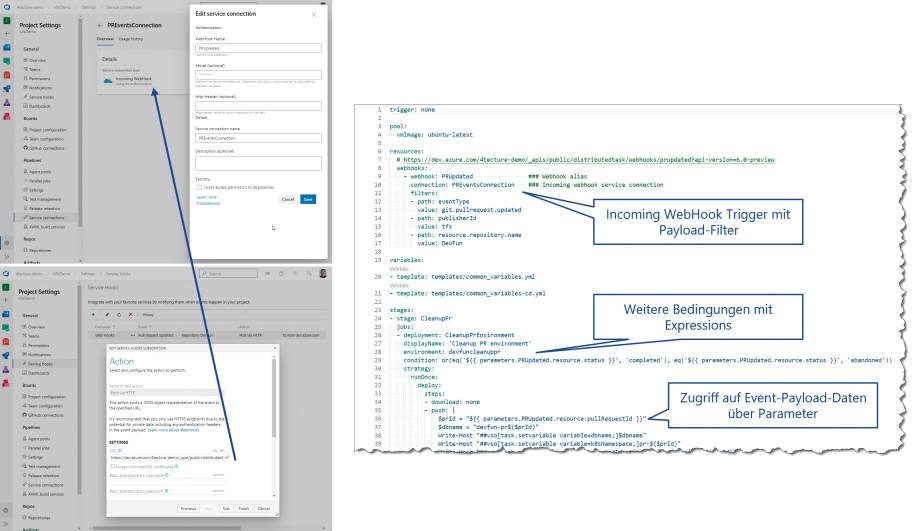
Definition einer PipelinemitIncoming WebHook Trigger(Bild 6)
Autor