
12. Okt 2020
Lesedauer 11 Min.
Bildinhalte erfassen
OpenCV mit Python, Teil 2
Eine der Stärken von OpenCV ist die Geschwindigkeit der eingebauten Algorithmen.

Der erste Artikel über die OpenCV-Bibliothek [1] hat die einfachen Funktionen für die Bearbeitung von Bildern vorgestellt. Dazu gehören das Laden und Speichern, das Schärfen und das Transformieren von Bildinhalten. Diese Funktionalitäten sind die Grundvoraussetzungen für die weitere Bildverarbeitung, also das Ermitteln des Bildinhalts. So könnte man zum Beispiel feststellen, wie viele – und welche – Münzen auf einem Bild zu sehen sind. Oder man möchte die Schrauben und Muttern auf einem Fließband zählen. Es geht also darum, zu erkennen, was auf den Bildern abgebildet ist. Die erforderlichen Rechenalgorithmen sollen hier in diesem Artikel zumindest teilweise vorgestellt und in einfachen Szenarien angewendet werden.OpenCV (Open Computer Vision) soll natürlich auch mit bewegten Bildern schnell und zuverlässig funktionieren. So ist es sehr interessant für das autonome Fahren, ob am Straßenrand ein Auto parkt oder ein Mensch steht, der die Straße überqueren möchte. In diesem Fall spielt dann natürlich auch die Performance der Bibliothek eine sehr große Rolle, denn eine Bildanalyse ist ziemlich sinnlos, wenn das Ergebnis erst zehn Sekunden zu spät zur Verfügung steht.
Ecken entdecken
Im vorangegangenen Artikel [1] haben Sie schon einen Algorithmus kennengelernt, der Kanten in einem Bild entdecken kann. Im nächsten Beispiel wird es nun darum gehen, die Ecken der Objekte in einem Bild zu ermitteln.Das hierfür benutzte Verfahren ist der Harris-Algorithmus, der natürlich ebenfalls von der OpenCV-Bibliothek zur Verfügung gestellt wird. In den Downloads zum Artikel finden Sie im Unterverzeichnis Images zwei Bilddateien (Bild1.jpg und Bild2.jpg), die ein Abbild eines grauen und eines weißen Quaders enthalten. Wenn man die Sache zunächst einmal theoretisch betrachtet, dann hat ein Würfel acht Ecken, von denen in einem zweidimensionalen Bild nur sieben Ecken zu sehen sind. Listing 1 zeigt ein Python-Programm, das die sichtbaren Ecken der Quader-Objekte ermitteln soll.Listing 1: Ecken ermitteln
import cv2
import numpy as np
# Bild laden und Graubild erstellen
img = cv2.imread(".\images\Bild1.jpg")
#img = cv2.imread(".\images\Bild2.jpg")
grauImg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
grauImg = np.float32(grauImg)
# Harris Ecken-Algorithmus
corner = cv2.cornerHarris(grauImg, blockSize = 14,
ksize = 5, k = 0.05)
# Eck-Pixel mit 'dilate' verstärken
kernel = np.ones((5, 5), np.float32)
corner = cv2.dilate(corner, kernel, 1)
# Ecken im Bild 'img' als rote Punkte markieren
img[corner > 0.01 * corner.max()] = [0, 0, 255]
# Ergebnisbild ausgeben
cv2.imshow("Harris (scharfe Kanten)", img)
cv2.waitKey(0)
Das kleine Programm beginnt mit den erforderlichen import-Befehlen. Als Nächstes wird ein Farbbild geladen und mit cvtcolor in ein Schwarz-Weiß-Bild umgewandelt. Hier erhalten wir ein neues Image-Objekt grauImg. Das Farbbild wird später noch benötigt und bleibt in der Variablen img erhalten. An dieser Stelle kann man zwischen zwei Bildern wählen, um den Algorithmus zu testen. Bild1.jpg enthält einen grauen Quader vor einem hellen Hintergrund. Bild2.jpg zeigt einen weißen Quader mit einem dunklen Hintergrund.Nun konvertieren wir das Graubild in ein numpy-Array von Typ float32. Die Erzeugung und die verfügbaren Rechenmethoden dieser Arrays wurden bereits in einem früheren Artikel [2] ausführlich vorgestellt.Jetzt kann der Harris-Ecken-Algorithmus mit dem Funktionsaufruf cornerHarris angewendet werden. Die in Listing 1 angegebenen Parameter haben einen großen Einfluss auf das Ergebnis: Nach der Angabe des Image-Objekts wird der Parameter blockSize gesetzt. Dieser Wert bestimmt die Größe des Blocks mit seinen Nachbar-Pixeln, den es auszuwerten gilt. Je kleiner der Wert ist, desto feinere Strukturen im Bild führen zu einer Ecke. Wenn blockSize zu klein ist, erhält man also im Ergebnis auch einige „Ecken“, die gar keine sind. Dies wird gut erkennbar, wenn Sie mit Bild2.jpg den Parameter blockSize=6 setzen und die Analyse ausführen. Hier liefern einige Kratzer im Hintergrund eine „Ecke“, die gar keine ist. Auf der anderen Seite muss der Block der Nachbar-Pixel aber auch groß genug sein, um eine Ecke überhaupt zu erkennen.Die vom Algorithmus ermittelten „Ecken“-Pixel werden im Image-Objekt corner abgelegt. Der Parameter ksize gibt die Größe für den Sobel-Kernel an, der Kanten erkennen kann. Der letzte Parameter k ist der freie sogenannte Harris-Detektor-Parameter, der in die Formel eingeht, welche die Gradienten der Helligkeiten auswertet, um die Ecken zu ermitteln. Die Formel wird in der OpenCV-Dokumentation im Abschnitt der cornerHarris-Funktion vorgestellt [3].Als Nächstes sollen diese Pixel im Image corner mit der dilate-Funktion etwas verstärkt werden, damit man sie im finalen Ausgabebild besser erkennen kann. Die dilate-Funktion erhält das zu bearbeitende Image als ersten Parameter. Danach folgt eine Kernel-Matrix der Größe 5, die in den Diagonalelementen nur die Zahl „Eins“ enthält. Diese Matrix soll einmal (dritter Parameter) angewendet werden, um das Bild zu verstärken. Das Ergebnisbild wird wieder in der Variablen corner abgelegt.Nun soll das Ecken-Ergebnis corner mit dem Ursprungsbild img kombiniert werden. Dies lässt sich mit der folgenden Code-Zeile realisieren:
img[corner > 0.01 * corner.max()] = [0, 0, 255]
Einerseits werden hier die vereinfachten Rechenmöglichkeiten mit numpy-Arrays benutzt. Andererseits wird in den eckigen Klammern ein Grenzwert festgelegt (hier: 0.01 * corner.max()). Immer wenn der Pixelwert im corner-Image größer als dieser Grenzwert ist, soll im Ergebnisbild img ein roter Pixel gesetzt werden. Schleifen sind hier nicht notwendig, da der Python-Interpreter die Befehle automatisch über alle Elemente des Arrays img laufen lässt.Nun müssen wir das Ergebnis nur noch mit imshow ausgeben und die waitKey-Funktion aufrufen. Bei der Betrachtung des Ergebnisses in Bild 1 sieht man sofort, dass bei unserer Parameterwahl zwei Ecken nicht gefunden werden. Hier sind die Grauunterschiede wahrscheinlich zu gering, sodass die Ecken nicht erkannt werden. Abhilfe kann zum Beispiel die Vergrößerung des Parameters blocksize schaffen.

Gefundene Eckendes grauen Quaders(Bild 1)
Autor
Wenn man das Beispielprogramm aus Listing 1 auf die Datei Bild2.jpg des ersten Artikels anwendet, kann man sehen, dass die Enden der Linien (rote Markierungen) sehr gut erkannt werden (vergleiche Bild 2). Der Kreis dagegen liefert natürlich keine Eckpunkte. Die Analyse eines Bildes mithilfe der Eckpunkte wird immer schwieriger, je mehr Details das Image enthält.
Formen erfassen
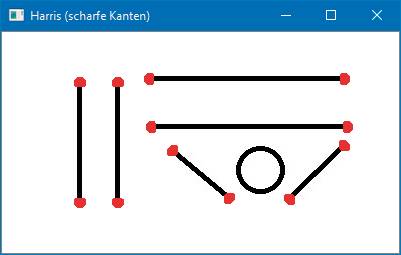
Eckenan Linienendenerkennen(Bild 2)
Autor
Im nächsten Schritt sollen nun einfache grafische Objekte (englisch: shapes) in einem Bild erkannt werden. Die Grundlagen dafür haben wir in den vorherigen Beispielen gelernt.Um ein grafisches Grundelement (Kreis, Rechteck, Banane …) zu identifizieren, muss man zunächst einmal den Umriss des jeweiligen Objekts ermitteln. Dies lässt sich mithilfe der bereits bekannten Kanten- und Ecken-Algorithmen erledigen. Bild 3 zeigt eine Zusammenstellung verschiedener grafischer Elemente.
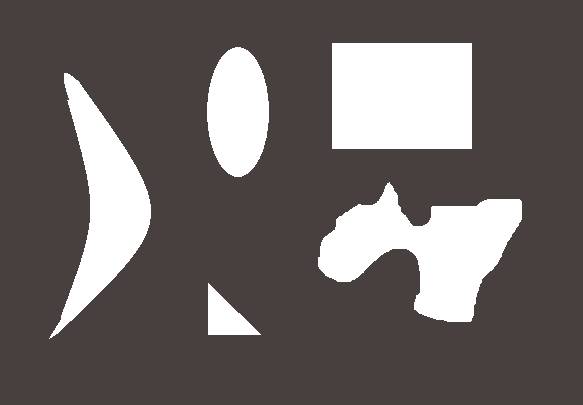
Grundelementegrafischer Formen(Bild 3)
Autor
Auf der linken Seite des Bildes befindet sich die „Banane“, die identifiziert werden soll. Dazu benötigen wir zunächst ein Vergleichsbild für eine „Standardbanane“ (Bild 4).

Vergleichsbildder „Standardbanane“(Bild 4)
Autor
Der einfachste Algorithmus, der die Banane aus Bild 4 in Bild 3 entdeckt, funktioniert durch die Zählung der Pixel, die zu einem grafischen Objekt gehören. Das bedeutet, dass man zuerst die Umrisse aller Objekte ermittelt, dann die Pixel zählt, die zu dem jeweiligen Shape gehören, und schließlich prüft, welche ermittelte Pixelsumme der Standardbananen-Pixelsumme in Bild 4 am nächsten kommt.Diese einfache Variante ist aber nicht sonderlich genau. In Wirklichkeit ist die Sache also etwas komplizierter. Es werden die sogenannten Hu-Momente berechnet, die angeben, wie gut die Übereinstimmung zweier Konturen ist. Die Mathematik, die hinter der Hu-Moment-Berechnung steckt, wird sehr ausführlich in [4] erklärt. Die Berechnung des Moments I erfolgt prinzipiell folgendermaßen:
I = ∑ wi * pik
Hier sind pi die Pixel der Grafik in der Potenz k. wi sind die Wichtungen der einzelnen Pixel pi. Dabei handelt es sich in der Regel um Funktionen f(x, y), die zum Beispiel bestimmte Teile eines Grafikelements stärker bewerten können als andere Bereiche. Für das gesamte Moment I wird die Summe über alle Pixel i berechnet.Zum Glück stellt uns OpenCV die Funktion matchShapes zur Verfügung, der einfach einen skalaren Wert zurückgibt, der die Übereinstimmung zweier Grafikelemente bestimmt. Die Sache ist dann ganz einfach: Je kleiner der Rückgabewert, desto besser die Übereinstimmung (optimale Übereinstimmung ergibt den Wert 0.0).Jetzt aber los! Wir wollen die Grafik aus Bild 4 in Bild 3 finden. Das komplette Programm wird in Listing 2 gezeigt.Das Programm beginnt wie üblich mit den verwendeten Bibliotheks-Modulen. Danach erfolgt die Definition zweier grundlegender Funktionen: getAllContour analysiert ein Bild und sucht alle Konturen der grafischen Elemente. Die Funktion getRefContour ermittelt die Kontur der Grafik im Referenzbild und gibt die Konturfläche an den Aufrufer zurück.
Listing 2: Ein Grafikelement suchen … und finden
import cv2
import numpy as np
# Alle Konturen in einem Image ermitteln
def getAllContour(img):
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(imgGray, 127, 255,
cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(
thresh.copy(), \
cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
return contours
# Kontur im Referenzbild ermitteln
def getRefContour(img):
contours = getAllContour(img)
for contour in contours:
area = cv2.contourArea(contour)
imgArea = img.shape[0] * img.shape[1]
# Hier wird das Verhältnis von Gesamtfläche
# des Bildes und des Grafikelements bestimmt
if 0.05 < area / float(imgArea) < 0.8:
return contour
return None
######### Hauptprogramm #################
# Ein Referenzbild laden (Standardbanane)
imgRef = cv2.imread(".\images\Bild4.png")
#imgRef = cv2.imread(".\images\Bild5.png")
# Das Testbild laden (mehrere Grafikelemente)
imgTest = cv2.imread(".\images\Bild3.png")
# Konturen ermitteln
contRef = getRefContour(imgRef)
contTest = getAllContour(imgTest)
# Vergleich der Referenzkontur mit den
# im Bild gefundenen Konturen
resultCont = None
minDist = None
i = 0
imgCont = imgTest.copy()
# Alle Konturen in Rot einzeichnen
cv2.drawContours(imgCont, contTest, -1, color=(
0, 0, 255), thickness=2)
cv2.imshow("Gefundene Konturen", imgCont)
cv2.imshow("Referenzfigur", imgRef);
# Liste aller gefundenen Konturen abarbeiten
for cont in contTest:
i += 1
# Ermittlung der Übereinstimmung
ret = cv2.matchShapes(contRef, cont,
cv2.CONTOURS_MATCH_I3, 0.0)
print("Kontur Nr. %d passt zu %f" % (i, ret))
# Übereinstimmungswert und Kontur merken, wenn
# besser
if minDist is None or ret < minDist:
minDist = ret
resultCont = cont
# Ergebnisausgabe, gefundene Kontur in Grün markieren
cv2.drawContours(imgTest, resultCont, -1, color=(0,
255, 0), thickness=4)
cv2.imshow("Bester Treffer", imgTest)
cv2.waitKey(0)
######## Ende des Hauptprogramms ##########
Die einzelnen Konturen in einem Bild werden mit der OpenCV-Funktion findContours gesucht. Vorher wird vom Originalbild ein Graubild erstellt und dann mit der Funktion threshold ein Bild generiert, das nur noch zwei Farbstufen enthält, zum Beispiel Weiß und Schwarz. Wenn der Wert im Graubild kleiner ist als der angegebene Grenzwert (zweiter Parameter), wird das Ergebnispixel auf 0 (schwarz) gesetzt, ansonsten auf den angegebenen Maximalwert (dritter Parameter). Die Funktion findContours ermittelt nun die Konturen und stellt sie als Liste zusammen.In der Funktion getRefContour erfolgt zunächst die Ermittlung aller vorhandenen Konturelemente. Nun wird die Fläche der Kontur festgestellt und ins Verhältnis zur Gesamtfläche des Bildes gesetzt. Ist dieser Wert größer als 0.05 und kleiner als 0.8, wird die Kontur als Referenzergebnis zurückgegeben.Kommen wir nun zum Hauptprogramm in Listing 4. Zunächst wird das Referenzbild (imgRef) geladen, danach das Testbild (imgTest), indem das Referenzobjekt gesucht werden soll. Danach sind die Konturen zu ermitteln. Nach der Initialisierung einiger Variablen wird ein Bild mit den gefundenen Konturen (imgCont) zur Kontrolle erstellt. Außerdem wird ein Bild der Referenzfigur (imgRef) ausgegeben.
Listing 4: Gesichter und Augen erkennen
import cv2
import numpy as np
# Classifier instanzieren (Gesichter, Augen)
faceCascade = cv2.CascadeClassifier(
'haarcascade_frontalface_default.xml')
eyeCascade = cv2.CascadeClassifier(
'haarcascade_eye.xml')
# Ein Bild mit Gesicht laden, Graubild erstellen
img = cv2.imread('.\images\Bild6.jpg')
#img = cv2.imread('.\images\Bild7.jpg')
frameGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Gesichter ermitteln
faceRects = faceCascade.detectMultiScale(
frameGray, 1.3, 5)
# Schleife über alle gefundenen Gesichter
for (x,y,w,h) in faceRects:
cv2.rectangle(img, (x,y), (x+w, y+h), (
0, 255, 0), 2)
# Gesichtsausschnitt für Augensuche
faceGray = frameGray[y:y+h, x:x+w]
faceColor = img[y:y+h, x:x+w]
# Augen ermitteln
eyesRects = eyeCascade.
detectMultiScale(faceGray)
# Alle Rechtecke für Augen einzeichnen
for (ex,ey,ew,eh) in eyesRects:
cv2.rectangle(faceColor, (ex,ey), (
ex+ew, ey+eh), (255, 0, 0), 2)
# Fertiges Bild ausgeben
cv2.imshow('Gesicht mit Augen', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Nun folgt die Ermittlung der Übereinstimmungen der Referenzfigur mit den im Testbild gefundenen Figuren. Dies geschieht in einer einfachen for-Schleife mithilfe der OpenCV-Funktion matchShapes. Als Parameter übergeben werden die Referenzkontur, die zu untersuchende Kontur, die gewünschte Vergleichsmethode und ein eventuell erforderlicher Zusatzparameter (abhängig vom benutzten Algorithmus).Der Rückgabewert von matchShapes wird, ebenso wie die jeweilige Kontur, abgespeichert, wenn er kleiner als das bereits vorhandene Ergebnis ist.Zum Schluss wird die Kontur, die am besten zum Referenzbild passt, im Ursprungsbild mit einem grünen Rand versehen und dargestellt.Beim Ausführen des Programms sind nun drei Ausgabegrafiken zu sehen. Bild 5zeigt alle Konturen, die im Testbild ermittelt werden. Bild 6 zeigt die Kontur, die die beste Übereinstimmung mit dem Referenzbild bietet, mit grünem Rand.
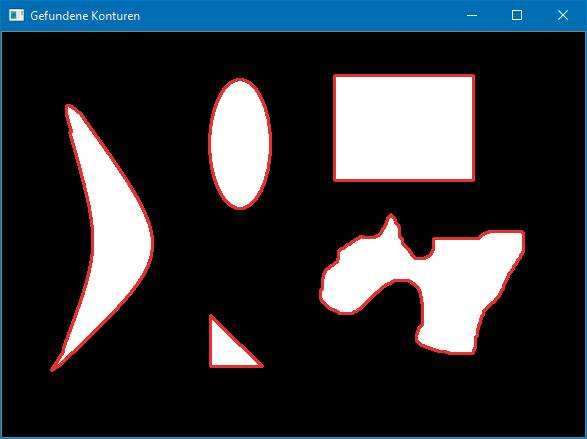
Alle Konturenim Testbild(Bild 5)
Autor
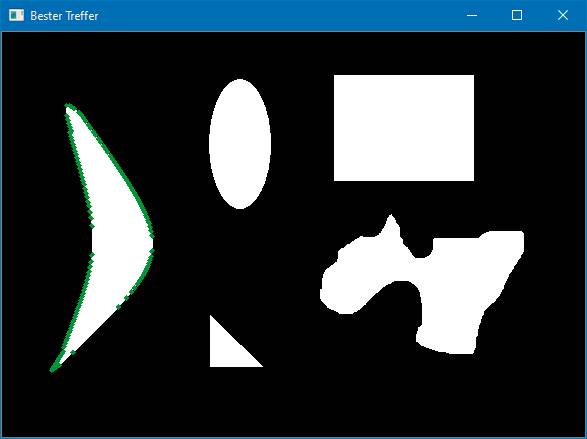
Die als „Banane“gefundene Kontur(Bild 6)
Autor
Gesichter erkennen
Nun wird die Herausforderung etwas größer. Wir wollen „natürliche“ Elemente, wie zum Beispiel Gesichter oder Augen, auf einem Bild erkennen. Da nicht jeder Mensch die gleiche Gesichtsform hat oder einige Menschen eine Brille tragen, ist das nicht ganz so einfach.Hier kommen die sogenannten Cascaded Classifiers ins Spiel, die mit den OpenCV-Bibliotheken auf dem Rechner installiert werden. Diese XML-Dateien enthalten die notwendigen Daten, um Gesichter, Profile, Augen oder ein Lächeln zu erkennen. Den Algorithmus haben Paul Viola und Michael Jones im Jahr 2001 entwickelt [5]. Listing 3 zeigt die Vorgehensweise, um Gesichter auf einem Bild zu erkennen. Nach dem Import der erforderlichen Module wird der Klassifizierer für die Frontalansicht eines Gesichts instanziert (haarcascade_frontal_default.xml). Nun kann ein Bild geladen und in ein Graubild konvertiert werden. Im Beispielcode zum Artikel stehen zwei Bilder zur Verfügung: Die Datei Bild6.jpg enthält nur ein Gesicht, die Datei Bild7.jpg zeigt mehrere unterschiedlich große Gesichtsabbildungen.Listing 3: Gesichter erkennen
import cv2
import numpy as np
# Cascaded Classifier instanzieren
faceCascade = cv2.CascadeClassifier(
'haarcascade_frontalface_default.xml')
# Bild mit (menschlichem) Gesicht laden
img = cv2.imread(".\images\Bild6.jpg")
# Bild mit mehreren Gesichtern
#img = cv2.imread(".\images\Bild7.jpg")
# Graubild erstellen
frameGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Alle Gesichter suchen
faceRects = faceCascade.detectMultiScale(
frameGray, scaleFactor=1.3, minNeighbors=5)
print("Es wurde(n) ", faceRects.size // 4,
" Gesicht(er) gefunden.")
# Alle Gesichter mit grünen Rechtecken markieren
for(x,y,w,h) in faceRects:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255,
0), 3)
# Ergebnisbild ausgeben
cv2.imshow("Gesicht(er) suchen", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Das konvertierte Graubild befindet sich in der Variablen frameGray und kann mit der Funktion detectMultiScale aus dem Klassifizierer faceCascade analysiert werden. Der erste Parameter übergibt das Bild frameGray an die Funktion, die beiden anderen Parameter sind optional und übergeben einen Verkleinerungsfaktor und einen minimalen Abstand, wenn mehrere Objekte gefunden werden. Als Ergebnis bekommt man ein numpy-Array faceRects, das die Eckpunkte der Rechtecke erhält, welche die gefundenen Gesichter umrahmen.Schließlich werden die gefundenen Gesichter noch im Ausgabebild eingezeichnet. Bild 7 zeigt das Ergebnis unserer Bemühungen. Da nun die Positionsdaten der Gesichter vorhanden sind, wäre es zum Beispiel sehr einfach, den Programmcode aus Listing 3 so zu erweitern, dass alle Gesichter unkenntlich gemacht werden. Das lässt sich einfach durch starkes Weichzeichnen im Gesichtsbereich realisieren.

Die erkannten Gesichterim Bild(Bild 7)
Autor
Der nächste Schritt ist ähnlich einfach. Um auch noch die Augen in einem Gesicht zu erkennen, benötigt man nur den entsprechenden Klassifizierer: haarcascade_eye.xml. Listing 4 zeigt ein vollständiges Beispielprogramm für die Erkennung von Gesichtern und Augen.Der Ablauf ist ähnlich wie im vorherigen Beispiel. Nach dem Import der Bibliotheken und der Instanzierung der beiden erforderlichen Klassifizierer (faceCascade und eyeCascade) lässt sich ein Bild laden und in Graustufen konvertieren (frameGray). Nun werden zuerst die Gesichter im Bild identifiziert. Die Funktion detectMultiScale des Klassifizierers faceCascade liefert die Rechtecke im numpy-Array faceRects. So weit ist alles wie gehabt.Nun wird in einer Schleife über alle Gesichts-Rechtecke iteriert. Zuerst erhält das Gesicht ein grünes Rechteck a. In diesem kleinen Rechteck (faceGray) wird nun ebenfalls mit detectMultiScale, aber mit dem Klassifizierer eyeCascade nach den Positionen der Augen gesucht. Für die Suche wird das Graubild benutzt. Je nach dem Ergebnis der Suche findet man kein, ein oder mehrere Rechteck(e). Das Array der Augen-Rechtecke wird nun in einer weiteren Schleife verarbeitet und im Ergebnisbild blau ausgegeben.
Bewegte Bilder aus der Webcam
In diesem Artikel wurden alle Beispiele mit statischen Bildern ausgeführt. Natürlich lassen sich mit OpenCV auch bewegte Bilder, zum Beispiel aus einer Webcam, analysieren. Hierfür muss die Kamera korrekt auf dem Rechner installiert sein, und die notwendigen Änderungen am Code sind geringfügig:import cv2
import numpy as np
# ...
# Video-Quelle definieren
capCam = cv2.VideoCapture(0)
# Ein Bild einlesen (in Schleife)
ret, frame = capCam.read()
# Zum Beispiel Gesichter erkennen
faceRects = faceCascade.detectMultiScale(frame, ...)
# ...
capCam.Release()
# ...
Nach der Definition der Bildquelle lässt sich ein Videobild mit der read-Funktion einlesen und ganz regulär wie ein statisches Bild weiterverarbeiten.Das Einlesen der Bilder aus einer Videokamera wird in der Regel in einer Endlosschleife durchgeführt. In solchen Fällen ist es natürlich besonders wichtig, dass die Bildanalyse sehr schnell erfolgt und die Ergebnisse zeitnah zur Verfügung stehen.
Zusammenfassung
In den beiden OpenCV-Artikeln konnte leider nur ein sehr kleiner Teil der Möglichkeiten dieser Bibliothek vorgestellt werden. Man kann hierzu problemlos noch zehn weitere Artikel über interessante Themen schreiben.
Gesichts- undAugen-erkennung(Bild 8)
Autor
Wir haben gesehen, wie man durch einfache Funktionsaufrufe grafische Grundelemente oder komplexe Bildelemente identifizieren kann. Die OpenCV-Funktionen kann man sehr gut und mit geringem Aufwand aus kleinen Python-Programmen aufrufen.Trotzdem ist die Bildanalyse nicht immer so einfach wie in den hier gezeigten Beispielen. Oft müssen die Bilder sehr aufwendig bearbeitet werden, damit eine sichere Erkennung der Bildelemente möglich ist. Manchmal können Bilder unscharf, zu dunkel, zu hell oder verrauscht sein, was die Bildanalyse sehr erschwert.Mittlerweile ist die Thematik Computer Vision aus Industrie, Fertigung, Fotografie, Objektüberwachung und vielen anderen Bereichen aber nicht mehr wegzudenken, und sie wird auch in der Zukunft sicherlich noch intensiv weiterentwickelt werden.
Fussnoten
- Bernd Marquardt, Bildinhalte erkennen und verarbeiten, dotnetpro 10/2020, Seite 84 ff.,
- Bernd Marquardt, Arrays mit Schleife, Mathematik mit Python, Teil 1, dotnetpro 12/2017, Seite 64 ff.,
- cornerHarris-Funktion,
- Hu-Moment-Berechnung,
- Cascaded Classifiers,









