
19. Sep 2018
Lesedauer 2 Min.
Neue Funktionen für Deep Speech
Mozilla
Die kommende Deep-Speech-Version 0.2.0 soll die Möglichkeit enthalten, Sprache "live" in Text zu konvertieren – also noch während die Audiodaten gestreamt werden. Auf diese Weise lassen sich Vorträge, Telefongespräche, Fernseh- oder Radiosendungen und andere Live-Streams transkribieren, während sie stattfinden.
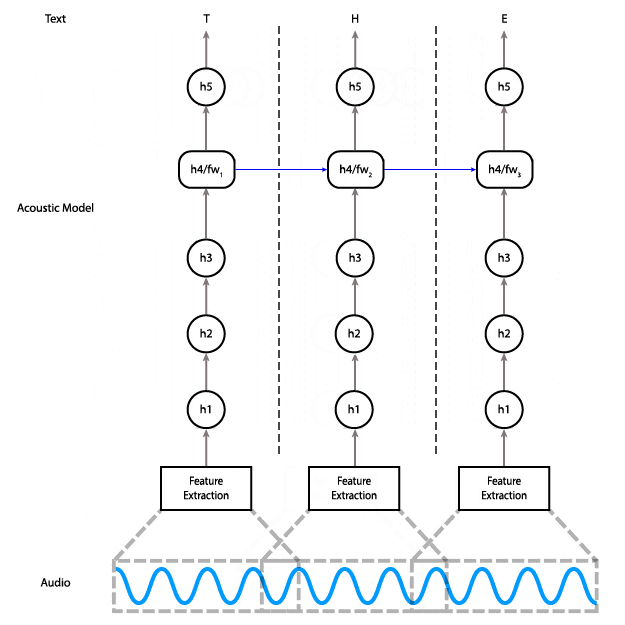
Es gibt bislang nur wenige, gut funktionierende Spracherkennungsdienste und die werden von einer kleinen Anzahl an Großunternehmen dominiert. Mit dem Projekt Deep Speech möchte das Machine Learning Team von Mozilla Research eine Open-Source-Alternative schaffen. Aktuell arbeitet das Entwicklerteam an einer Open-Source-Speech-to-Text-Engine (STT), die sich der von Nutzern erwarteten Performance annähert. Ziel des Projekts ist es, Sprachtechnologien für alle frei zugänglich zur Verfügung zu stellen – egal, ob es sich um Startups, Forschungsteams oder auch größere Unternehmen handelt, die ihre Produkte und Dienstleistungen mit Sprachaktivierung ausstatten möchten.In diesem Blog Post erklärt Reuben Morais, wie Mozilla Research die Architektur der STT-Engine geändert hat, um die Echtzeit-Transkription zu ermöglichen. Während die aktuelle Version der Engine ein bidirektionales Recurrent Neural Network (RNN) verwendet, das für das Transkribieren den kompletten Input kennen muss. Die neue Architektur setzt dagegen auf ein unidirektionales Modell, das keine Abhängigkeiten von zukünftigem Input hat.Als Performance-Vorteile gegenüber dem Vorgänger-Modell zählt Reuben Morais auf:
- Die Größe des Modells schrumpft von 468 MByte auf 180 MByte.
- Die Zeit für das Transkribieren einer 3-Sekunden-Datei schrumpft von 9 auf 1,5 Sekunden (auf einer Laptop-CPU).
- Die Spitzenbelastung des Heap sinkt von 4 GByte auf 20 MByte.
- Die Heap-Allokationen insgesamt schrumpfen von 12 GByte auf 264 MByte.











