
17. Jan 2022
Lesedauer 8 Min.
Mesh? Was ist das denn?
Microservices vernetzen
Es hat was mit Netzen zu tun. dotnetpro stellt diese Service-Kategorie in Bezug zu Diensten und Daten vor.

So mancher mag bei dem Begriff Mesh an die US-TV-Serie M.A.S.H. denken oder – wie es mit Assoziationen eben so ist – gar etwas Faschiertes damit in Verbindung bringen. Es ist keines von beidem. Tatsächlich ist es ein Konzept für vernetzte Computer und eine Service-Kategorie für Microservices. Microservices kapseln Funktionalitäten in atomare Einheiten. Die Devise lautet: Mach genau nur eine Sache, aber erledige sie perfekt. Dieses Prinzip ist aus der objektorientierten Programmierung als Single-Responsibility-Prinzip bekannt.Dazu kommt ein Design der strikten Trennung, das dafür sorgt, dass sich skalierte Applikationen besser anpassen lassen und Microservice-Architekturen sehr robust sind. Fällt ein Dienst aus, so soll das – zumindest in der Theorie – möglichst keine anderen Microservices beeinflussen.Übersetzt bedeutet der Begriff Mesh Netz und/oder Masche. Es gibt verschiedene Kategorien von Meshs. Zusammen genannt werden oft Service- und Data-Mesh. Ein Service-Mesh etwa wird definiert als „a dedicated infra layer that provides a uniform way to connect, secure and monitor inter-communication within microservices“. [1]Ziel eines Mesh ist es demnach, einzelne Dienste oder Applikationen miteinander zu vernetzen. Viele Definitionen schränken Meshs jedoch nicht auf Microservices ein. Theoretisch könnte man jedes Mesh auch über monolithische Applikationen stülpen, aber Meshs ergeben erst mit Microservices einen Sinn.Um den Sinn zu verstehen, muss das Problem verstanden werden, das ein Mesh lösen soll. Es tritt in Szenarien auf, in denen eine Architektur aus einer Vielzahl an Microservices besteht. Wer komplexe Lösungen angeht, indem er isolierbare Funktionalität in eigene Dienste kapselt, wird sich auch durchaus vorstellen können, dass dies immense Dimensionen annehmen kann.Es liegt also eine Horde Microservices vor, die untereinander kommunizieren – aber wie? Soll diese Kommunikation verschlüsselt erfolgen? Bietet sich eine Kommunikation mit einer Authentifizierung und Autorisierung via TLS an? Oft sind Routing-Mechanismen und ein Loadbalancing erforderlich. Auch das Überwachen von Traffic und das Erstellen von Metriken ist ein Thema, das oft unter dem Begriff Observability zusammengefasst wird.Würden diese zusätzlichen Funktionalitäten für die Kommunikation direkt in die Microservices eingebunden werden, würde das die Dienste überladen. Ab einer gewissen Komplexität würden einzelne Dienste zu „Macro Services“ anwachsen. Eine gute Architektur, die auch auf Prinzipien wie Separation of Concerns aufbaut, zielt also darauf ab, Geschäftslogik von den oben genannten Merkmalen zu trennen. Doch wie schafft man das am besten?
Sidecar
Hier hilft das Entwurfsmuster Sidecar, das Komponenten einer Anwendung in separate Prozesse aufteilt. Es leitet sich von dem englischen Begriff „sidecar“ für ein Motorradgespann (Motorrad mit Beiwagen) ab [2]. Die Idee ist, an jeden Dienst einen weiteren Dienst anzudocken, der die gerade genannten einheitlichen Funktionalitäten erfüllt (Bild 1). Programmierer kennen diesen Ansatz bereits vom Mixin-Entwurfsmuster [3].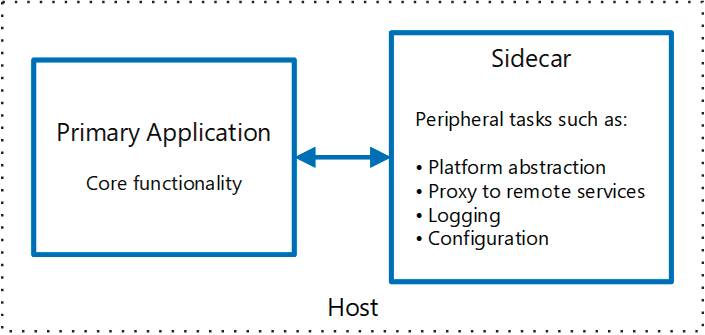
Beiwagen für Software:Das Entwurfsmuster Sidecar stellt jedem Dienst einen weiteren zur Seite, um ihn zu entlasten(Bild 1)
Autor
Manche Entwickler, die heute von Containern sprechen, nutzen Docker als Synonym für die technische Implementierung von Containern, obwohl es auch andere Produkte gäbe, wie zum Beispiel rkt [4], die Container bereitstellen. Die Situation Dockers grenzt an eine Monopolstellung. Was Docker für Container ist, ist Envoy für das Sidecar-Muster. Envoy ist die Standardtechnologie, über die ein Sidecar-Proxy implementiert ist. Envoy ist auch das Framework, das bei bekannten Service-Mesh-Implementierungen wie Istio [1] verwendet wird. Wer hier in die Details eintauchen will, wie Envoy als Proxy agiert, kann sich mit den Tutorials dazu beschäftigen [5]. Die Bereitschaft, in die Plattformdetails einzutauchen, ist notwendig.
Planes in the Mesh
Ein Paradigma von Service-Meshs ist die Trennung in Data Plane und Control Plane. Manche rechnen auch einen Management Plane dazu. Zentral ist, die Steuerung von Prozessen und die Ausführung zu trennen (Bild 2).
Service-Meshswerden in Data Plane, Control Plane und Management Plane unterteilt(Bild 2)
Autor
Als Frameworks, die diese Funktionalitäten implementieren, werden immer wieder drei genannt: Istio, Consul Connect [6] und Linkerd [7]. Alle drei haben Stärken und Schwächen. Zusätzlich gibt es auch Cloud-native-Lösungen wie AWS AppMesh [8].Zusammenfassend lassen sich Service-Meshs also als Frameworks zusammenfassen, die als Sidecar-Proxies implementiert werden, welche an Pods und Container angedockt werden könnten, um nichtfunktionale Anforderungen zu erfüllen.
Data-Mesh
Während sich ein Service-Mesh auf das Zusammenspiel von Diensten auf Netzwerkebene konzentriert, ist ein Data-Mesh das logische Pendant auf Datenebene. Was beide verbindet, ist, dass sie sich auf Microservice-Ebene vernetzen. Abgesehen davon sind sie aber grundverschieden.In der Vergangenheit gab es mit Datawarehouse und Data Lakes [9] zwei Konzepte, die auf einer zentralen Datenhaltung aufbauen. Die Idee war immer die gleiche: Um operationale Systeme nicht zu beeinträchtigen, wird die Analyse von Daten in ein zweites System verschoben, das auch für die Aggregation von Informationen optimiert ist. Daten aus operativen Systemen wurden hierfür via ETL (Extract, Transform, Load) in analytische Systeme geladen.Data Lakes und Datawarehouses sind also Lösungen, um aus einer enormen Datenmenge Erkenntnisse via Analytics zu gewinnen. Sie unterscheiden sich im Laden und Speichern von Daten. Data Lake baut im Regelfall auf verteilten Dateisystemen auf. Das Laden ist schnell und erfolgt durch Kopieren von Daten auf den Data Lake. Die danach folgenden Lesezugriffe sind langsamer, da sie die Daten beim Lesen interpretieren müssen.Beim Datawarehouse stellt das Laden den Flaschenhals dar. Die Daten müssen verändert werden, damit sie in ein Schema passen. Nach der Optimierung aller Parameter, wie etwa Indizes, verläuft das Lesen der Daten schnell.In den letzten Jahren waren diese beiden zentralen Systeme häufiger Kritik ausgesetzt. Neben einer hohen TCO waren es auch mangelnde Ausfallsicherheit und die Konsequenz eines Ausfalls, die IT-Leitern Sorge bereiteten. Würde ein großes System-Update einer zentralen Datenhaltung schiefgehen, könnte es sein, dass ein komplettes Unternehmen auf analytische Auswertungen verzichten muss.Ein Big-Data-System baut darauf auf, Hardware auszureizen. Die Anbieter haben viel Zeit und Energie in Technologien investiert, um die Ressourcen der Cluster-Knoten zu verwalten. Bei zu vielen parallelen Datenabfragen konnte ein System trotzdem schon mal in die Knie gehen.Zentrale Systeme wurden in einem gewissen Sinne dafür geschaffen, Kunden eine Lösung bestehend aus Hardware und Software bereitzustellen, die in einem eigenen Datacenter (on-premise) läuft. Cloud-Systeme erzwingen einen Paradigmenwechsel, der die Rahmenbedingungen verändert, wie Applikationen geschrieben werden müssen, damit eine Migration in die Cloud sinnvoll ist.Microservice-Architekturen und in weiterer Folge auch Serverless-Architekturen wurden für die Cloud geschaffen. Es war nur eine Frage der Zeit, bis auch eine Lösung verfügbar war, die auf Microservices aufbaut.Ein Data-Mesh kann als Pendant zu Data Lakes und Datawarehouses gesehen werden, in dem Daten dezentral gespeichert werden. Barr Moses, Mitbegründerin und CEO von Monte Carlo, definiert ein Data-Mesh wie folgt und illustriert es mit einer Grafik von Zhamak Dehghani [10]:„Data meshes federate data ownership among domain data owners who are held accountable for providing their data as products, while also facilitating communication between distributed data across different locations.“ [11]Ein Data-Mesh darf nicht auf die technologische Umsetzung via Microservices reduziert werden. Die Idee, einzelne Funktionalität in Microservices zu kapseln, wird mit einem bekannten architektonischen Ansatz verbunden: Domain-driven Design (DDD). Eric Evans, von dem das DDD-Paradigma ausgeht, legte beim Entwurf von Software den Fokus darauf, die Anforderungen bestmöglich zu verstehen. Dafür soll die Domäne, die als Software funktional umgesetzt werden soll, vorab modelliert werden.Geschäftsprozesse sind Domänenobjekte, die als Vorlage der Funktionalität der Microservices dienen. Jede Domäne hat einen Eigner, der zu erwartende Ergebnisse festlegt. Auch hier ist die Unterscheidung in operativ und analytisch möglich. Microservices können auch Daten für Auswertungen bereitstellen, um so auch analytische Themen abzudecken.Ein Beispielszenario aus der Praxis: In einem Krankenhaus kommt eine Person mit Beschwerden in die Aufnahme, ihre Daten werden erfasst und mit ihrer Krankenversicherung abgeglichen. Je nach Datenschutzbestimmungen des Landes könnte auch eine Krankenhistorie abrufbar sein. Von der Aufnahme bis zur Behandlung gibt es zahlreiche weitere Prozesse: Die Verfügbarkeit von Personal oder medizinischen Geräten abrufen; statistische Daten sammeln; und sollte es notwendig sein, muss die Person auch als Patient angelegt und ihr ein Bett zugewiesen werden. Ohne diesen Ablauf im Detail zu modellieren ist klar, dass es viele verschiedene Abläufe gibt, die alle in Domänen oder Microservices isolierbar sind.Eine Microservice-Architektur würde nun diese Funktionen einzeln kapseln. Die Aufnahme von Personen ist unabhängig von der späteren Behandlung. Auch wenn die Daten, die dabei gesammelt werden, den weiteren Prozess bestimmen, lässt sich dieser Prozess isoliert betrachten.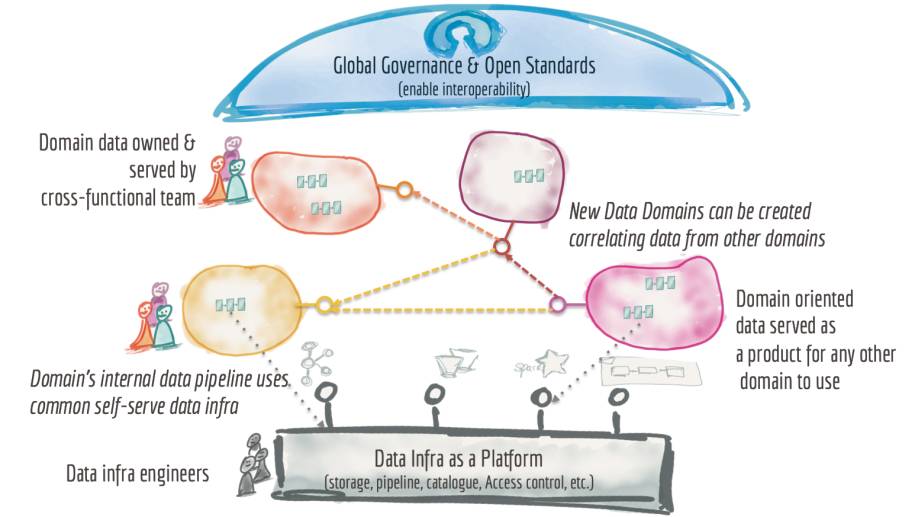
Ein Data-Meshlässt sich als Datawarehouse betrachten, das Daten dezentral speichert(Bild 3)
Autor
Beim Data-Mesh wird die Verantwortung über Daten auf Personen, die Eigner der Domäne, übertragen. Das betrifft auch die Katalogisierung von Daten, besteht doch beim
Data Lake die Gefahr, dass er zu einem Sumpf wird, zu
einem Data Swamp [12]. Das heißt nichts anderes, als dass niemand weiß, welche Daten überhaupt im Data Lake gespeichert sind.
Data Lake die Gefahr, dass er zu einem Sumpf wird, zu
einem Data Swamp [12]. Das heißt nichts anderes, als dass niemand weiß, welche Daten überhaupt im Data Lake gespeichert sind.
Praktische Umsetzung
Während es im Service-Mesh noch Frameworks gab, die mehr oder weniger mit einer Technologie verknüpft waren, scheint es so, als sei das Data-Mesh eher ein Konzept als ein Framework. Darin ähnelt es dem Data Lake. Dort sprechen Entwickler auch oft davon, dass sie einen Data Lake auf Hadoop aufbauen, dem ein verteiltes Dateisystem zugrunde liegt. Ein Data-Mesh wäre ein System, das auf Kubernetes aufbaut. Bei Hadoop gibt es jede Menge Frameworks, die Teil des Hadoop-Ökosystems sind und Data-Lake-Funktionalitäten abbilden. Apache Hive oder Apache Oozie sind zwei Beispiele dafür; diese sind fest in Hadoop integriert.Kubernetes bietet viele Werkzeuge an, die den Aufbau eines Data-Mesh unterstützen. Werkzeuge, die ein Service-Mesh umsetzen, sind ebenfalls eine Kategorie davon. Eine wesentliche Rolle spielen dabei auch APIs, die dynamisch in Skripte eingebunden werden können. Data-Science-Lösungen wie Jupyter können somit auch Daten eines Data-Mesh einbinden.Die Cloud Native Computing Foundation (CNCF) wurde zur Administration von Projekten geschaffen, die Open-Source-Komponenten verwalten, welche für Cloud-native Lösungen verwendet werden. Viele dieser Komponenten können in ein Data-Mesh integriert werden. Mit Sicherheit wird es noch die eine oder andere Standardtechnologie geben, die für künftige Data-Meshs unverzichtbar wird.Fazit
Meshs fassen Services und Dienste zusammen, die Microservices untereinander vernetzen. Auch wenn Service- und Data-Meshs ähnliche Ziele verfolgen, unterscheiden sich beide Varianten grundlegend. Während ein Service-Mesh Pods und Container auf einer Netzwerkebene verknüpfen soll, ist das Data-Mesh ein alternatives Vorgehen, um Daten zu verwalten und für verschiedene Zwecke bereitzustellen.Fussnoten
- Istio, The Istio service mesh,
- Microsoft Docs, Sidecar-Muster,
- Mixin bei Wikipedia,
- rkt,
- Envoy, https://www.envoyproxy.io/
- HashiCorp, Consul Connect, https://developer.hashicorp.com/consul
- Linkerd, https://linkerd.io
- AWS AppMesh,
- Wikipedia, Data Lake,
- Rajiv Dholakia, Matt Fuller, Why Governance is the Critical Stitch in Data Mesh (and How to Avoid “Meshing” it Up),
- Barr Moses, What is a Data Mesh — and How Not to Mesh it Up,
- Stefan Luber, Nico Litzel, Was ist ein Data Swamp?,










