
16. Jun 2025
Lesedauer 18 Min.
Mehr Struktur im Begriffschaos
Clean Code und Architektur – Module und Hosts
Clean Code befasst sich, wie der Name verrät, mit Code: Es werden Methoden und Klassen in den Blick genommen. Doch was ist der Fokus von Architektur?

Das Thema Clean Code hat viele Facetten. Als Entwicklerinnen und Entwickler beginnen wir mit dem Thema Clean Code in der Regel im Kleinen, auf der Ebene weniger Codezeilen. Wir denken darüber nach, wie wir einzelne Zeilen so formulieren können, dass diese möglichst verständlich sind. Hierbei geht es um Aspekte wie die Namensgebung, Kommentare, die Länge von Methoden, die Anzahl der Parameter, Codedopplungen, Verantwortlichkeiten von Methoden und Klassen und Ähnliches.Spätestens bei der Frage nach der Korrektheit kommen die automatisierten Tests ins Spiel. Plötzlich geht es dadurch um etwas größere Strukturen, da die wenigsten Methoden und Klassen ohne Abhängigkeiten auskommen. Und je größer der Codeumfang wird, je länger das Projekt entwickelt wird, desto häufiger taucht die Frage nach der Architektur auf. Wenn Clean Code die Methoden und Klassen im Blick hat, was ist dann der Fokus von Architektur? Und sollte diese nicht am Anfang stehen? Wie bei einem Gebäude, das nicht errichtet wird, bevor sich jemand über die Architektur Gedanken gemacht hat.
Herausforderungen
Die Parallelen zu anderen Branchen wie Gebäudebau, Maschinenbau, Medizin et cetera erscheinen zunächst hilfreich. Doch vielfach verstellen sie uns den Blick, weil Software eben mit sehr formbaren, virtuellen „Werkstoffen“ arbeitet. Da lassen sich Entscheidungen auf verantwortliche Weise verschieben, ohne dass es negative Auswirkungen auf den Projektverlauf hat. Wir können eben doch einen Keller unter unser Haus bauen, obschon das Haus schon steht. Die Analogien könnten uns also in die Irre führen. Vielleicht liegt ultimativ sogar der Fokus bei Softwarearchitektur genau im Aufschieben: Aufgabe der Architektur ist es, Entscheidungen jeweils zum spätestmöglichen Zeitpunkt zu treffen. Optionen sollen so lange wie möglich offengehalten werden. Die Struktur eines Softwaresystems sollte es hergeben, Entscheidungen beispielsweise zur Persistenz so spät wie möglich treffen zu müssen. So könnte zu Beginn ein einfacher Mechanismus zum Einsatz kommen, etwa die Speicherung in einer Datei. Das hat den Vorteil, dass eine erste auslieferbare Version schnell entwickelt werden kann. Allerdings muss gewährleistet sein, dass zu einem späteren Zeitpunkt leicht auf eine leistungsfähigere Technologie wie zum Beispiel eine relationale Datenbank gewechselt werden kann.Das mag im Widerspruch stehen zur immer noch anzutreffenden Vorgehensweise, mit dem relationalen Datenbankmodell zu beginnen. Vielleicht ist es das Festhaltenwollen an Sicherheit und Bekanntem, was Architektur und Struktur von Software für viele so schwierig macht.Letztlich brauchen wir Softwarestrukturen, die so flexibel sind, dass wir immer wieder neue Anforderungen umsetzen können. Doch wie finden wir heraus, ob die Struktur wirklich angemessen flexibel ist? Indem wir regelmäßig solche Änderungen durchführen. Zu viel Vordenken schadet eher. Angemessen flexible Strukturen ermöglichen uns, Entscheidungen zu revidieren und Dinge zu ändern und zu ergänzen. Aber aufgepasst: Der Fokus liegt hier auf angemessener Flexibilität. Zu viel davon, zu viele generische Lösungen behindern eher die Flexibilität, und oft stellt sich heraus, dass die vorausgedachte Flexibilität in der Weise doch nicht benötigt wird oder sie die zukünftigen Anforderungen eben doch nicht unterstützt.Agilität
Auch die Entwicklung der Agilität hat ihren Teil dazu beigetragen, viele Entwickler und Entwicklerinnen zu verwirren. Plötzlich heißt es „No big design upfront“, und die (Fehl-)Interpretation führt dazu, dass ohne jegliches Design direkt losprogrammiert wird. Schließlich empfiehlt TDD doch genau das: Beginne mit einem Test, und dann los! Es herrscht also viel Verwirrung bis Chaos im Bereich Softwarearchitektur.Aber gibt es da nicht auch die Clean Architecture als Weiterführung von Clean Code? Ja, Robert C. Martin hat sich auch mit dem Thema Architektur beschäftigt. Allerdings ist sein Beitrag der sogenannten Clean Architecture für mich eher fragwürdig, zeigt er doch nicht auf, wo die Unterschiede zu den bestehenden Architekturmodellen liegen. Bei tieferer Betrachtung stellt man fest, dass es, von Bezeichnungen abgesehen, im Kern bei drei Modellen um dieselbe Idee geht. Eine steile Behauptung! Beginnen wir also, den Nebel zu lichten.Struktur bitte!
Die mit diesem Beitrag beginnende Artikelserie hat zum Ziel, Struktur in das Chaos zu bringen. Denn im Grunde genommen ist es recht einfach, Software zu entwickeln. Die Prinzipien und Praktiken sind längst bekannt, auch wenn es gleichzeitig noch Raum für Weiterentwicklung in der Informatik gibt. Wir sollten jedoch aufhören, in jedem Projekt das Rad jedes Mal neu zu erfinden, und uns stattdessen auf eine Vorgehensweise und auf Strukturen verständigen, die sich in der Vergangenheit bewährt haben. Gleichzeitig müssen wir den Blick offenhalten für Neuerungen und diese in unser bestehendes Wissen einordnen.Beginnen wir mit der Frage, was der Begriff Architektur in unserem Kontext der Softwareentwicklung bedeutet. Softwarearchitektur beschäftigt sich mit der Frage, wie eine Software intern strukturiert sein soll. Die Bausteine, über die Architektur eine Aussage trifft, sind nicht primär die Methoden und Klassen, sondern gröbere Strukturen. Das wirft die Frage auf, ob es dann neben der Architektur eine andere Ebene geben muss, auf der ebenfalls Entscheidungen über die Zusammensetzung getroffen werden müssen. Denn auch für Methoden und Klassen muss überlegt werden, wie diese zusammenwirken. Damit sind wir bei der Aufteilung von Design oder Entwurf in zwei Bereiche (Bild 1):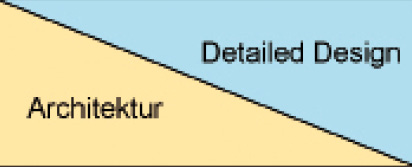
Anteile von Design in der Softwareentwicklung (Bild 1)
Autor
- Detailed Design – Aussagen über Methoden und Klassen,
- Architektur – Aussagen über Bibliotheken, Pakete et cetera.
Design
Jeder wird zustimmen, dass wir für Software ein Design erstellen müssen. Ob das nun ein expliziter Schritt ist, der mithilfe der UML oder mit Flow Design [2] vollzogen wird, sei zunächst dahingestellt. Auch ein Entwickler, der einfach drauflosprogrammiert, macht sich implizit Gedanken über das Design. Er denkt nach, bevor er codiert.Wenn das Design einer Software aus den beiden Bereichen Architektur und Detailed Design besteht, können wir die Verantwortlichkeiten wie folgt zuordnen: Aufgabe der Architektur sind die nichtfunktionalen Anforderungen, während das Detailed Design sich um die funktionalen Anforderungen kümmert. Bei manchen Entscheidungen mag es Überschneidungen geben. Trotzdem passt diese Zuordnung von Designaspekten zu Anforderungsaspekten sehr gut.Durch das Detailed Design, also Aussagen über Methoden und Klassen, beschreiben wir, wie die Lösung zu funktionalen Anforderungen aussehen könnte. So können wir beispielsweise eine Buchhaltung in Methoden und Klassen aufteilen und damit das Problem „Buchhaltung“ lösen. Ob die beteiligten Klassen auf eine oder sieben Bibliotheken (bei .NET Assemblies) aufgeteilt werden, spielt aus Sicht der funktionalen Anforderungen keine Rolle. Es ist immer noch eine Buchhaltung. Für das Deployment oder die Verteilung der Funktionalität auf mehrere Maschinen könnte es aber relevant sein. Um diese Aspekte kümmert sich Architektur. Verteilung einer Software auf mehrere Maschinen ergibt sich aus nichtfunktionalen Anforderungen.Eine solche Anforderung könnte lauten, dass die Buchhaltung von mehreren Anwendern gleichzeitig bedient werden soll. Dann muss die Software verteilt werden, eine einzelne Maschine genügt nicht. Denn dann wäre die Software nicht gleichzeitig für mehrere Anwender zugänglich. Wenn die Software auf mehrere Maschinen verteilt wird, muss zwangsläufig entschieden werden, welche Teile auf welcher Maschine laufen sollen. Hier sind wir im Bereich der Architektur. Denn wir verteilen nicht Methoden und Klassen, sondern mindestens ganze Bibliotheken.Die zweite Verantwortung von Architektur betrifft die Arbeitsorganisation. Das mag zunächst nicht intuitiv erscheinen. Doch Aufgabe von Architektur ist es eben auch, dafür zu sorgen, dass die Entwickler und die Teams flüssig arbeiten können. Dabei unterstützen uns Pakete und Komponenten. Wird das Softwaresystem von einem einzelnen Team erstellt, sind weniger Pakete oder Komponenten erforderlich, an denen unabhängig gearbeitet werden kann, als bei einer Beteiligung mehrerer Teams. Auch müssen die Schnittstellen bei der Beteiligung mehrerer Teams stärker berücksichtigt werden als bei nur einem einzigen Team.Schlussendlich haben wir im Bereich Architektur noch den Deployment-Aspekt. Für diesen kann es sinnvoll sein, ein Softwaresystem auf mehrere Microservices zu verteilen. Diese können dann einzeln deployt werden. So erreichen wir mehr Flexibilität im Deployment-Prozess. Ein anderer Grund für eine Aufteilung auf Microservices könnte sein, dass wir darüber eine bessere Skalierbarkeit erreichen können. Einige Services könnten beispielsweise in mehreren Instanzen ausgeführt werden.Um nun die genannten Begriffe präziser zu definieren, stelle ich im Folgenden die Modulhierarchie vor.Modulhierarchie
Nachdem wir das Design in Architektur und Detailed Design unterteilt haben, können wir uns der Frage zuwenden, mit welchen Bausteinen diese jeweils arbeiten. Was ist das Material, über das Architektur Aussagen trifft? Dazu sollten wir uns zunächst anschauen, mit welchen Bausteinen wir es insgesamt zu tun haben. Diese Hierarchie nennen wir Modulhierarchie. Modul ist also hier ein Überbegriff. Leider sind einige der im Folgenden verwendeten Begriffe nicht eindeutig definiert. Wir müssen damit leben, dass beispielsweise der Begriff Modul von unterschiedlichen Autoren mit unterschiedlicher Bedeutung belegt wird. Die Darstellung in Bild 2 bedeutet somit nicht die eine Wahrheit. Stattdessen beschreibe ich damit, wie ich die Begriffe verwende.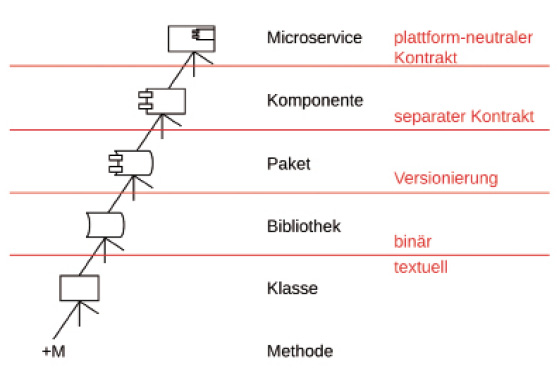
Die Hierarchie der Module (Bild 2)
Autor
Methoden und Klassen kennt jeder. Bei Verwendung des Begriffs Methode vernachlässige ich die Unterscheidung zwischen Prozedur (void, kein Rückgabewert) und Funktion (liefert einen Rückgabewert). Prozeduren und Funktionen sind beides Methoden. Wenn es notwendig ist, Funktionen und Prozeduren zu unterscheiden, kann man dies natürlich tun.Den Begriff Klasse verwende ich im Weiteren synonym zu Datei. Wenn jemand mit einer Programmiersprache unterwegs ist, die nicht zwingend Klassen benötigt, muss man sich dennoch die Frage stellen, ob man zwei Methoden in derselben Datei ablegt oder sie trennt. Am Ende ist eine Klasse oder eine Datei ein Behälter, der Methoden aufnehmen kann. Treibendes Prinzip dabei ist das Single Responsibility Principle (SRP) [3] beziehungsweise die Kohäsion. Methoden, die sich aus den gleichen Gründen gemeinsam ändern werden, sollten nah beisammen liegen. Oder wie Robert C. Martin es ausdrückt: Es darf nur einen Grund für Änderungen geben, andernfalls ist das SRP verletzt. Methoden, die für unterschiedliche Dinge verantwortlich sind, werden sich aus unterschiedlichen Gründen ändern. Daher sollten diese nicht so dicht beisammen abgelegt werden.Auf der nächsten Ebene können wir Klassen zu Bibliotheken zusammenfassen. Bei den kompilierten Sprachen wie Java, C++, C# et cetera entstehen binäre Einheiten, in denen der Quelltext nicht mehr vorhanden ist. Technisch sprechen wir hier beispielsweise von JAR-Dateien bei Java oder von Assemblies (DLLs) bei .NET. Auf der einen Seite treibt uns auf dieser Ebene die gleiche Frage um: Sollte ich zwei Klassen in derselben Bibliothek zusammenfassen? Die Antwort gibt wiederum das SRP: Klassen mit sehr unterschiedlichen Verantwortlichkeiten wird man eher nicht in derselben Bibliothek zusammenfassen. Datenbankzugriffe und UI sind so weit voneinander entfernt, dass man sie in unterschiedlichen Bibliotheken ablegen kann.Auf der anderen Seite ist das aber nur die halbe Wahrheit. Wenn ich als einzelner Entwickler eine Anwendung programmiere, muss ich meine Lösung nicht auf zig Projekte und damit Assemblies aufteilen. Ein oder wenige Projekte genügen. Vielleicht füge ich dem Projekt durch eine Aufteilung in Verzeichnisse eine weitere Struktur hinzu, damit Klassen nach Verantwortlichkeiten getrennt sind. Hier hat also die Bibliothek offensichtlich anderen Zwecken zu dienen. Wir sind plötzlich auf der Ebene von Architektur und nicht mehr beim Detailed Design (vergleiche Bild 3).
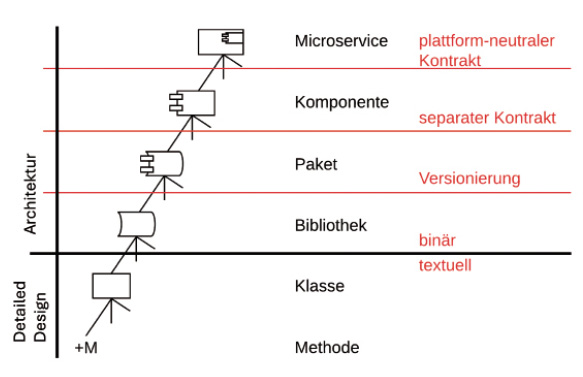
Modulhierarchie mit Zuständigkeit Detailed Design beziehungsweise Architektur (Bild 3)
Autor
Die nächsten Ebenen oberhalb von Bibliothek sind Paket, Komponente und Microservice. Pakete sind Bibliotheken, die mittels Infrastruktur versioniert sind. Im Fall von .NET ist NuGet die Infrastruktur. Der Vorteil gegenüber Bibliotheken liegt darin, dass ich über diese Infrastruktur beispielsweise Updates erkennen und installieren kann. Bei Bibliotheken müsste ich diesen Mechanismus selbst nachbilden. Insofern sind Pakete die Lösung für das Problem der Wiederverwendung. Auch innerhalb eines Unternehmens mit mehreren Teams sollte Wiederverwendung über Pakete stattfinden. Gemeinsamer Code liegt in Paketen auf einem NuGet-Server und kann dadurch in mehreren Systemen verwendet werden. Das hat vor allem den Vorteil, dass über eine geordnete Versionierung sichergestellt ist, dass Verwender nicht unbemerkt in Änderungen gezwungen werden. Stattdessen kann jeder Verwender entscheiden, zu welchem Zeitpunkt er eine neue Version eines Pakets einbindet und dabei gegebenenfalls Anpassungen an seinem System vornimmt.Als Nächstes können wir Pakete zu Komponenten zusammenfassen. Diese verfügen über einen separaten Kontrakt. Damit ist gemeint, dass der Kontrakt in einem separaten Paket abgelegt ist. Komponenten bestehen somit aus mindestens zwei Paketen: Eines enthält die Kontrakte, das andere die Implementation der Kontrakte. Kontrakte sind Interfaces sowie Datentypen, die in diesen verwendet werden. Der Vorteil liegt hier in der Arbeitsorganisation. Durch ein Contract-First-Vorgehen können Komponenten von mehreren Teams parallel entwickelt werden. Die Kontrakte definieren im Vorfeld die Schnittstellen zwischen den Komponenten. Dadurch wissen die Teams einerseits, was zu implementieren ist. Andererseits wird dadurch die Integration der Komponenten zu einem System vereinfacht.Schlussendlich liegen auf der obersten Ebene die Microservices. Diese verfügen über einen plattformneutralen Kontrakt wie etwa eine HTTP/REST-Schnittstelle. Pragmatisch gesehen können dadurch unterschiedliche Programmiersprachen zum Einsatz kommen. Das wesentliche Ziel von Microservices ist jedoch die Vereinfachung des Deployments. Statt immer „alles auf einmal“ zu deployen, können so kleinere Einheiten deployt werden.Wer nun neugierig geworden ist und mehr erfahren möchte, kann zur Modulhierarchie in [4] einiges nachlesen.Es bleibt festzuhalten, dass Bibliothek, Paket, Komponente und Microservice in der Verantwortung der Architektur liegen. Wir können das an der Frage nach den Anforderungen festmachen: Warum sollte ich meine Anwendung auf mehrere Microservices aufteilen? Bezogen auf die Anforderungen wird sich die Antwort auf eine nichtfunktionale Anforderung beziehen. Vielleicht skaliert die Lösung dann besser und kann so die nichtfunktionale Anforderung abdecken, eine bestimmte Last aufzunehmen.In Bild 3 ist zu erkennen, dass sich Architektur darum kümmert, wie eine Lösung aus Bibliotheken, Paketen, Komponenten und Microservices zusammengesetzt wird. Das Detailed Design befasst sich dagegen mit Methoden und Klassen.
Arbeitsorganisation
Neben dem Bereich der nichtfunktionalen Anforderungen ist die Architektur verantwortlich für das Thema Arbeitsorganisation. Die Struktur eines Softwaresystems wird anders aussehen, wenn ich als einzelner Entwickler eine Lösung realisiere, als bei einem Team aus sieben Entwicklern und Entwicklerinnen. Und sind mehrere Teams beteiligt, ergibt sich wiederum eine andere Struktur. Aufgabe von Architektur ist eben auch, die Kosten über die gesamte Lebensdauer eines Systems zu minimieren. Das geht einher mit der Aufgabe, die Produktivität der beteiligten Entwickler zu maximieren.Wenn mehrere Teams gemeinsam an einer Lösung arbeiten, sind mindestens Pakete erforderlich, gegebenenfalls auch Komponenten, um eine flüssige Zusammenarbeit zu ermöglichen. Nur diese Module bieten uns einen Kontrakt, der abstrakt genug ist, um die Details des Detailed Designs dahinter zu verbergen. Der Kontrakt eines Pakets wird beispielsweise durch eine oder mehrere öffentliche Klassen bereitgestellt. Diese verbergen die interne Struktur und bieten nach außen eine Dienstleistung an, die häufig mit einer einzigen Klasse oder sogar Methode nicht zu realisieren wäre. Als reiner Verwender interessieren mich diese Details nicht. Durch die Abstraktion und das Verbergen von Details hinter Paket- beziehungsweise Komponentengrenzen kann eine Lösung aus diesen groben Blöcken zusammengesetzt werden.Für die Entwicklung mit mehreren parallel arbeitenden Teams sind an den Teamgrenzen Kontrakte vorteilhaft. Diese stellen sicher, dass die Ergebnisse der einzelnen Teams zu einem Gesamtsystem integriert werden können. Es bietet sich in solchen Fällen an, an den Teamgrenzen mit Komponenten zu arbeiten.Laufzeit
Neben den Modulen gibt es einen weiteren Aspekt, der dem Thema nichtfunktionale Anforderungen zugeordnet wird: das Laufzeitverhalten. Hier beschäftigen wir uns beispielsweise mit der Frage, mit wie vielen Threads unsere Anwendung arbeiten soll. Die Antwort ist wieder in den nichtfunktionalen Anforderungen zu finden. Wird eine lang laufende Operation ausgeführt und soll die Benutzerschnittstelle während der Ausführung nicht einfrieren, können mehrere Threads eine Lösung sein. Dann kommt es im Detail weiterhin darauf an, ob wir von einer Desktop-, Mobil- oder Webanwendung sprechen, wie die Anwendung gegebenenfalls auf mehrere Rechner verteilt ist et cetera. Auch hier landen wir bei Diskussionen schnell wieder im Chaos, wenn wir uns nicht die Struktur der ganzen Begriffe vor Augen führen. Betrachten wir daher eine weitere Hierarchie: die Hosts (siehe Bild 4).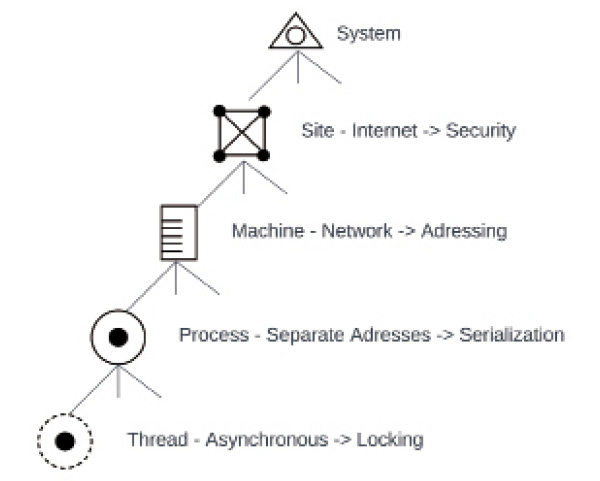
Die Hierarchie der Hosts (Bild 4)
Autor
Hosts
Auf der untersten Ebene dieser Hierarche liegen ein oder mehrere Threads. Jeder Thread läuft in einem Prozess. Die Frage, ob wir einen oder mehrere Threads zum Einsatz bringen, hängt davon ab, welche nichtfunktionale Anforderung wir umsetzen wollen. Geht es darum, dass die Benutzerschnittstelle während einer lang laufenden Operation nicht einfrieren soll, können Threads eine Lösung darstellen. Allerdings nur dann, wenn lang laufende Operation und Benutzerschnittstelle sich im selben Prozess befinden. Dies ist bei Desktop- und Smartphone-Anwendungen in der Regel der Fall. Wir können dann die lang laufende Operation auf einen Hintergrund-Thread verlagern und stellen so sicher, dass der Haupt-Thread sich weiter um das UI kümmern kann und nicht blockiert wird.Bei Webanwendungen wäre der Einsatz mehrerer Threads nur dann eine Lösung, wenn Benutzerschnittstelle und lang laufende Operation im selben Prozess und damit zwangsläufig auf derselben Maschine laufen. Wird eine lang laufende Operation, die auf dem Server ausgeführt wird, vom Browser aus angestoßen, laufen Server und Browser allerdings auf unterschiedlichen Maschinen in unterschiedlichen Prozessen. Es ist hier also nicht damit getan, einen weiteren Thread im Frontend zu verwenden, da die lang laufende Operation auf einer anderen Maschine läuft.Threads helfen uns dabei, Nebenläufigkeit innerhalb eines Prozesses zu erreichen. Was können Gründe sein, eine Software innerhalb einer Maschine auf mehrere Prozesse zu verteilen? Auch hier kann der Grund wieder sein, einen lang laufenden Prozess in den Hintergrund zu verlagern. Statt dies über einen weiteren Thread im selben Prozess zu lösen, kann ein Prozess dazu einen anderen Prozess starten oder anstoßen. Wohlgemerkt befinden wir uns hier noch auf einer einzigen Maschine. Bei Desktop- oder Smartphone-Anwendungen wird man diese Lösung eher selten einsetzen. Ein Grund könnte sein, dass wir die Programmiersprache beziehungsweise Plattform wechseln möchten. Liegt beispielsweise Legacy Code vor, in einer Programmiersprache, von der wir wegwechseln möchten, kann die Lösung darin bestehen, neue Features in einen anderen Prozess auszulagern. So können unterschiedliche Programmiersprachen zum Einsatz kommen. Die Kopplung erfolgt dann über Interprozesskommunikation. Das bedeutet, dass ein Prozess eine Nachricht an einen anderen Prozess sendet, damit dieser seinen Teil zur Lösung beitragen kann. Dadurch wird das Gesamtsystem etwas komplizierter, weil diese zusätzliche Kommunikation nicht mehr über einen Methodenaufruf innerhalb desselben Prozesses erfolgen kann.Der nächste Schritt besteht darin, mehrere Maschinen zum Einsatz zu bringen. Es laufen dann nicht mehr alle Prozesse auf derselben Maschine. Die Verteilung der Software auf mehrere Maschinen kann somit eine Lösung für die nichtfunktionale Anforderung der Verteilung sein. Ein Softwaresystem kann so von mehreren Anwendern gleichzeitig bedient werden. Jede Webanwendung folgt dieser Struktur. Ein Backend läuft auf einer Maschine, während die Frontends auf anderen Maschinen laufen. Durch Kommunikation zwischen den Frontend-Maschinen und dem Backend ist die Software damit für mehrere Anwender gleichzeitig verfügbar.Ein weiterer Grund für den Einsatz mehrerer Maschinen kann darin liegen, die Lösung zu skalieren. Verschiedene Aufgaben des Softwaresystems können so auf mehrere Maschinen deployt werden, um dadurch die Last zu verteilen.Maschine mag als Begriff etwas sperrig klingen. Warum sprechen wir nicht von Servern? Zum einen ist die Rolle einer Maschine nicht zwingend auf das Backend festgelegt. Bei einem Rechner, auf dem ein Frontend läuft, würde man eher nicht von einem Server sprechen. Zum anderen können auch virtuelle Maschinen sowie Docker-Container als Maschinen betrachtet werden. Im Vordergrund steht hier nicht die physische, sondern die logische Maschine, denn mit ihr gehen die Vorteile und Herausforderungen einher.Der nächste und letzte Schritt kann dann darin bestehen, die Maschinen auf mehrere Standorte zu verteilen. Eine Intranetlösung würde alle Maschinen am selben Standort unterbringen. Dann ist das Softwaresystem nur an diesem Standort erreichbar. Wird das Backend dagegen an einem anderen Standort platziert, beispielsweise in einem Rechenzentrum, welches über das Internet erreichbar ist, kann die Software von mehreren Standorten aus erreicht werden. Die Unterscheidung zwischen einer beziehungsweise mehreren Network Sites führt zu Intranet- versus Internetanwendungen.Änderungen an den Grenzen
In der Hosts-Hierarchie ändern sich wichtige Aspekte jeweils beim Übergang zur nächsten Ebene. Dies sollte uns als Entwicklerin und Entwickler bewusst sein, wenn wir die Entscheidung treffen wollen, eine bestimmte Ebene in der Hosts-Hierarchie für unsere Zwecke zu nutzen. Von unten nach oben betrachtet bleiben die Herausforderungen jeweils bestehen und „vererben“ sich nach oben. Muss also beispielsweise ab einer gewissen Ebene asynchron kommuniziert werden, muss auf allen weiteren darüberliegenden Ebenen ebenfalls asynchron kommuniziert werden.Threads
Verwenden wir einen einzigen Thread, können zur Laufzeit keine parallelen Zugriffe auf Speicherbereiche innerhalb des Prozesses stattfinden. Sobald jedoch mehr als ein Thread innerhalb des Prozesses zum Einsatz kommt, können Zugriffe auf Speicherbereiche aus diesen Threads parallel oder quasiparallel stattfinden. Daraus ergibt sich das Problem, dass Speicherbereiche inkonsistent werden können. Schreibt ein Thread in einen Speicherbereich und liest gleichzeitig ein anderer Thread aus demselben Speicher, kann das dazu führen, dass der lesende Thread inkonsistente Daten erhält, weil der schreibende Zugriff noch nicht vollständig beendet ist. Die Lösung lautet Locking. Während des Schreibens sperrt der schreibende Thread den Speicherbereich, sodass ein lesender Thread daran gehindert wird, während des Schreibvorgangs auf den Speicher zuzugreifen. Locking ist kein triviales Thema (siehe beispielsweise Deadlocks), sodass der Einsatz mehrerer Threads einen guten Grund haben sollte.Eine andere Herausforderung beim Einsatz mehrerer Threads ergibt sich bei Verwendung der meisten Desktop-UI-Frameworks: Ein Update von UI-Elementen aus einem Hintergrund-Thread ist in der Regel nicht erlaubt und führt zu Exceptions. Diese Zugriffe müssen auf den Haupt-Thread synchronisiert werden. Auch hier steigt somit die Komplexität durch den Einsatz mehrerer Threads.Prozesse
Beim Übergang von einem zu mehreren Prozessen liegen plötzlich die Daten in getrennten Adressräumen. Das führt dazu, dass wir nicht mehr mit Speicheradressen (Pointern) arbeiten können, wenn vom einen auf den anderen Prozess übergegangen wird. Werden für die beteiligten Prozesse unterschiedliche Programmiersprachen verwendet, kann sogar die Speicherrepräsentation der Daten voneinander abweichen. Strings können beispielsweise mit einer Längenangabe abgelegt werden oder nullterminiert sein. Selbst wenn ein direkter Zugriff auf den Speicherbereich eines anderen Prozesses möglich wäre (Shared Memory), würde dann die Interpretation des Speicherinhalts fehlschlagen.Die Lösung lautet hier Serialisierung. Daten, die vom einen an den anderen Prozess übertragen werden, müssen zuvor serialisiert werden, in ein Format, das von beiden Prozessen verstanden wird. Das Serialisierungsformat könnte beispielsweise JSON sein. Der empfangende Prozess deserialisiert die Daten wiederum in sein Format und legt sie in seinem Adressraum ab. So erfolgt die Übergabe der Daten zwischen getrennten Adressräumen und potenziell unterschiedlichen Speicherformaten.Neben den getrennten Adressräumen ergibt sich beim Einsatz mehrerer Prozesse eine weitere Herausforderung: Es wird passieren, dass ein Prozess nicht antwortet. Daher muss die Kommunikation asynchron erfolgen. Nur so ist gewährleistet, dass der sendende Prozess nicht unendlich lange auf eine Antwort des empfangenden Prozesses wartet. Über einen Time-out kann festgestellt werden, dass die Antwort nicht im vorgesehenen Zeitfenster eingetroffen ist.Auch im Fall von mehreren Prozessen haben wir es mit einer steigenden Komplexität der Gesamtlösung zu tun, sodass es gute Gründe geben sollte, warum die Entscheidung für den Einsatz mehrerer Prozesse getroffen wird.Maschinen
Werden die Prozesse auf mehrere Maschinen verteilt, bleiben die Herausforderungen der Serialisierung und Asynchronität erhalten. Auch Locking könnte ein Thema sein, wenn beispielsweise auf gemeinsame Ressourcen wie Datenbanken zugegriffen wird. Insofern spielt es also keine Rolle, ob die Prozesse auf derselben oder auf unterschiedlichen Maschinen laufen. Beim Einsatz mehrerer Maschinen kommt es allerdings zu einer höheren Latenz in der Kommunikation, da ein Netzwerktransport zwischen den Maschinen erfolgen muss. Somit darf allerspätestens jetzt nur noch asynchron kommuniziert werden.Als zusätzliche Herausforderung stellt sich die Frage der Adressierung. Damit ist gemeint, wie Prozesse auf anderen Maschinen angesprochen werden. Dies kann beispielsweise über HTTP erfolgen. In diesem Fall müssen die Maschinen über einen Namen adressiert werden können, der von einem DNS-Service in die korrekte IP-Adresse aufgelöst wird. Die Namen der beteiligten Maschinen sowie die Ports der Prozesse müssen in einer Konfiguration hinterlegt werden, statt fest im Code „eingebacken“ zu sein, damit sie bei Bedarf leicht geändert werden können.Sites
Als letzte Ebene der Host-Hierarchie kommen mehrere Network Sites oder Standorte ins Spiel. In der Regel wird man dabei über das Internet kommunizieren. Die Herausforderung liegt nun im Bereich der Sicherheit. Es muss sichergestellt sein, dass nur diejenigen Maschinen miteinander kommunizieren können, für die das vorgesehen ist. Dazu kommen Firewalls zum Einsatz. Man wird sich dann auch auf bestimmte Kommunikationsrichtungen verständigen und beispielsweise einen Zugriff von außen direkt auf einen Datenbankserver unterbinden. Des Weiteren muss beim Ansprechen eines Service über eine Authentifizierung sichergestellt sein, dass nur berechtigte Clients den Service verwenden.Fazit
Viele Entwickler und Entwicklerinnen assoziieren mit dem Begriff Architektur etwas Spannendes. Oft treffe ich in unseren Seminaren auf die Erwartung, nun ganz viel zu Klassenstrukturen zu erfahren. Doch streng genommen befasst sich damit das Detailed Design. Nun will ich keine Haarspalterei betreiben. Die Themen Detailed Design und Architektur sind natürlich spannende und auch wichtige Themen. Aus diesem Grund wird es in den folgenden Teilen dieser Artikelserie auch um die Frage gehen, wie eine Klassenstruktur aussehen kann, um die Werte Korrektheit und Wandelbarkeit optimal zu unterstützen. Der kommende Teil wird daher das Thema Abhängigkeiten in den Blick nehmen.Fussnoten
- Beispiel für Automotive SPICE,
- Flow Design, https://flow-design.info
- Clean Code Developer, Single Responsibility Principle (SRP),
- Stefan Lieser, Module, dotnetpro 3/2022, Seite 20 f.,










