
8. Jul 2021
Lesedauer 11 Min.
Spezielle Aufgaben
Excel-Daten mit Python bearbeiten (Teil 2)
Die openpyxl-Bibliothek bietet im Gegensatz zu pandas eine speziell auf die Excel-Umgebung abgestimmte Objekthierarchie.

Während pandas eine sehr vielseitige Bibliothek ist, die zum Beispiel auch Interaktionen mit CSV-Dateien unterstützt, ist openpyxl speziell auf die Interaktion mit Excel-Dateien zugeschnitten. Entsprechend lauten auch die zur Verfügung stehenden Klassen und Objekte. So gibt es zum Beispiel eine Klasse Workbook, die eine Excel-Arbeitsmappe repräsentiert, und die Klassen Worksheet und Cell geben ein Excel-Arbeitsblatt und eine einzelne Zelle beziehungsweise einen ganzen Zellenbereich wieder.Für die Umsetzung von speziellen Aufgaben ist openpyxl somit das Nonplusultra, wenn es um die Verarbeitung von Excel-Daten in Python-Programmen geht. Aber nicht zuletzt erweisen sich mit openpyxl auch die einfachen Dinge als besonders einfach und der resultierende Python-Code ist wegen der Excel-nahen Terminologie in der Regel gut nachzuvollziehen und damit besonders wartungsfreundlich. Dieser Beitrag ist als eine eher kurze, hoffentlich leicht verständliche, Einführung in die Bibliothek openpyxl zu verstehen. Weitere Beiträge, welche die Umsetzung spezieller Aufgaben mit openpyxl zum Thema haben, werden sich anschließen.
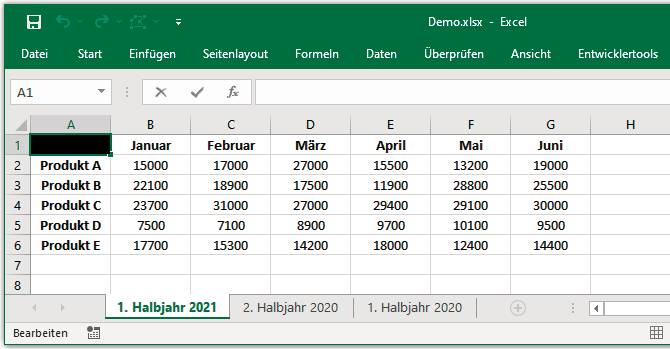
Die Excel-Tabelle,die die Basis für das Beispielprogramm bildet(Bild 1)
Saumweber
Grundlage für die Darstellung der folgenden Beispiele ist die der Demonstration halber einfach gehaltene Datei Demo.xlsx. Sie hat drei Tabellenblätter (1. Halbjahr 2021, 2. Halbjahr 2020, 1. Halbjahr 2020) mit den Umsätzen von fünf Produkten für jeweils ein halbes Jahr. Den Aufbau sehen Sie in Bild 1 anhand des ersten Tabellenblatts. Aber natürlich können Sie die folgenden Beispiele, gegebenenfalls nach kleineren Anpassungen, auch mit jeder anderen Excel-Datei nachvollziehen.
Eine Excel-Datei im Python-Code laden
Wenn Sie mit der Bibliothek openpyxl arbeiten, müssen Sie nicht abhängig davon, ob Sie Excel-Daten lesen oder schreiben wollen, zwei verschiedenartige Aktionen durchführen, wie das bei pandas der Fall ist. Vielmehr laden Sie die Arbeitsmappe in Python einmal mit der load_workbook()-Funktion und das Programm ist dann praktisch dauerhaft, also bis zum Programmende, mit ihr verbunden:
import openpyxl
wb = openpyxl.load_workbook('Demo.xlsx')
Der load_workbook()-Funktion übergeben Sie den Namen der Excel-Datei als String. Falls sich die Datei nicht im Arbeitsverzeichnis, also im selben Ordner wie die Python-Datei, befindet, müssen Sie den kompletten Pfad mit angeben. Da der optionale Parameter read_only den Standardwert False hat, können Sie im Weiteren Schreiboperationen genauso wie Leseoperationen durchführen. Geben Sie als zusätzlichen Parameter read_only=True an, wenn Sie Schreiboperationen verhindern wollen. Der Inhalt wird dann sogar für Leseoperationen optimiert. Die load_workbook()-Funktion gibt ein Workbook-Objekt zurück, das im Beispiel der Variablen wb zugewiesen wird. Über diese Variable haben Sie im weiteren Zugriff auf alle Objekte der Arbeitsmappe.
Einen Pfad mit expanduser() ergänzen
Wenn Sie eine Excel-Datei in einem anderen Ordner als in dem Ordner, in dem das Python-Skript ausgeführt wird, speichern, und Sie beim Laden der Datei deshalb den vollständigen Pfad angeben müssen, dann speichern Sie diesen am besten in einer Variablen und übergeben diese anschließend der load_workbook()-Funktion. In der Regel wird der Ordner, in dem sich die Excel-Datei befindet, ja im Benutzerverzeichnis liegen.Python-IDEs
Die aktuelle Python-Version können Sie unter https://www.python.org/downloads herunterladen. Nach der Installation finden Sie die Einträge zum Starten einer Python-Konsole in Windows 10 unter dem Buchstaben P im Ordner Python 3.x. Bei IDLE handelt es sich bereits um eine kleine Entwicklungsumgebung, die einige zusätzliche Features mitbringt. Beide, IDLE sowie die einfach Konsole, reichen aus, um ein wenig herumzuprobieren. Lesern, die sich intensiv mit Python beschäftigen wollen, raten wir zu PyCharm. Das ist eine komfortable und leicht zu bedienende IDE für Python, die Sie unter www.jetbrains.com/pycharm/download – ebenfalls kostenfrei – herunterladen können.
Mit der Funktion expanduser() des os.path-Moduls (path ist ein Submodul von os) können Sie sich dabei ein bisschen Arbeit sparen, denn expanduser(), aufgerufen mit einer Tilde, gibt den Pfad zum Benutzerverzeichnis zurück. Falls der Pfad zur Datei zum Beispiel C:\Users\<Benutzername>\Python-Projekte\Test ist, können Sie also os.path.expanduser(‘~‘) + ‚\\Python-Projekte\\Test\\<Dateiname>‘ schreiben. Im folgenden Listing lautet der Benutzername Walter und der Name der Excel-Datei ist Demo.xlsx:
import openpyxl
import sys
import os.path
filepath = os.path.expanduser('~') + '\\Python-Projekte\\Test\\Demo.xlsx'
wb = openpyxl.load_workbook(filepath)
Wenn Sie wie in obigem Listing als Pfadtrenner in gewohnter Weise den Backslash verwenden, müssen Sie diesen mit einem zweiten Backslash als Escape-Sequenz kaschieren. Sie können aber auch den einfachen Schrägstrich verwenden (filepath = os.path.expanduser(‘~‘) + ‘/Python-Projekte/Test/Demo.xlsx‘). Der Python-Interpreter evaluiert den Pfad in diesem Fall korrekt.Sie können aber auch einen Raw-String notieren, indem Sie das Präfix r vor den String setzen und dem Interpreter somit signalisieren, dass er Sonderzeichen im String nicht evaluieren soll: filepath = os.path.expanduser(‘~‘) + r‘\Python-Projekte\Test\Demo.xlsx‘. Dies ist eventuell die eleganteste Methode. Die Funktion expanduser() ermittelt den Benutzernamen automatisch; Sie können aber auch nach der Tilde explizit einen Benutzernamen angeben, zum Beispiel os.path.expanduser(‘~Walter‘). Im Übrigen funktioniert expanduser() unter macOS und Linux genauso wie unter Windows.
Arbeitsverzeichnis anzeigen und ändern
Wenn Sie das Modul os importieren, können Sie sich mit der Funktion getcwd() das aktuelle Arbeitsverzeichnis – also das Verzeichnis, in dem das Python-Programm ausgeführt wird – anzeigen lassen. Und mit der Funktion chdir() können Sie das Arbeitsverzeichnis sogar ändern. Das ist sehr praktisch, wenn Sie in einer interaktiven Sitzung (in IDLE oder in der Python-Konsole) schnell einmal etwas ausprobieren wollen und dabei auf Dateien zugreifen müssen. Dann können Sie mit der Funktion chdir() den Ordner, in dem die Dateien liegen, zum Arbeitsverzeichnis machen, um lange Pfadangaben zu vermeiden.
Für den Fall, dass eine Datei nicht geöffnet werden kann – zum Beispiel weil sie nachträglich in ein anderes Verzeichnis gelegt wurde –, bietet sich eine Fehlerbehandlung mit try-except an. Beim Versuch, eine Datei zu öffnen, die nicht existiert, stellt sich ein IOError beziehungsweise ein OSError ein (seit der Python-Version 3.3 ist IOError ein Alias für OSError). Um im except-Block die exit()-Funktion aufrufen zu können, muss zusätzlich das Modul sys importiert werden:
import openpyxl
import sys
try:
wb = openpyxl.load_workbook('examples.xlsx')
except IOError as e:
print('Error: {0}'.format(e))
sys.exit()
Ein Excel-Tabellenblatt erhalten Sie im Python-Code über das Workbook-Objekt, indem Sie den Namen des Tabellenblatts als Schlüssel verwenden, zum Beispiel mit sheet = wb[‘1. Halbjahr 2021‘], wobei wb das oben erstellte Workbook-Objekt und 1. Halbjahr 2021 der Name des ersten Tabellenblatts der Datei Demo.xlsx ist (Hinweis: Die Funktion get_sheet_by_name(), die noch hier und da in Beispielen im Internet anzutreffen ist, ist deprecated und funktioniert inzwischen nicht mehr).Alternativ zur Key-Angabe erhalten Sie das gewünschte Tabellenblatt auch per Index über das Attribut worksheets, das eine Liste von Worksheet-Objekten darstellt. Um das erste Tabellenblatt der Variablen sheet zuzuweisen, schreiben Sie in diesem Fall sheet = wb.worksheets[0]; das zweite Tabellenblatt hat den Index 1 usw. Die worksheets-Liste können Sie also auch verwenden, wenn Ihnen während der Entwicklung eines Python-Programms der Name eines Tabellenblatts noch gar nicht bekannt ist. Und schließlich erhalten Sie mit dem Attribut active das Arbeitsblatt, das gerade aktiv ist.
Aktives Excel-Tabellenblatt
Das aktive Tabellenblatt ist das Tabellenblatt, das beim Öffnen einer Excel-Datei zu sehen ist, und dieses Tabellenblatt ist auch aktiv, wenn die Excel-Datei gar nicht geöffnet ist, und das muss auch nicht notwendig das erste Tabellenblatt sein. Die Annahme, dass eine geschlossene Excel-Datei kein aktives Tabellenblatt hat – in diesem Fall würde wb.active den Wert None zurückgeben –, trifft also nicht zu.Umgekehrt ist nicht unbedingt das Tabellenblatt das aktive, das sich bei einer geöffneten Excel-Arbeitsmappe gerade im Vordergrund befindet. Excel ändert das aktive Tabellenblatt nämlich erst mit dem Speichern. Dazu ein kleines Beispiel: Angenommen, das erste Tabellenblatt einer Excel-Datei ist momentan das aktive Tabellenblatt. Der Excel-Anwender hat also dieses Tabellenblatt vor sich, wenn er die Arbeitsmappe öffnet. Wenn er nun zum zweiten Tabellenblatt wechselt und einmal speichert, ist das zweite Tabellenblatt aktiv, und auch wenn er die Arbeitsmappe zwischenzeitlich schließt und wieder öffnet, erscheint sie mit dem zweiten Tabellenblatt im Vordergrund. Speichert er aber nach dem Wechsel zum zweiten Tabellenblatt nicht, dann bleibt alles beim Alten und das erste Tabellenblatt bleibt das aktive.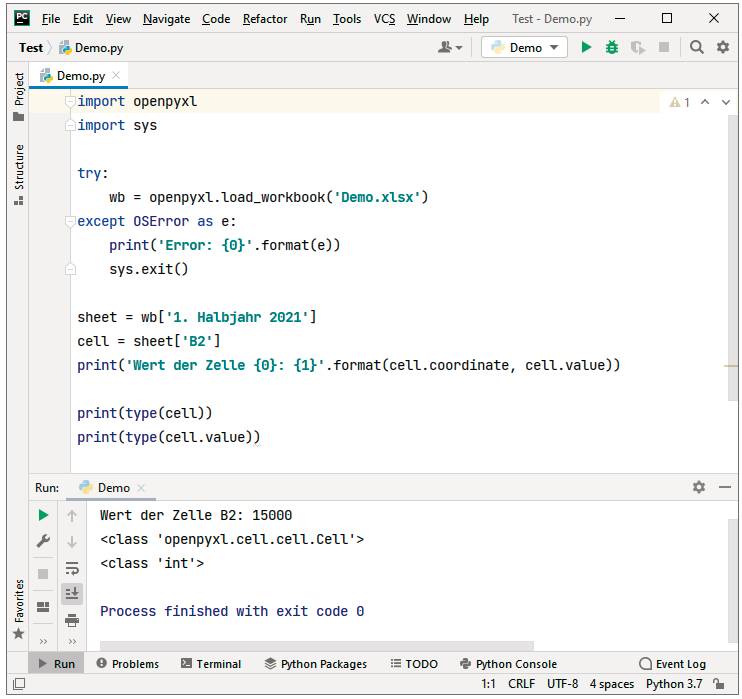
Über das Workbook-Objektgreifen Sie im Python-Code auf das gewünschte Tabellenblatt, und über das erhaltene Worksheet-Objekt greifen Sie auf einzelne Zellen zu(Bild 2)
Saumweber
Vom Arbeitsblatt zur Zelle ist es nun nicht mehr weit. Genau genommen funktioniert es genauso wie von der Arbeitsmappe zum Arbeitsblatt, nämlich indem man die Zelle, auf die man zugreifen möchte, als Schlüssel notiert:
sheet = wb['1. Halbjahr 2021']
cell = sheet['B2']
Mit der ersten Anweisung erhalten Sie ein Worksheet-Objekt, das das Tabellenblatt 1. Halbjahr 2021 repräsentiert, und mit der zweiten Anweisung erhalten Sie ein Cell-Objekt, das die Zelle B2 repräsentiert. Schließlich können Sie mit dem Attribut value auf den Inhalt einer Zelle zugreifen. Die folgende Anweisung gibt den in der Zelle B2 enthaltenen Wert aus (Bild 2):
print('Wert der Zelle {0}: {1}'.format
(cell.coordinate, cell.value))
Mit dem Attribut coordinate des Cell-Objekts erhalten Sie die Zeilen- und Spaltenangaben einer Zelle oder, wie Sie gleich sehen werden, eines Zellenbereichs. Der Inhalt von Zellen wird von openpyxl automatisch analysiert, sodass value nicht per se einen String zurückliefert. Die in der Zelle B2 enthaltene Zahl 15000 wird beispielsweise als solche interpretiert und ihr der Typ int zugewiesen, was an der Ausgabe <class ‘int‘> für die Typabfrage print(type(cell.value)) zu erkennen ist (dies geschieht übrigens unabhängig von den Excel-Formateinstellungen). Mit print(type(cell)) wird zuvor auch noch der Typ des Zellenobjekts abgefragt. Dieser ist, wie erwartet, Cell:
print(type(cell))
# Ausgabe: <class 'openpyxl.cell.cell.Cell'>
print(type(cell.value))
# Ausgabe: <class 'int'>
Sie können per Key aber nicht nur auf einzelnen Zellen, sondern auch auf ganze Zellenbereiche zugreifen. Der Ausdruck sheet[‘C1:E3‘] mit sheet als Worksheet-Objekt gibt zum Beispiel ein Tupel mit den einzelnen Zeilen des Zellenbereichs C1:E3 als Elemente zurück, beginnend mit den Zellen C1, D1, E1 der ersten Zeile. Und die Elemente des Tupels sind ebenfalls Tupel, wie die Ausgabe von print(cell_range) in Bild 3 zeigt:
sheet = wb['1. Halbjahr 2021']
cell_range = sheet['C1:E3']
print(cell_range[0])
print(type(cell_range))
# Ausgabe: <class 'tuple'>
Da die Ausgabe von print(cell_range) im Bild allerdings nur einen Teil des Zellenbereich-Objekts wiedergibt – der Rest erstreckt sich über den rechten Rand hinaus –, hier die komplette Ausgabe der cell_range-Elemente (zur Verdeutlichung zeilenweise untereinander):
((<Cell '1. Halbjahr 2021'.C1>, <Cell '1. Halbjahr 2021'.D1>, <Cell '1. Halbjahr 2021'.E1>),
(<Cell '1. Halbjahr 2021'.C2>, <Cell '1. Halbjahr 2021'.D2>, <Cell '1. Halbjahr 2021'.E2>),
(<Cell '1. Halbjahr 2021'.C3>, <Cell '1. Halbjahr 2021'.D3>, <Cell '1. Halbjahr 2021'.E3>))
Um nun zum Beispiel die Januar-Umsätze des Jahres 2021 (erstes Tabellenblatt in Demo.xlsx) aller Produkte zu addieren, benötigt man eine doppelte for-Schleife. Mit der äußeren werden die einzelnen Zeilen, also die Elemente des Zellenbereich-Tupels cell_range, durchlaufen. Das, auf was es ankommt, passiert jedoch in der inneren for-Schleife. In dieser fasst man jede Zelle einer Zeile einmal an, lässt sich deren Wert geben (cell.value), und addiert diesen zum bis dato bestehenden Wert der Variablen sum_sales, die vor Eintritt in die Schleife auf null gesetzt wird:
sum_sales = 0
for row in cell_range:
for cell in row:
sum_sales += cell.value
Damit hat man auch schon das Produkt aller Januar-Umsätze, und wenn man bedenkt, dass solche Berechnungen auch nicht mehr Programmierarbeit machen, wenn im Excel-Tabellenblatt Tausende von Werten zu addieren sind, dann erscheint es durchaus vorteilhaft, derartige Aktionen von Python und openpyxl erledigen zu lassen, statt Sie in Excel mehr oder weniger manuell durchzuführen. Hier das komplette Beispiel:
import openpyxl
import sys
try:
wb = openpyxl.load_workbook('Demo.xlsx')
except OSError as e:
print('Error: {0}'.format(e))
sys.exit()
sheet = wb['1. Halbjahr 2021']
cell_range = sheet['B2:B6']
sum_sales = 0
for row in cell_range:
for cell in row:
sum_sales += cell.value
print('Summe der Umsätze aller Produkte im Januar {0}: {1}'.format(wb.sheetnames[0][-4:], sum_sales))
Der in der print()-Ausgabe verwendete Ausdruck wb.sheetnames[0] gibt den Namen des ersten Tabellenblatts zurück – sheetnames ist eine Liste von Strings mit den Namen der Tabellenblätter einer Arbeitsmappe. Die Angabe [-4:] für den Teilbereichsoperator extrahiert aus dem String wb.sheetnames[0] die letzten vier Zeichen, also die Jahreszahl. Die Ausgabe lautet Summe der Umsätze aller Produkte im Januar 2021: 86000.
Mit openpyxl in eine Excel-Datei schreiben
Excel-Daten mit openpyxl zu schreiben ist trivial. Sie müssen die Daten nicht erst vorbereiten beziehungsweise sammeln. Sie benötigen also kein Konstrukt wie einen DataFrame, wie das bei pandas der Fall ist, sondern Sie können beispielsweise einer Excel-Zelle direkt einen Wert zuweisen. Bezogen auf das Beispiel des vorherigen Abschnitts könnten Sie also mit den folgenden Anweisungen in die Zelle A8 des Tabellenblatts 1. Halbjahr 2021 den Text Summe: und daneben in die Zelle B8 die berechnete Umsatzsumme der im Januar 2021 verkauften Produkte schreiben:
sheet['A8'] = "Summe:"
sheet['B8'] = sum_sales
Das Attribut value brauchen Sie bei der Zuweisung nicht explizit anzugeben, da es das Standardattribut von Cell-Objekten ist. Das heißt, wenn für ein Cell-Objekt kein anderes Attribut als Zuweisungsziel angegeben ist, erfolgt die Zuweisung automatisch an value. Zur Verdeutlichung kann es aber durchaus sinnvoll sein, sheet[‘A8‘].value beziehungsweise sheet[‚B8‘].value zu schreiben. Wohlgemerkt, dies gilt nur, wenn an value zugewiesen wird. An anderen Stellen im Code, zum Beispiel auf der rechten Seite einer Zuweisung, reicht die bloße Angabe des Cell-Objekts nicht, wenn man auf den Inhalt der Excel-Zelle zugreifen will.
max_row, max_column, min_row, min_column
Mit diesen Attributen des Worksheet-Objekts können Sie im Python-Code den beschriebenen Bereich eines Tabellenblatts ermitteln. Mit max_row und max_column stellen Sie fest, wo der beschriebene Bereich aufhört und mit min_row und min_column stellen Sie fest, wo er beginnt. Für das Objekt sheet des obigen Beispiels gibt der Ausdruck sheet.max_row zum Beispiel den Wert 6 zurück, da die sechste Zeile des Tabellenblatts 1. Halbjahr 2021 die letzte ist, die Daten enthält (der Index beginnt bei den genannten Attributen ausnahmsweise einmal nicht bei null, sondern bei eins; die zurückgegebenen Werte stimmen also mit der Zeilen- beziehungsweise Spaltenzahl überein). Ebenso gibt sheet.max_column den Wert 7 zurück, da die siebte Spalte (Spaltenbuchstabe G) die letzte ist, in der sich Daten befinden. Die Rückgabewerte für sheet.min_row und sheet.min_column lauten jeweils 1, da sich in der ersten Zeile und in der ersten Spalte bereits Daten befinden. Die Attribute lassen sich zum Beispiel für eine range-Angabe einsetzen, in der Regel zusammen mit einer for-Schleife wie zum Beispiel for row in range(sheet.min_row, sheet.max_row + 1). Für Berechnungen gilt es bei den Tabellenblättern von Demo.xlsx allerdings zu berücksichtigen, dass die erste Spalte keine Werte, sondern Produktnamen und die erste Zeile Spaltentitel enthält.
Wenn Excel-Daten wie gezeigt einmal mit openpyxl geschrieben sind, können Sie im Python-Code sofort – zum Beispiel für weitere Berechnungen – darauf zugreifen.
Berechnung der Umsatzsumme
Das folgende Listing führt die Berechnung der Umsatzsumme analog für Januar 2020 durch (drittes Tabellenblatt von Demo.xlsx), schreibt das Berechnungsergebnis dann in die Zelle B8 dieses Tabellenblatts und vergleicht anschließend anhand der beiden geschriebenen Werte (Zellen B8 des ersten und des dritten Tabellenblatts) die Umsatzsummen von Januar 2020 und Januar 2021 miteinander:
import openpyxl
import sys
# Arbeitsmappe laden:
try:
wb = openpyxl.load_workbook('Demo.xlsx')
except OSError as e:
print('Error: {0}'.format(e))
sys.exit()
# Umsatzsumme aller Produkte für Januar 2021 berechnen:
sheet1 = wb['1. Halbjahr 2021']
cell_range1 = sheet1['B2:B6']
sum_sales = 0
for row in cell_range1:
for cell in row:
sum_sales += cell.value
print('Summe der Umsätze aller Produkte im Januar {0}: {1}'.format(wb.sheetnames[0][-4:], sum_sales))
sheet1['A8'] = "Summe:"
sheet1['B8'] = sum_sales
# Umsatzsumme aller Produkte für Januar 2020 berechnen:
sheet3 = wb['1. Halbjahr 2020']
cell_range3 = sheet3['B2:B6']
sum_sales = 0
for row in cell_range3:
for cell in row:
sum_sales += cell.value
print('Summe der Umsätze aller Produkte im Januar {0}: {1}'.format(wb.sheetnames[2][-4:], sum_sales))
sheet3['A8'] = "Summe:"
sheet3['B8'] = sum_sales
# Umsatzsummen von Januar 2021 und Januar 2021 vergleichen:
if sheet1['B8'].value > sheet3['B8'].value:
print('Der Januar-Gesamtumsatz ist um {0} € gestiegen'.format(sheet1['B8'].value - sheet3['B8'].value))
if sheet1['B8'].value < sheet3['B8'].value:
print('Der Januar-Gesamtumsatz ist um {0} € gesunken'.format(sheet3['B8'].value - sheet1['B8'].value))
if sheet1['B8'].value == sheet3['B8'].value:
print('Der Januar-Gesamtumsatz ist gleich geblieben')
Zur besseren Lesbarkeit des Codes nennen wir das Worksheet-Objekt für das erste Tabellenblatt nun sheet1 statt wie bisher sheet und den daraus abgeleiteten Zellenbereich cell_range1 statt wie bisher cell_range. Entsprechend lauten die Variablen für das Worksheet-Objekt des dritten Tabellenblatts sheet3 und für den entsprechenden Zellenbereich cell_range3. Die Ausgabe des Listings sieht so aus:
Summe der Umsätze aller Produkte im Januar 2021: 86000
Summe der Umsätze aller Produkte im Januar 2020: 83850
Der Januar-Gesamtumsatz ist um 2150 € gestiegen
Wenn Sie das Programm ausführen und danach Demo.xlsx in Excel öffnen, werden Sie allerdings feststellen, dass die Zellen A8 und B8 der Tabellenblätter 1. Halbjahr 2021 und 1. Halbjahr 2020 nach wie vor leer sind. Python hält die während der Programmausführung „geschriebenen“ Excel-Daten nämlich nur so lange vor, bis das Programm beendet ist. Mit der save()-Methode des Workbook-Objekts können Sie sie aber dauerhaft in der Excel-Arbeitsmappe speichern:
wb.save('Demo.xlsx')
Beachten Sie, dass der save()-Methode des Workbook-Objekts beim Aufruf ebenfalls – genauso wie bei der openpyxl.load_workbook()-Funktion – der Name der Excel-Datei zu übergeben ist.










