
13. Mär 2023
Lesedauer 19 Min.
Architektur blitzblank
Langlebige Softwarestrukturen schaffen, Teil 2
Welche Architekturmuster sich aus der Schichtenarchitektur entwickelt haben und welche Entwurfsmuster von besonderer Bedeutung sind.

Die Bedeutung von Mustern in der Softwareentwicklung stand im ersten Teil dieser Serie [1] im Mittelpunkt. Dabei leiteten wir ab, dass eine Softwarearchitektur auf allen Ebenen erkennbar sein und Entwicklern zu korrekten Detaillösungen verhelfen muss (schreiende Architektur). Dazu ist es essenziell, dass sich nicht nur die technischen und logischen Zusammenhänge in der Softwarearchitektur wiederfinden müssen, sondern der Gesamtaufbau auch die realen Zusammenhänge der Domäne widerzuspiegeln hat. Hierzu wurde zunächst die Schichtenarchitektur entwickelt, wobei jede Schicht Elemente der gleichen Abstraktionsstufe enthält. Bild 1 zeigt die erweiterte Form dieses Architekturmusters, mit dem wir den ersten Teil geschlossen haben. Im Folgenden gehen wir nun auf Architekturmuster ein, welche die Nachteile der Schichtenarchitektur mit völlig eigenen Ideen adressieren und sich hierbei an den Grundprinzipien von stabiler Software orientieren. Zur besseren Verständlichkeit wurden die wichtigsten Informationen des ersten Artikels noch einmal in Kästen zusammengefasst.
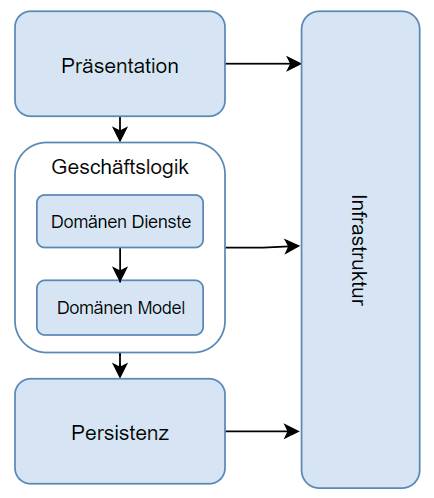
Die Vier-Schichten-Architekturmit zerlegter Geschäftslogik(Bild 1)
Autor
Hexagonal Architecture
Alistair Cockburn, Unterzeichner des agilen Manifests und Autor mehrerer Bücher über agile Entwicklung und Anwendungsfälle, fasste 2005 seinen Lösungsvorschlag für die Probleme der Schichtenarchitektur zusammen. Er nannte seine Idee zunächst Hexagonal Architecture, und dieser Name blieb bestehen – auch wenn er das Muster später erweiterte und in Ports and Adapters umbenannte. Seine Idee hat zwei Eckpfeiler: Beseitigung der Verletzung des Dependency Inversion Principle und Standardisierung der Komponentenkommunikation. Die Schichtenarchitektur verstößt gegen das Dependency Inversion Principle, da sie den Traditionen aus der Zeit des Imperativs folgt und die Persistenzschicht zur Basis der Architektur erklärt. Es stimmt zwar, dass Daten für Unternehmensanwendungen von zentraler Bedeutung sind, aber die Art und Weise, wie die Daten gespeichert werden, ist ein Implementierungsdetail. Eine mehrschichtige Architektur kann dieses Problem aufgrund der Abhängigkeitsregel nicht effektiv lösen: Abhängigkeiten können nur nach unten zwischen den Schichten verlaufen.Die Architektur von Ports and Adapters kehrt als Erstes die Abhängigkeit zwischen der Geschäftslogik und der Persistenzschicht um und macht die Geschäftslogik zur untersten Schicht. Dies wird durch die Verwendung des Separate Interface Pattern erreicht, das es der Geschäftslogikschicht ermöglicht, Schnittstellen zu definieren, die sie für die Persistenz von Daten verwenden möchte. Die Persistenzschicht, die sich nun direkt neben der Präsentationsschicht und über der Geschäftslogikschicht befindet, verweist nach unten, greift für diese Schnittstellen in die Geschäftslogikschicht und implementiert sie. Das offensichtliche Problem bei diesem Ansatz ist, dass die Implementierung der Geschäftslogik eine tatsächliche Implementierung der von ihr definierten Persistenzschnittstelle erhalten muss, um zu funktionieren, sodass diese umgekehrte Abhängigkeit an einem Punkt aufgelöst werden muss. Die vorgeschlagene Lösung ist das Plugin-Entwurfsmuster (siehe Kasten Wichtige Entwurfsmuster), das im Wesentlichen eine „Fabrik“ definiert, die entweder eine „Strategie“ verwendet oder eine Konfiguration liest, um herauszufinden, welche Implementierung einer separaten Schnittstelle bereitgestellt werden soll. Herauszufinden, was instanziert werden muss, und diese Instanzierung auszuführen, ist eine eigene Aufgabe und sollte daher von einem dedizierten Objekt übernommen werden, dessen einzige Aufgabe die Koordination dieser Instanzierungen und die Verwaltung der Lebenszeit von Objekten ist. Ein solches Objekt wird häufig als Assembler oder Bootstrapper bezeichnet, und seine Interaktion mit dem System wurde von Fowler als Dependency Injection definiert. Dieses Muster wurde 2004 beschrieben, zwei Jahre nach der Veröffentlichung von „Patterns of Enterprise Application Architecture“ [2], und gilt heute als Standard in modernen Applikationen.Wichtige Entwurfsmuster
Im Artikel werden diverse Muster von unterschiedlichen Autoren genannt. Dieser Kasten fasst die wichtigsten dieser Muster für ein besseres Verständnis noch einmal grob zusammen. Hinter jedem Pattern findet sich ein Verweis auf das entsprechende Buch, wobei PoEAA für „Patterns of Enterprise Application Architecture“ von Martin Fowler [7], GoF für „Design Patterns“ der Gang of Four [8] und DDD für „Domain-Driven Design“ von Eric Evans [9] steht.
Da Dependency Injection die Instanzierung der umgekehrten Abhängigkeit übernimmt, haben wir die Verletzung des Dependency Inversion Principle behoben und in der Zwischenzeit auch ein Muster für die Standardisierung der Komponentenkommunikation bereitgestellt. Unsere neue Schichtung besteht damit zunächst aus vier Elementen:
- unserer Geschäftslogik, die die Persistenz nutzt,
- der Schnittstelle, die die Geschäftslogik definiert,
- unserer Persistenzschicht, die diese Schnittstelle implementiert, sowie
- der Datenbanktechnologie, die unsere Persistenz steuert.
Ports and Adapters
Dieses Modell kann auf alle infrastrukturellen Belange unserer Anwendung verallgemeinert werden. Wir haben eine externe Partei, einen „Akteur“, mit dem wir kommunizieren wollen. Das kann zum Beispiel eine Datenbank, ein UI-Framework, eine Message Queue oder ein Zahlungsanbieter sein. Je nach seiner Rolle in unserer Anwendung bezeichnen wir ihn entweder als „treibenden Akteur“ (englisch: driver) oder als „getriebenen Akteur“ (driven). Treibende Akteure (oder primäre Akteure) sind Bestandteile, die unsere Anwendung steuern (Benutzeroberflächen, Batch-Treiber, Tests), während getriebene Akteure (oder sekundäre Akteure) Bestandteile sind, die unsere Anwendung steuert (eine Datenbank, eine Nachrichtenwarteschlange, eine Mock-Implementierung). Unsere Geschäftslogik wird abstrakte Aktionen ausführen wollen, die diese Akteure ausführen können, zum Beispiel die Persistierung von Änderungen oder die Anzeige von Daten. Diese Aktionen werden auf Basis des Interface Segregation Principle als Schnittstellen im Sinne der Geschäftslogik definiert und um einen bestimmten fachlichen Zweck herum aufgebaut. Diese Schnittstellen werden als Ports bezeichnet. Daher zur Verdeutlichung: Ports sind nur abstrakte Schnittstellen, die keine Logik enthalten. Weiterhin werden sie vom Client definiert, in unserem Fall von der Geschäftslogik, weshalb sie physisch in den Paketen der Geschäftslogikschicht angesiedelt sind.Der letzte Teil zur Lösung des Puzzles besteht darin, die Ports mit den Akteuren zu verbinden, und das wird von „Adaptern“ erledigt (siehe Bild 2). Diese Adapter entsprechen nicht unbedingt denen der Gang of Four, da sie in vielen Fällen auch eine gewisse Auswahllogik der zu nutzenden Implementierung enthalten. Sie folgen daher gegebenenfalls auch dem von Fowler beschriebenen Gateway. Damit übernehmen sie die notwendige Konvertierung zwischen den Aufrufen und Daten des Akteurs und der API-Definition des Ports. Für jeden Port können mehrere Adapter existieren, die gleichzeitig in Betrieb sein können oder vom DI-System je nach Konfiguration umgeschaltet werden. Ein System kann also entscheiden, ob es einen SQL-Adapter oder einen NoSQL-Adapter für seinen Persistenz-Port verwenden möchte. Es kann die Wahl zur Laufzeit treffen, indem es einige Daten in einer SQL-Datenbank speichert, aber andere, weniger strukturierte Daten in einer NoSQL-Datenbank; oder zur Konfigurationszeit, indem es eine echte Datenbank für die Produktion verwendet, aber nur eine In-Memory-Datenbank für Unit-Tests.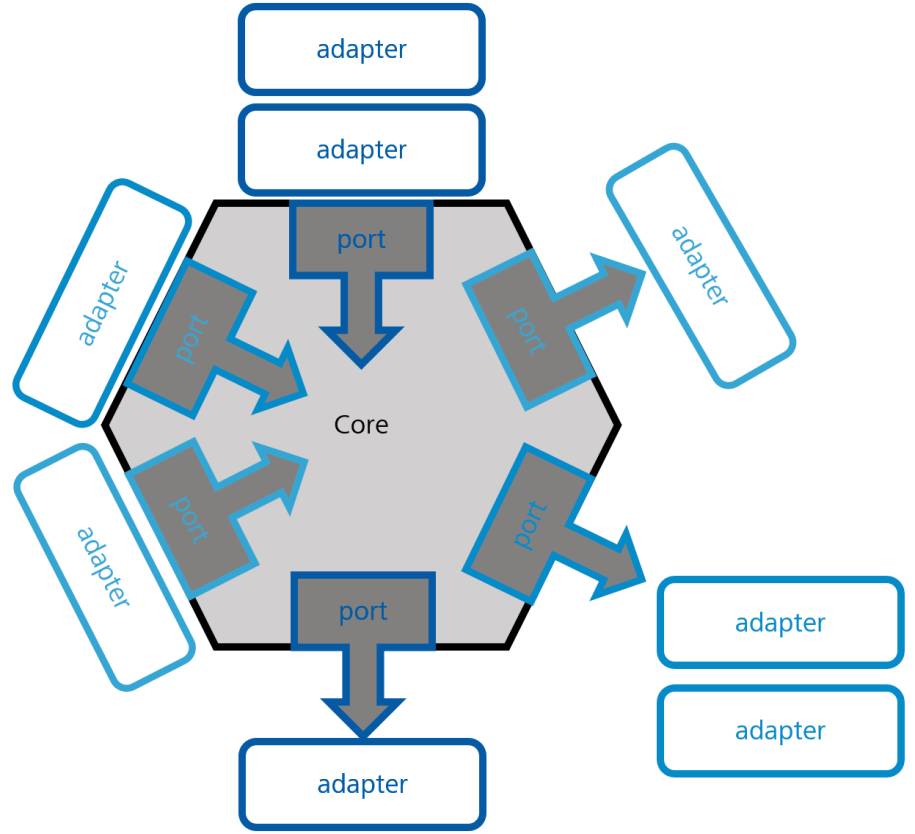
Innen-außen-Darstellungdes Musters Ports and Adapters(Bild 2)
Autor
Ein wichtiger Aspekt von Adaptern ist, dass sie außerhalb der Geschäftslogik liegen. Das bedeutet, dass es keine expliziten Referenzen von der Geschäftslogik zu diesen externen Adaptern gibt, sondern nur zu ihren generischen Schnittstellen, den Ports. Dies bedeutet wiederum, dass die Akteure externalisiert sind. Sie verweisen immer noch auf die Kernmodule, da sich dort die von ihnen implementierten Schnittstellen befinden, aber nichts verweist auf sie. Im Sinne von Robert C. Martins Beschreibungen macht dies sie instabil, sodass sie leicht ersetzt werden können. Damit entsprechen sie den SOLID-Prinzipien, siehe den gleichnamigen Textkasten.
Die SOLID-Prinzipien
Die SOLID-Prinzipien wurden von Robert C. Martin zusammengefasst [6] und adressieren die Grundprinzipien, nach denen Klassen, Module beziehungsweise Komponenten designt sein sollten. Die nachfolgenden Definitionen sind nicht eindeutig, da sich die Beschreibungen über die Zeit teils geändert haben.
Vorteile von Ports und Adaptern
Statt Ports und Adapter mit einem traditionellen Schichtendiagramm darzustellen, markiert ihre Darstellung eine Verschiebung in der Art und Weise, wie wir über Schichten denken. Im Gegensatz zu der bisher üblichen Schichtung von unten nach oben stellt das Ports-and-Adapters-Muster die Geschäftslogik in den Mittelpunkt des Diagramms und arbeitet mit internen und externen Schichten. Im Gegensatz zu anderen Mustern, die wir später behandeln, beschreibt es nur den Anwendungskern und damit den Aufbau der Geschäftslogik zusammen mit deren Ports.Das Muster enthält jedoch nicht die Adapter, also die Implementierungsdetails der infrastrukturellen Belange, wie Persistenz oder Präsentation. Die gelockerte Abhängigkeitsregel ist immer noch vorhanden, wenn auch umformuliert: Komponenten in bestimmten Schichten können immer noch nur auf Komponenten aus zentraleren Schichten verweisen. Da Fachkonzepte zentral sind, hängen sie von nichts ab, aber die externalisierte Infrastruktur hängt von diesem Kern ab, daher ist der Kern unabhängig und verantwortlich – und damit stabil. Dies bedeutet, dass wir das Prinzip der stabilen Abhängigkeiten erfüllen und in Richtung Stabilität abhängen. Das Vorhandensein von Ports im Kern macht den Kern auch hochgradig abstrakt, was bedeutet, dass wir das Prinzip der stabilen Abstraktionen erfüllen.Mit Ports und Adaptern können wir also Module erstellen, die für bestimmte Zwecke spezifisch sind, zum Beispiel ein SQL-Persistenzmodul oder ein Modul für die mobile Benutzeroberfläche. Dies bedeutet, dass Komponenten nur einen Grund haben, sich zu ändern, was dem Common Closure Principle entspricht, und dass die Architektur zumindest teilweise den Zweck der Module beschreibt. Auf diese Weise kommen wir der schreienden Architektur näher. Kurz gesagt: Vor allem in Bezug auf den Applikationskern erfüllt das Ports-and-Adapters-Muster weit mehr der Anforderungen, die wir an eine Architektur stellen, als dies die reine Schichtenarchitektur tut.Onion Architecture
Bei der Beschreibung zur Schichtenarchitektur wurde die Gesamtstruktur in drei Schichten aufgeteilt, aber bei der Behandlung des Ports-and-Adapters-Musters haben wir ständig auf die Geschäftslogik verwiesen, als ob diese Trennung der Schichten nie stattgefunden hätte. Der Grund dafür ist, dass das Ports-and-Adapters-Muster nicht im Detail darauf eingeht, wie der Anwendungskern aussehen sollte. Während wir also eine recht solide Grundlage für unsere externe Struktur haben, fehlt es uns ein wenig an der Struktur des Anwendungskerns.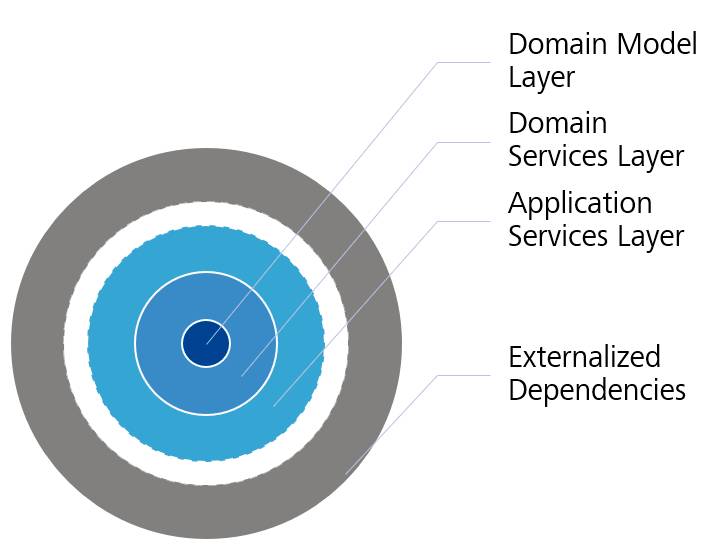
Darstellungder Onion Architecture(Bild 3)
Autor
Das nächste Architekturmuster, das wir besprechen werden, behebt dieses Versäumnis. Es heißt Zwiebel- beziehungsweise Onion-Architektur und wurde von Jeffrey Palermo im Jahr 2008 entwickelt. Das Muster befasst sich größtenteils mit denselben Problemen wie Ports and Adapters und bietet recht ähnliche Lösungen, nämlich die Auslagerung der Infrastruktur und die Konzentration auf die Geschäftslogik als Kernaufgabe. Statt sich jedoch auf die Kommunikation zwischen Kern und externen Komponenten zu konzentrieren, befasst sich das Onion-Muster mehr mit dem internen Design des Kerns. Im Wesentlichen besagt es, dass das Domänenmodell das Zentrum unseres Anwendungskerns bilden sollte. Unsere geschäftsorientierten Entitäten und Dienste befinden sich alle dort, und daher fasst das Domänenmodell das Domänenwissen unserer Anwendung zusammen. Um es herum befindet sich unser Domain Service Layer. Das Domänenmodell geht davon aus, dass alle Daten, die es verwendet, vorhanden und einsatzbereit sind. Es kann jedoch Domänenregeln geben, die externe Daten, Validierungen und andere Aspekte erfordern, die das Domänenmodell verunreinigen würden. Um das Domänenmodell frei von solchen Dingen zu halten, werden diese Belange nur als Verträge in das Domänenmodell aufgenommen und in die Schicht der Domänendienste ausgelagert.Die nächste Schicht ist die Schicht der Anwendungsdienste, die die Schnittstelle zu unserem Domänenmodell mit dem grobkörnigen API der Anwendungsfälle bereitstellt. Diese Schichtung enthält nichts, was unsere domänenzentrierte Architektur nicht auch enthielte, aber sie formuliert diese Konzepte in das Vokabular einer nicht geschichteten Architektur um. Obwohl wir also einige der hier verwendeten Konzepte bereits früher beschreiben mussten und nun kaum Neues zu berichten haben, ist die Zwiebelarchitektur historisch gesehen von großer Bedeutung, da sie explizit angibt, dass Abhängigkeiten nach innen gerichtet sind. Ports and Adapters hat dies nur impliziert.
Domain Driven Design
Die Zwiebelarchitektur ist die Grundlage für viele weitere Architekturausprägungen, die wir nachfolgend beleuchten wollen. Bevor wir damit aber beginnen, gibt es zunächst noch einen kleinen Abstecher in das Domain Driven Design (DDD). Hierbei ist es sehr wichtig, zu verstehen, dass DDD sich immer auf zwei verschiedenen Ebenen bewegt: dem Problemraum und dem Lösungsraum. Im Problemraum stehen die tatsächlich real vorhandene Domäne sowie die darin zu lösenden rein fachlichen Probleme. Diese sind beispielsweise die Prozesse zur Bestellung von Waren, zur Behandlung von Krankheiten oder zur Fertigung von Computerchips. Sie haben zunächst nichts mit der eigentlichen Softwareentwicklung zu tun, außer die abzubildende Domäne ist die Softwareentwicklung selbst. Der Lösungsraum beschreibt dann alle Konzepte, Vorgehen und Muster, die eingesetzt werden, um die fachlichen Problemstellungen zu lösen. Um diese beiden Räume voneinander zu trennen, hat Eric Evans bei seiner Beschreibung von DDD das Design ebenfalls in zwei verschiedene Ausprägungen geteilt.Im strategischen Design haben wir es mit der fachlichen und strategischen Analyse zu tun. Hierbei werden Stakeholder interviewt und langfristige Entscheidungen getroffen, aber auch die Grundlage für das Verständnis der fachlichen Domäne geschaffen. Ihre drei wichtigsten Ergebnisse aus Entwicklersicht sind dabei:- Ein Glossar, das alle Fachbegriffe erläutert, sowie eine gemeinsame und allgemeingültige Sprache aller Projektteilnehmer, die sogenannte Ubiquitous Language.
- Ein Domänenmodell, das den Aufbau des Kerns unserer Architektur darstellt und die Orchestrierung der fachlichen Prozesse beziehungsweise Workflows vorgibt.
- Ein Kontextschnitt, der klärt, welche Domänen es gibt, wie diese aufgeteilt werden, wo ihre Schnittpunkte sind und welche Wichtigkeit ihnen aus Projektsicht zugerechnet wird.
CQRS
Die Onion-Architektur führt die Schichtung, die DDD für das Domänenmodell bietet, effektiv in ein Architekturmodell ein, wie es das Muster Ports and Adapters beschreibt. Wie bereits gezeigt wurde, bevorzugen wir anstelle der direkten Verwendung von Domänenentitäten für die schichtübergreifende Kommunikation Datentransferobjekte (DTOs), um Implementierungsdetails besser vor den externen Schichten zu verbergen. Es kommt häufig vor, dass diese DTOs nur eine begrenzte Menge an Daten enthalten, da bestimmte Domänenoperationen nur Teilmengen der kompletten Domänendaten benötigen, um zu funktionieren. Zum Beispiel benötigt die Aktualisierung des Gehalts eines Mitarbeiters nur selten Datenpunkte wie das Geburtsdatum oder die Steuernummer des Mitarbeiters, auch wenn diese Daten Teil der Entität „Mitarbeiter“ sind. Wenn die Domänenentitäten komplex sind, kann die Abbildung all dieser DTOs auf Persistenzobjekte und zurück eine unnötige Komplexität mit sich bringen. Gerade bei der Ausführung großer Mengen kann der Zugriff auf diese komplexen Datensätze dann zu Leistungsproblemen und Datenkonflikten führen. Je nach Art der Daten kann das Lesen von Daten viel häufiger vorkommen als das Schreiben, sodass häufige Lesevorgänge Schreiboperationen blockieren können oder umgekehrt.Diese Probleme werden häufig dadurch gelöst, dass Datenlese- und Datenschreibvorgänge in zwei verschiedene Modelle aufgeteilt werden. Diese Modelle werden dann entweder durch sogenannte Commands aktualisiert oder über Queries abgerufen. Dadurch werden die Datenmodelle effektiv vereinfacht, da die Entitäten des Lesemodells in der Regel recht einfach sind, während die Entitäten des Schreibmodells oft eine Geschäftslogik enthalten, zum Beispiel eine Validierung. Durch diese Trennung können Daten sogar in zwei getrennte Datenspeicher verschoben werden, von denen einer für das Lesen und der andere für das Schreiben optimiert ist. Da wir also die Verantwortlichkeiten der Befehle (Commands) und Abfragen (Queries) gezielt trennen, führt uns dies zum Namen des Command and Query Responsibility Segregation Pattern, kurz CQRS.Entities-Boundaries-Interactors
Bevor wir uns der Clean Architecture zuwenden, müssen wir noch auf ein weiteres Muster eingehen. Der Grund dafür ist, dass die Clean Architecture selbst im Grunde nichts anderes ist als eine Verschmelzung von Ports und Adaptern, der Onion-Architektur und dieses letzten Leckerbissens, des EBI-Musters.EBI ist ein ziemlich altes Muster, es wurde erstmals als Entity-Interface-Control in einem Buch von Ivar Jacobson aus dem Jahr 1992 beschrieben [3]. Jacobson hat außerdem an der UML mitgewirkt und ist Erfinder des Sequenzdiagramms sowie des Konzepts der Use-Cases.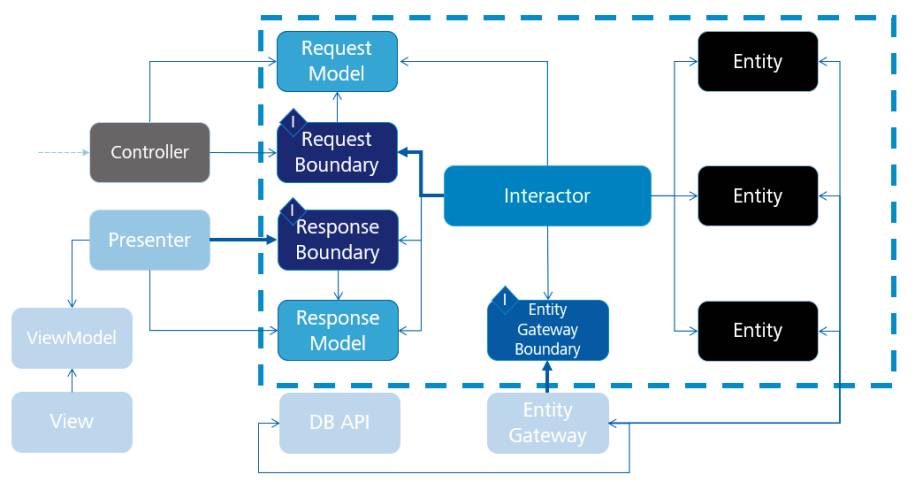
Darstellungeiner EBI-Struktur(Bild 4)
Autor
Jacobson hat das Verhalten der Geschäftslogik in drei Komponenten aufgeteilt. Diese sind sehr ähnlich zum zwölf Jahre später folgenden Domain Driven Design. Bei den drei Komponenten handelt es sich um „Entities“, die sogar den gleichen Namen wie die Entitäten von DDD besitzen, „Boundaries“ (die nicht als Schnittstellen bezeichnet werden, um Mehrdeutigkeit mit dem Sprachmerkmal zu vermeiden) und „Interactors“. Entitäten sind genau dasselbe wie in DDD: Objekte, die Geschäftskonzepte darstellen und Daten sowie anwendungsunabhängiges, also domänenspezifisches Verhalten enthalten. Boundaries sind die Schnittstellen, welche die Außenwelt mit dem System verbinden: Jede Interaktion, die ein Akteur mit dem System hat, muss über eine solche Grenze laufen. Boundaries beschreiben die Kommunikation. Sie akzeptieren bestimmte Anforderungsmodelle und produzieren bestimmte Antwortmodelle. Die Idee der Interaktoren erinnert dabei an die Ports aus Ports and Adapters und das Konzept der Lese- und Schreibmodelle von CQRS. Interaktoren sind eine besondere Art von Verhalten, das nicht von Natur aus an eine einzelne Entität gebunden ist – das bedeutet in der Regel, dass mehrere Entitäten an einem Vorgang beteiligt sind und eine von ihnen nicht als primär im Vergleich zu den anderen herausgehoben werden kann. Dies erinnert wiederum an die Domain Services in DDD oder die Befehle in CQRS. Interaktoren implementieren Grenzen, sie nehmen also Anfragen an, verändern dann den Anwendungszustand, indem sie Entitäten manipulieren, und geben schließlich Antworten.Das Muster passt somit gut zu den bisher beschriebenen Konzepten. In Bezug auf das Single Responsibility Principle sind wir aber noch nicht ganz da, wo wir sein wollen. Es besteht noch immer das Problem, dass unsere Domänenregeln – oder Anwendungsfälle – keine direkte Repräsentation in unserem System haben. So könnte es Regeln geben, die durch die Interaktion mehrerer Entitäten ausgedrückt werden, wobei der Code, der zu einer einzigen Geschäftsregel gehört, auf mehrere Codeblöcke in diesen separaten Entitäten verteilt ist. Es könnte aber auch Regeln geben, die nicht in Entitäten abgebildet werden, da es für sie bisher keinen richtigen Platz gibt. Dann schweben sie meist als Domänendienste im Vakuum und sind schwer zuzuordnen. Eine dritte Möglichkeit ist, dass Domänenentitäten und Domänendienste jeweils für die Implementierung mehrerer Geschäftsregeln verantwortlich sind und damit die Übersichtlichkeit gänzlich verloren geht. Die Lösung für diese Probleme ist etwas kontraintuitiv und wird oft als das Anemic Domain Model bezeichnet. Ein anämisches Domänenmodell wird als Anti-Pattern gesehen, da es ein Domänenmodell ist, in dem die Entitäten größtenteils ihres Verhaltens beraubt und zu einfachen Datenklassen degradiert sind. Der größte Teil des Verhaltens wird als Methoden in Domänendiensten implementiert. Dies wirkt wie eine besondere Art des Single Responsibility Principle, da man Daten und Verhalten strikt getrennt hat. Dies ist nicht ganz falsch, führt in der Praxis aber dazu, dass man nur schwer einen internen Status der Entitäten wahren kann. Letztendlich kann ja jederzeit und von allen Seiten ein Dienst etwas an einer Entität ändern, ohne dass andere Dienste über die Änderung informiert werden. Besonders schlimm wird dies, wenn diese Dienste künstlich als eine Art von Helferklassen über den Domänenentitäten zusammengehalten werden und daher ihre fachliche Ordnung komplett verloren geht. In diesem Fall ist das System so lose gekoppelt, dass es quasi auseinanderfällt. Schafft man es aber durch entsprechende Organisation und eine anständige Paketierung, die Domänendienste fachlich sinnvoll zu platzieren und zu dimensionieren, erzeugt dies eine Art von Abarbeitungssequenzen, die die tatsächlichen fachlichen Abläufe widerspiegeln. Damit erreichen wir eine sehr gute Trennung der Belange sowie eine starke Eins-zu-eins-Abbildung von Geschäftsregeln auf die Code-Artefakte. Entitäten behalten ihre intrinsischen Methoden und ihr Verhalten, das eng mit den Daten verbunden ist, jedoch heruntergebrochen auf die elementarsten Funktionen. Die Orchestrierung jener Funktionen in die umfassenderen Sequenzen macht die Domänendienste laut EBI-Pattern zu den Interaktoren, von denen jeder Interaktor mit möglichst nur einer Entität oder einem Aggregat im Sinne des Domain Driven Design arbeitet. Dies macht es den Entwicklern dann leicht, Geschäftsregeln abzubilden und im Code wiederzufinden. Dadurch vereinfacht sich dann auch die Kommunikation mit anderen Projektteilnehmern, was sich beispielsweise in einfacheren Beschreibungen von Anforderungen niederschlägt.
Clean Architecture
Stellen wir uns ein System vor, das mit Ports and Adapters aufgebaut ist, geschichtet nach der Onion-Architektur, unter Verwendung des EBI-Musters, modifiziert, um ein explizit anämisches Datenmodell zu schaffen. Wie würde ein solches System Operationen handhaben?Betrachten wir einen Fall, in dem unser imaginäres System nach dem traditionellen MVC/MVP-Entwurfsmuster aufgebaut ist, also eine Art Benutzeroberfläche hat, die mit einem Server-Endpunkt kommuniziert. Der Benutzer sieht eine grafische Benutzeroberfläche und führt von dort aus Operationen aus. Das GUI übersetzt diese Operationen in eine Anfrage an einen Controller. Der Controller ist ein Adapter, der die am Endpunkt eintreffenden Anfragen in Anwendungsfälle umwandelt, die unser System erfüllen kann. Er befindet sich in einer dünnen Schicht auf dem Server, die sich um die Datenvalidierung kümmert und sicherstellt, dass keine fehlerhaften Daten an das System weitergegeben werden können. Er kennt ein Datenmodell aus DTOs für die Anfrage und entsprechende Validierungsregeln, die dieses Modell akzeptiert – diese Objekte sind ein Port, der Web-Interaktionen mit dem Domänenmodell verbindet. Der Controller zerlegt die eingehende Anfrage und überträgt sie in eine Form, die vom Interaktor verstanden wird. Die Anfrage wird dann durch den Interaktor im Domänenmodell umgesetzt, sie ist eine explizite Geschäftsregel. Der Interaktor enthält eine einzige öffentliche Methode, die die jeweilige Geschäftsregel ausführt. Sie wird durch Dependency Injection in den Controller injiziert, wobei die Schnittstelle des Interaktors, die „Request Boundary“, verwendet wird. Der Interaktor verwendet per Depedency Injection ein Repository oder eine Factory, um Zugriff auf die notwendigen Entitäten zu erhalten. Anschließend orchestriert er die Interaktionen zwischen diesen Entitäten, um den von ihm dargestellten Anwendungsfall auszuführen. Der Interaktor muss auch eine Antwortgrenze (englisch: Response Boundary) und ein Datenmodell für seine Antwort kennen. Dies stellt einen weiteren Endpunkt und, im Fall von MVP, einen Presenter dar, der aus den Daten des Interaktors ein ViewModel erzeugt und die jeweiligen Ansichten bindet.Dieses System wurde von Robert C. Martin in mehreren Vorträgen und in seinem 2017 erschienenen Buch als „Clean Architecture“ [4] beschrieben. Tatsächlich ist dieses Architekturmuster im Vergleich zu dem, was wir bisher besprochen haben, nicht bahnbrechend. Letztendlich enthält die Clean Architecture auch keine revolutionären neuen Ideen, sie ist im Grunde eine Zusammenführung jahrzehntelanger bewährter Praktiken der Softwarearchitektur.Zusammenfassung
Um unsere Reise von der Welt des blanken Codes hin zur Clean Architecture zusammenzufassen, wollen wir noch einmal auf die Anforderungen schauen und darauf, wie sie erfüllt werden.Um die Komplexität des Codes zu zähmen, wollten wir unsere Architektur um unsere Anwendungsfälle herum aufbauen und die inhärenten Absichten offenlegen. Mit den beschriebenen Konzepten können wir Code erstellen, der eng mit unserem Verständnis unserer Geschäftsdomäne korreliert. Codekonventionen und High-Level-Strukturen sind auf den ersten Blick ersichtlich und werden durch eine Paketierung unterstützt, die jene Zusammenhänge auch physisch abbildet. Unsere Module haben nur einen Grund, sich zu ändern (wir entsprechen also den Zielen des Common Closure Principle, siehe Kasten Die Paketierungsprinzipien), sodass sowohl die Häufigkeit als auch der Schwierigkeitsgrad von Änderungen erheblich reduziert werden können.Die Paketierungsprinzipien
Diese Prinzipien sind entkoppelt von den bekannten SOLID-Prinzipien und beschreiben vor allem die Kohäsion innerhalb von auslieferbaren Paketen [10].
Wir wollten unsere Entscheidungen aufschieben und Zeit für Analyse und Entwicklung gewinnen. Aus diesem Grund wollten wir sicherstellen, dass nur die Dinge umgesetzt werden, die wir wirklich brauchen, und dass wir nicht von Dingen abhängig sind, die wir nicht brauchen (wir erfüllen also das Common Reuse Principle). Um diese Ziele zu erreichen, setzen wir stark auf Abstraktion und die Umkehrung von Abhängigkeiten. Unser Anwendungskern, der unsere Domänenlogik enthält, ist hochgradig abstrakt, da er Ports enthält, die Schnittstellen zu externalisierten Details definieren, sodass es uns freisteht, diese Details auf jede beliebige Weise zu implementieren. Der Anwendungskern ist auch sehr stabil (siehe Stable Dependencies Principle und Stable Abstractions Principle im Kasten Die Kopplungsprinzipien), da er nur von Schnittstellen abhängt, die er selbst definiert. Alle Infrastrukturbelange sind dank der intensiven Nutzung der Dependency Inversion externalisiert.
Die Kopplungsprinzipien
Dies sind ebenfalls Prinzipien, die von Robert C. Martin beschrieben wurden [6] und in diesem Fall die Abhängigkeiten zwischen Bestandteilen näher erläutern.
Ist damit aber alles perfekt oder gibt es Schattenseiten? Ja, die gibt es! Die Clean Architecture ist für die Arbeit mit erfahrenen agilen Teams konzipiert. Sie enthält viele fortgeschrittene Konzepte, von denen einige für die Entwickler nicht intuitiv sind. Es ist sehr wichtig, die Entwickler in Architekturdiskussionen einzubeziehen, um ihnen die Entscheidungen transparent zu machen. Andernfalls läuft man Gefahr, dass sie das Verständnis für die Strukturen verlieren. Jedes Team sollte in der Lage sein, Domänenkonzepte und fachliche Regeln selbst herauszufinden und im Code abzubilden, es braucht also auch erhebliche Domänenerfahrung bei den Entwicklern. Das Aufschieben von Entscheidungen ist ebenfalls ein hilfreiches Werkzeug für das Projektmanagement. Um es effektiv einsetzen zu können, muss das Projektmanagement aber auch über die Möglichkeiten und Grenzen aufgeklärt werden.Darüber hinaus ist zu beobachten, dass eine Clean Architecture sehr viele Indirektionen, aber auch Artefakte wie Module, Klassen und Pakete zur Folge hat. Dies führt zu einem größeren Wartungsaufwand, den kleinere Teams möglicherweise nicht leisten wollen oder können. Bei größeren Applikationen mit mehreren Teams ist die Abgrenzung der unterschiedlichen Wirkungsbereiche aber wichtig, damit sich die Teams nicht gegenseitig behindern. Für kleine und einfache Projekte könnten daher andere Architekturmuster besser geeignet sein, für größere Projekte mit mehreren Teams ist die Clean Architecture jedoch das Maß aller Dinge. Wie Brooks in seinem Aufsatz [5] schreibt, gibt es keine Patentrezepte und keine Einheitslösungen für alle. Clean Architecture ist jedoch ein leistungsfähiges Konzept, das in die Werkzeugkiste eines jeden modernen Architekten gehört.
Fussnoten
- Hendrik Lösch, Attila Bertok, Architektur blitzblank, dotnetpro 3/2023, Seite 28 ff.,
- Martin Fowler, Patterns of Enterprise Application Archi-tecture, Addison-Wesley, 2002, ISBN 978-0-321-12742-6,
- Ivar Jacobson, Object-Oriented Software Engineering, A Use Case Driven Approach, Addison-Wesley, 1992, ISBN 978-0-201-54435-0,
- Robert C. Martin, Clean Architecture: Das Praxis-Handbuch für professionelles Softwaredesign, MITP, 2018, 978-3-95845-724-9,
- Frederick P. Brooks, The Mythical Man-Month. Essays on Software Engineering, Addison-Wesley, 1995,ISBN 978-0-201-83595-3,
- Robert C. Martin, The Principles of OOD,
- Martin Fowler, Patterns of Enterprise Application Architecture, Addison-Wesley, 2002, ISBN 978-0-321-12742-6,
- Erich Gamma et al. (Gang of Four), Design Patterns, Entwurfsmuster als Elemente wiederverwendbarer objektorientierter Software, MITP, 2015, ISBN 978-3-8266-9700-5,
- Eric Evans, Domain-Driven Design, Tackling Complexity in the Heart of Software, Addison-Wesley, 2003, ISBN 978-0-321-12521-7,
- Robert C. Martin, Micah Martin, Agile Principles, Patterns, and Practices in C#, Pearson, 2006, ISBN 978-0-13-185725-4,










