
10. Mai 2022
Lesedauer 31 Min.
Erntehelfer
Web Scraping und Data Extraction mit Apify, Teil 1
Die auf Web Scraping spezialisierte Cloud-Plattform Apify ermöglicht das massenhafte automatisierte Auslesen von Daten aus Websites.

Daten sind unerlässlich für den IT-Alltag und die darauf aufbauenden Anwendungsszenarien. Allerdings stehen nicht immer Schnittstellen zur Verfügung, über die sich wertvolle Daten abfragen lassen. Das ist häufig bei Websites der Fall, die interessante Informationen bereitstellen. Dort ist selten eine Schnittstelle vorhanden, einfach weil es nie vorgesehen war. Andererseits ist eine Website aber auch eine gute Schnittstelle an sich, denn die Informationen wurden bereits zum Client übertragen, um sie dort anzuzeigen. Hier setzt das Web Scraping an, das genau dafür vorgesehen ist, Daten von Websites auszulesen und sie abzuspeichern. In der Regel massenhaft, da selten nur kleine Teile einer Website notwendig sind, sondern meist viele Daten von zahlreichen Seiten.Web Scraping ist der Kern dieser zweiteiligen Artikelserie, die einen speziellen Fokus auf die Cloud-Plattform Apify [1] richtet. Damit lassen sich sogenannte Aktoren starten, die laufend Daten auslesen und in der Cloud abspeichern. Alternativ bietet Apify SDKs an, wenn diese Aktoren lokal ausgeführt werden sollen. Welche Möglichkeiten und Features von Apify das Web Scraping komfortabler machen, beleuchtet dieser erste Teil der Serie. Ein Folgeartikel wird dann ein Web-Scraping-Beispiel vorstellen, das erfolgreich in einem Forschungskontext zum Einsatz kam.
Was ist Web Scraping?
Web Scraping, auch als Web Harvesting oder Screen Scraping bezeichnet, ist eine Technik des Crawling. Suchmaschinen wie Google nutzen die sogenannten Crawler schon seit Anbeginn der Web-Zeit. Ein Crawler ist eine besondere Art von Bot, der Webseiten nach Stichwörtern durchsucht, diese kategorisiert und automatisch der Link-Struktur folgt. Beim Web Scraping geht es über Schlüsselwörter und Kategorien hinaus um alle Arten von Informationen, die aus dem Web geschürft werden – daher auch der Name. Die Daten werden extrahiert und abgespeichert, um sie bereinigen, aggregieren und letztendlich weiterverarbeiten zu können.Web Scraping lässt sich gut mit einem Copy-and-paste-Prozess beschreiben, nur eben automatisiert und für viele Daten. Denn der manuelle Prozess ist mitunter sehr aufwendig. Automatisiert geht das zwar schneller und besser, eine solche Software beziehungsweise ein Algorithmus kann aber, je nach Struktur und Varianz der auszulesenden Websites, in der Entwicklung ebenfalls viel Aufwand erfordern.Die Einsatzgebiete des Web Scraping sind zahlreich. Das massenhafte Auslesen von Kontaktdaten wie E-Mail-Adressen ist sicherlich ein häufiger Anwendungsfall und nicht nur für Spammer interessant. Oder Informationen von Mitbewerbern im Markt auszulesen, um die Struktur konkurrierender Angebote zu analysieren. Google ist ebenfalls ein gutes Beispiel für das Web Scraping, denn es werden nicht nur Informationen wie Schlüsselwörter extrahiert, sondern auch weitergehende, wie etwa Wetterinformationen oder Preise von Hotels und Flügen, die dann bei Suchergebnissen mit eingeblendet werden. Das geht über eine reine Informationsanalyse von Schlüsselwörtern für eine Suche hinaus.Die technische Dimension von Web Scraping
Das Ziel des Web Scraping ist es, Texte aus Webseiten zu extrahieren. Wenn es um Bilder geht, heißt der Prozess passenderweise Image Scraping. Technisch gibt es sehr viele Möglichkeiten, dieses Extrahieren von Informationen umzusetzen. Wenn die Struktur der Datenquelle kompliziert ist, lassen sich Parser einsetzen. Dadurch wird die Struktur einer Webseite in eine neue überführt, zum Beispiel durch eine Inselgrammatik [2]. Parser-Generatoren wie ANTLR [3] [4] lassen sich dafür gut nutzen, um das Document Object Model (DOM) der Seite zu verarbeiten. Das muss sich vom Aufwand her aber lohnen. Andere Möglichkeiten sind Bots, die mit der Struktur einer Webseite implizit umgehen können und schlüsselwortgetrieben die Daten auslesen. Wer die Low-Level-Variante bevorzugt, kann auf den Text einer Seite in Form einer Zeichenkette zurückgreifen und mit Kommandozeilen-Tools beziehungsweise regulären Ausdrücken darin suchen.Plattformen wie Apify bieten eine Kombination dieser Möglichkeiten an. Spezielle Skripte nehmen dem Nutzer viel vom technischen Aufwand ab, um beispielsweise den Inhalt einer Webseite zu erfassen, einem weiterführenden Link zu folgen und dergleichen, und sie bieten eine Schnittstelle zur Implementierung der eigenen Logik an. Sprich, welche Daten tatsächlich ausgelesen werden sollen und so weiter. Zudem sind Datenbanken verfügbar, die dann die erfassten Informationen direkt aufnehmen. Das Implementieren der Logik, also die Entscheidung, welche Daten tatsächlich von Relevanz sind, kann einem aber auch eine Plattform wie Apify nicht vollständig abnehmen.Um Web Scraping aus der Sicht des Website-Betreibers zu verhindern, bieten sich zahlreiche Möglichkeiten an. So weist eine robots.txt-Datei auf dem Webspace Suchmaschinen-Bots an, die Seite nicht zu erfassen, und die großen Betreiber halten sich meist daran. IP-Adressen von Bots können geblockt werden, und sensible Informationen wie Kontaktdaten lassen sich als Bild hinterlegen. Das macht es zumindest etwas schwieriger, ebenso wie mit JavaScript unlesbar gestaltete E-Mail-Adressen. Kein wirklicher Schutz also, sondern nur diverse Hürden. Zudem gibt es zahlreiche kostenpflichtige Anbieter von Anti-Bot-Services, die eine Firewall einrichten können, um eine weitere Barriere zu installieren.Was ist Apify?
Hinter dem Namen Apify verbirgt sich eine Plattform zur Automatisierung von Webseiten. Erst einmal genau so allgemein, wie sich dieser Satz liest. Diese Automatisierung erstreckt sich auf drei Bereiche: zunächst das Web Scraping, weil jede Art von textbasierten Informationen aus einer Webseite extrahierbar ist – ganz genau so, als wäre der Webbrowser selbst am Werk. Der zweite Bereich ist die Web-Automatisierung, indem manuelle Prozesse auf einer Webseite durch Apify automatisch ablaufen können, um so Zeit und Aufwand zu sparen und Fehler zu minimieren. Gerade ständig wiederkehrende Aufgaben, die repetitiv und damit vielleicht langweilig sind, kann ein Roboter besser erledigen. Der dritte Bereich hat mit der Web-Integration zu tun. Über Apify lassen sich automatisiert Webseiten und die sich darauf beziehenden Anwendungen miteinander verknüpfen, um beispielsweise automatisiert Daten zwischen diesen auszutauschen.Anhand dieser drei Tätigkeitsbereiche wird deutlich, was das Ziel von Apify ist: eine Webseite in ein API zu verwandeln, immer mit dem Ziel, Daten aus den Seiten zu gewinnen – ob für das Crawling, die Automatisierung von Prozessen oder die Integration von verschiedenen Diensten.Dadurch hat Apify vielfältiges Potenzial, in einem Unternehmen eingesetzt zu werden und dieses zu unterstützen. Typische Anwendungsbereiche sind die Marktanalyse, die Automatisierung, Datenvergleiche zum Beispiel bei Preisen, das Auffinden neuer Kunden, das Anlegen großer Datensammlungen, etwa für das Machine Learning, und die Produktentwicklung durch die Verknüpfung bestehender Daten.Apify bietet dafür verschiedene Produkte an. Diese tragen die Namen Actors, Proxy, Storage und Apify SDK. Alle vier werden im weiteren Verlauf dieses Artikels vorgestellt und näher beschrieben.Anforderungen an moderne Scraping-Lösungen
Die Anforderungen an Scraping-Lösungen sind eng gekoppelt an die Features von Webseiten. Während es früher sehr einfach war, statische Webseiten mit statischem Content aus der HTML-Struktur auszulesen, ist das mit dem Aufkommen moderner Webseiten, angetrieben durch immer komplexer werdende Programmiersprachen, HTTP-Requests und dynamische Inhalte, nicht mehr so problemlos.Heutzutage muss ein guter Web Scraper daher zahlreiche Anwendungsfälle und Technologien abdecken. Eine komplexe Seiten-Navigation zum Beispiel, bei der Teile der gewünschten Gesamtinformation über mehrere Seiten verstreut sind – eine HTML-Seite ist schon lange keine geschlossene Informationseinheit mehr. Moderne Web-Apps basieren zudem auf JavaScript beziehungsweise TypeScript und sind hochdynamisch. Bei Anfragen muss auf Ajax-Requests oder Ähnliches gewartet werden, um Informationen erfassen zu können. Zusätzlich werden die Interaktionen auf modernen Webseiten immer komplexer. Daten werden auf mehrere Seiten aufgeteilt, Stichwort „Pagination“, oder sie werden beim Herunterscrollen nachgeladen – diese und ähnliche Konstrukte sind auf immer mehr Webseiten anzutreffen. Das alles müssen moderne Web Scraper handhaben können, wenn sie zuverlässig Informationen von Seiten auslesen wollen.Unterschiede in den Apify-Produkten – Plattform versus SDK
Dass Apify verschiedene Produkte anbietet, geht auf die Unterscheidung zwischen der Apify-Plattform und dem SDK zurück. Zum einen werden die sogenannten Actors [5] angeboten. Das ist eine einzelne Einheit, genauer: ein Serverless-Cloud-Programm, das implementiert wird und auf der Apify-Plattform läuft. Ein Actor kann eine beliebige Aufgabe automatisiert erfüllen, etwa eine E-Mail verschicken oder das Data Crawling einer Webseite übernehmen. Ein solches Programm lässt sich manuell über die Apify-Webseite starten, über das API oder automatisiert durch einen Scheduler. Die Aktoren werden weiter unten im Detail vorgestellt.Ein weiteres Produkt von Apify ist der universelle Proxy [6]. Dieser wird allen Anfragen vorgeschaltet, um den wahren Standort zum Beispiel eines Actors zu verbergen. Zur Auswahl stehen verschiedene Datacenter beziehungsweise lokale IP-Adressen, die zudem durchgewechselt werden können. Das erlaubt es, Webseiten anzufragen, die ansonsten keine Antwort mit Daten liefern würden.Die Apify-Plattform bietet zudem einen eigenen Speicher [7] an. Auf das Web Scraping spezialisierte Datenspeicher erfassen die Daten von Scraping-Jobs, um die Resultate abzuspeichern. Diese Daten lassen sich in Formaten wie CSV, Excel oder JSON exportieren. Auf diese Weise lassen sich zahlreiche Scraping-Jobs durchführen, ohne sich Sorgen machen zu müssen, was mit den erfassten Daten passiert.Zu guter Letzt existiert noch das Apify SDK [8]. Dieses SDK ist zudem die Basis der Actors auf der Apify-Plattform. Wer das Cloud-Angebot von Apify nicht nutzen möchte, kann über das SDK einen Actor lokal laufen lassen. Erstellt wurde das SDK für das JavaScript-Ökosystem, und es basiert auf Technologien wie etwa Playwright und Puppeteer. Mit dem SDK lassen sich beliebige Aktoren lokal ausführen, um zum Beispiel Crawling- oder Automatisierungs-Prozesse durchzuführen und die Daten lokal zu speichern. Das SDK ist daher eine gute Möglichkeit, die Power von Apify auch ohne die Plattform zu nutzen.Die rechtliche Situation
Ist Web Scraping legal oder nicht? Und wenn es legal ist, wofür dürfen die Daten genutzt werden? Oder gibt es dabei auch Unterschiede? Die Antwort ist ein klares „Jein“. Web Scraping ist nicht immer erlaubt, aber auch nicht per se verboten. Beim Scraping sind die Urheberrechte einer Webseite zu berücksichtigen. Das Scraping kann für einen Anbieter negative Konsequenzen haben. Zum Beispiel für einen Webshop oder für eine Fluggesellschaft. Nicht selten werden deshalb Vergleichsportale für dieses Datensammeln und Aggregieren verklagt. Das OLG Frankfurt [26] hat bereits 2009 entschieden, dass die Anbieter von Webseiten das Sammeln von Daten prinzipiell erlauben müssen, weil diese Informationen schließlich frei zugänglich seien. Trotzdem ist es den Anbietern von Inhalten erlaubt, technische Maßnahmen zu treffen, um das Web Scraping zu erschweren oder gar zu verhindern.
Verschiedene Arten von Crawlern
Unterschieden werden moderne Web-Crawler nach den an sie gestellten Anforderungen. Suchmaschinen-Crawler etwa, auch Searchbots genannt, durchsuchen das Web nach indexierbaren Inhalten, Stichwort Indexierbarkeit, um die Suchmaschinen-Datenbanken mit Informationen zu füllen. Sehr bekannte Vertreter sind GoogleBot (Google), Bingbot (Bing), Slurpbot (Yahoo), Facebot (Facebook) und Alexa Crawler (Amazon). Daneben existieren die häufig als Personal-Website-Crawler beschriebenen Programme und Skripte, die mit recht einfachen technischen Mitteln Informationen von einzelnen Webseiten abfragen. Kommerzielle Crawler dagegen bieten deutlich mehr Funktionen an, entweder als käufliche Tools oder Plattformen. Zu Letzteren gehören zudem die Cloud-Crawler, zu denen auch Apify zählt. Desktop-Crawler laufen dagegen in der Regel auf kleineren, lokalen Maschinen und sind daher meist begrenzt einsatzfähig, erfassen also beispielsweise nur eine kleine Menge an Daten.Generell lohnt sich zudem die Unterscheidung zwischen Web-Crawlern und Scrapern. Sie werden oft gleichgesetzt, sind aber nicht die gleiche Art von Bot. Erstere suchen primär nach Webinhalten, um diese zum Beispiel in einem Index abzulegen und zu bewerten. Ein Scraper hingegen hat die primäre Aufgabe, Daten von Websites über das Web Scraping zu erfassen und zu extrahieren, damit diese Daten anschließend weiterverarbeitet werden können.Im weiteren Verlauf des Artikels dreht sich alles um lokale und Cloud-Crawler mit Apify, da diese Plattform, in Kombination mit dem SDK, beide Szenarien ermöglicht.Das Konzept der Aktoren
Bevor wir zu den Aktoren von Apify kommen, ein kurzer Schwenk hin zu Bots. Es gibt verschiedene Arten dieser digitalen Werkzeuge, die auf unterschiedliche Anwendungsfälle ausgerichtet sind. Bots können bei Kommunikationsdiensten wie WhatsApp, Twitter oder Facebook unterstützen, eigenständig Daten sammeln, Schnittstellen zu anderen Diensten bereitstellen und Spielfunktionen übernehmen, zum Beispiel beim Schach. Im Kontext dieses Artikels ist das eigenständige Sammeln von Daten der passendste Anwendungsfall.Die vereinfachte Struktur eines Bots lässt sich an drei Hauptkomponenten festmachen: Das sind die Anwendungslogik (Workflow-Logik), eine Datenbank für die Daten und bei Bedarf ein weiteres API, um darüber auf Informationen und Daten zugreifen zu können, die vom Bot selbst genutzt werden oder über die ein solcher Bot gesteuert wird.Diese vereinfachte Struktur ähnelt sehr dem Konzept der bereits angesprochenen Aktoren oder Actors. Ein Actor ist ein Stück Software, das zum Beispiel auf der Apify-Plattform in der Cloud läuft, dort Daten sammelt und diese in den von Apify zur Verfügung gestellten Datenbanken abspeichert. Aktoren sind damit ein Kernkonzept von Apify.Technisch gesehen ist ein Actor ein Microservice, ein Serverless-Cloud-Programm, das einen Web-Automatisierungs- oder Datenextraktionsauftrag ausführen kann. Er nimmt eine Eingabekonfiguration entgegen, führt den Auftrag aus und speichert die Ergebnisse. Die Implementierung eines Actors bestimmt dabei, was die konkrete Aufgabe ist. Vom Sammeln einfacher Daten von Websites über das Ausfüllen von Formularen oder das Verarbeiten großer Datenmengen ist praktisch alles möglich. Ein Actor lässt sich über die Apify-Konsole [9] nutzen, über das API [10] oder den Scheduler [11]. Zudem ist die Integration [12] in andere Anwendungen möglich oder das Teilen eines Actors mit anderen Apify-Plattform-Nutzern.Bei Aktoren wird zwischen öffentlichen, privaten und bezahlten Aktoren unterschieden. Private Aktoren sind die einfachste Variante. Sie sind eben nicht öffentlich und werden selbst implementiert und genutzt. Da niemand anderes sie einsetzen kann, ist der Aufwand für Wartung und Pflege nicht ganz so hoch und fällt nur dann an, wenn wir etwas an unseren Aktoren ändern möchten. Bei öffentlichen Aktoren ist das anders. Wie in einem Open-Source-Projekt können andere diese Aktoren nutzen und finden unter Umständen Fehler, haben Änderungswünsche und dergleichen. Insbesondere gilt das, wenn ein solcher Actor im Apify Store [13] zur Verfügung steht und eine gewisse Aufmerksamkeit bekommt. Das wird erst recht wichtig, wenn es sich um einen kostenpflichtigen Actor handelt, für den andere Geld ausgeben.Ein Actor teilt sich in Tasks und Runs auf. Ein Task erlaubt es, wiederkehrende Konfigurationen für einen Actor anzulegen. Damit lassen sich Aktoren in unterschiedlichen Szenarien nutzen und diese Anwendungsfälle immer wieder starten, da die Konfigurationen in einem Task die wichtigen Informationen und Daten enthalten. Beispielsweise kann ein Web Scraper in Form eines Actors zunächst die neuesten Informationen von dotnetpro.de abgreifen. Derselbe Actor ist dann mit einem weiteren Task in der Lage, die Daten der News von heise.de zu erfassen und zu speichern. In beiden Fällen kommt ein Actor für das Web Scraping zum Einsatz, doch der Task gibt vor, was konkret ausgeführt wird. Die Konfigurationen eines Tasks lassen sich per Apify-Konsole, API oder Scheduler nutzen. Alle erstellten Tasks finden Sie übersichtlich in der Task-Übersicht der Apify-Plattform [14].Wenn klar ist, was ein Task ist, dann wird auch die Bedeutung eines Runs schnell deutlich. Damit ist ein aktiver Lauf eines Tasks gemeint. Diese Durchläufe [15] werden ebenfalls übersichtlich auf der Apify-Plattform dargestellt. Dort können sie erneut gestartet oder auch abgebrochen werden, wenn es sich um sehr lange laufende Tasks handelt. Letzteres ist durchaus nicht unrealistisch, je nachdem, wie viele Websites beziehungsweise wie viele Daten in einem Scraping-Lauf verarbeitet werden sollen. Ein Run benötigt Eingabedaten in Form einer Konfiguration und verbraucht Speicher und CPU-Zeit.Arbeiten mit Aktoren auf der Apify-Plattform
Um mit Aktoren auf der Apify-Plattform zu arbeiten, gibt es zwei Wege. Wir können einen kompletten Actor selbst implementieren und dann auf der Plattform nutzen beziehungsweise dort zur Verfügung stellen. Was dafür zu beachten ist, zeigt der nächste Abschnitt. Der zweite Weg ist, einen vorgefertigten Aktor zu nutzen und diesen in einem neuen Task einzubetten, um so unseren eigenen Anwendungsfall zu realisieren. Darum geht es im weiteren Verlauf dieses Abschnitts.Dazu nutzen wir einen Actor aus dem öffentlichen Marktplatz von Apify. In der Übersicht der Tasks genügt ein Klick auf Create New Task, um direkt zur Auswahl der vorhandenen Aktoren geleitet zu werden (siehe Bild 1). Dort gibt es eine große Bandbreite an vorgefertigten Aktoren, die verschiedenste Datenquellen abgreifen können. Für ein erstes Beispiel ist der Web Scraper [16] genannte Aktor gut zu gebrauchen. Der Code zum Projekt steht auf GitHub [17] zur Verfügung.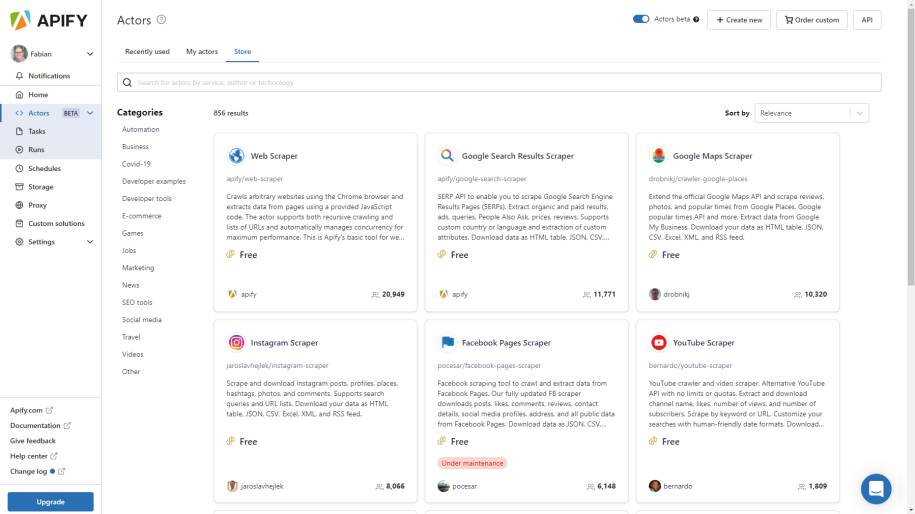
Auswahl vorhandener Aktorenbeim Anlegen eines neuen Tasks(Bild 1)
Autor
Dieser Web Scraper hat einige Vorteile. Zunächst ist es ein generischer, einfach zu bedienender Actor zum Crawlen verschiedenster Webseiten und zum Extrahieren strukturierter Daten aus ihnen. Letzteres geschieht über einige Zeilen JavaScript-Code. Der Actor lädt Webseiten in den Chromium-Browser und rendert dynamische Inhalte. Der Actor lässt sich entweder manuell über eine Benutzeroberfläche konfigurieren und ausführen oder per Programm über das API. Die extrahierten Daten werden in einem Datensatz gespeichert, aus dem sie in verschiedene Formate wie JSON, XML oder CSV exportiert werden können.Um den Web Scraper zum Laufen zu bekommen, ist im einfachsten Fall nur eine Liste von Websites erforderlich und der Teil der JavaScript-Implementierung, der angibt, welche Daten wie aus den Seiten extrahiert werden sollen. Die Liste von URLs wird genau so übergeben: als Liste. Für die Extraktion der Daten ist eine sogenannte Page Function zu implementieren. Diese Funktion kümmert sich darum, aus einem übergebenen Context-Objekt die Daten zu extrahieren und zurückzuliefern. Diese zurückgegebenen Daten werden automatisch in einer von Apify zur Verfügung gestellten Datenbank gespeichert.Die allgemeinen Limitierungen des Web-Scraper-Actors werden weiter unten im Abschnitt zu den Eigenschaften und Einschränkungen von Aktoren beschrieben. Beim Anlegen eines neuen Tasks mit dem Web Scraper sind einige wichtige Informationen anzugeben. Das fällt unter die sogenannte Eingabe-Konfiguration. Damit sind wichtige Stellschrauben eines Actors gemeint, aber auch banale und gleichzeitig wichtige Informationen wie zum Beispiel die Liste mit URLs, mit denen das Web Scraping gestartet werden soll.Bild 2 zeigt dazu den Dialog der Eingaben und Optionen eines neuen Tasks, in dem diese Einstellungen vorgenommen werden müssen. Wichtige Optionen sind beispielsweise der Run Mode, um anzugeben, ob der Actor im Entwickler- oder Produktiv-Modus läuft. Im ersteren Fall werden zum Beispiel Timeouts ignoriert, und der Scraping-Prozess lässt sich mit den DevTools von Chrome kontrollieren.
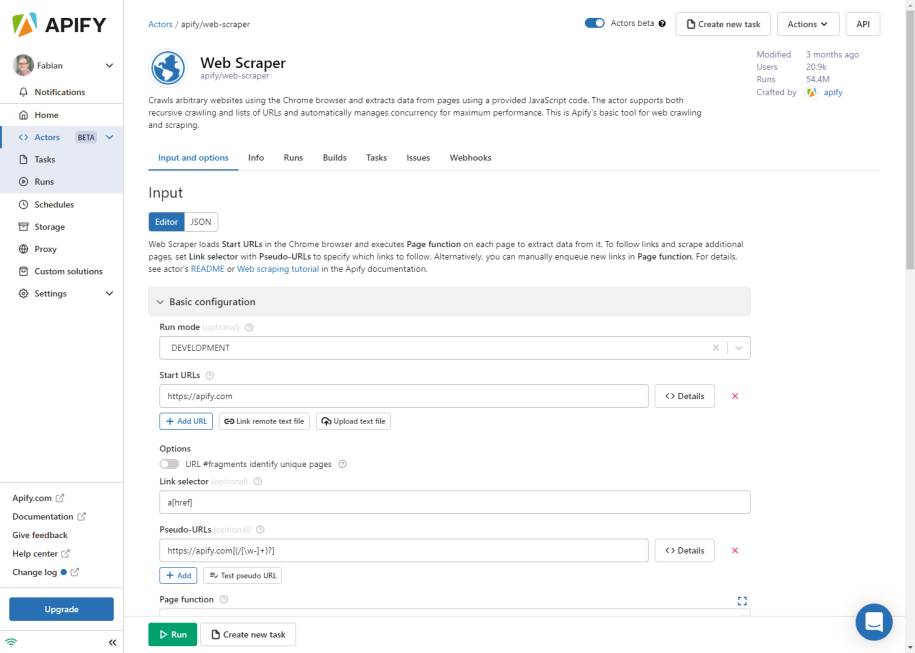
Eingabe und Optionenzum Web Scraper(Bild 2)
Autor
Des Weiteren ist der Start-URL sehr wichtig. Hier kann ein URL inklusive HTTP-Methode wie GET oder POST, Payload, Header und Benutzerdaten angegeben werden. Zusätzlich sind die Angaben zum Link-Selektor und den Pseudo-URLs wichtig. Ersterer gibt einen CSS-Selektor an, um Links auf der HTML-Seite zu identifizieren, denen der Web Scraper folgt, indem die gefundenen URLs automatisch zur Request-Queue hinzugefügt werden.Für das Filtern dieser URLs ist die Einstellung des Pseudo-URL zuständig. Mit dieser Einstellung lässt sich definieren, welche URLs über die Request-Queue weiterverarbeitet werden sollen. Die folgende Einstellung
http://www.example.com/blogposts/[(\w|-)*]
führt etwa dazu, dass von der Website mit der Unterseite zu den Blogposts alle URLs nach dem Schema blogposts/post-1, blogposts/post-2 und so weiter verarbeitet werden. Andere Unterseiten aber nicht, diese werden herausgefiltert. Darüber lässt sich komfortabel definieren, welchen URLs der Web Scraper bei seiner Suche folgen soll und welchen nicht.Sehr wichtig ist zudem die bereits kurz angesprochene Page Function. In Listing 1 ist dazu ein Beispiel enthalten. Die Implementierung stammt aus dem Standard-Web-Scraper-Actor. Zum Einsatz kommt jQuery, um den Inhalt der Seite zu zerlegen – in diesem Fall ausschließlich für den Titel der Websites. Die Information wird auf der Konsole ausgegeben und zurückgeliefert, damit sie in der Datenbank landet. Als Beispiel wird zudem gezeigt, wie ein URL manuell zum Kontext hinzugefügt wird. Auf diese Weise lassen sich URLs, zum Beispiel auf Basis von anderen Daten und Entscheidungen, durch den Scraper verarbeiten, ohne dass diese spezifischen URLs im HTML-Markup der Seite gefunden werden müssen. Optional ist die Angabe von sogenannten Pre- und Post-Navigation-Hooks. Durch diese lassen sich asynchrone Aktionen vor oder nach einer Navigation, also dem Folgen eines URL, ausführen. Das ist daher eine gute Stelle, um Cookies oder andere seitenspezifische Daten zu setzen. Listing 2 zeigt die beispielhafte Struktur dieser beiden Hooks.
Listing 1: Page-Function-Beispiel-Implementierung
async function pageFunction(context) {
const $ = context.jQuery;
const pageTitle = $('title').first().text();
context.log.info(`URL: ${context.request.url},
TITLE: ${pageTitle}`);
context.enqueueRequest({
url: 'https://www.dotnetpro.de' });
return {
url: context.request.url,
pageTitle
};
} Listing 2: Pre- und Post-Navigation-Hook-Struktur
[
async (crawlingContext, gotoOptions) => {
// ...
},
]
[
async (crawlingContext) => {
// ...
},
]
Damit das jQuery-Beispiel aus der Page Function funktioniert, muss die Option zum Injizieren dieser Abhängigkeit aktiviert sein. Des Weiteren kann die Apify-Plattform automatisiert Underscore.js einbinden, wenn die entsprechende Option aktiviert ist. Darüber hinaus bietet Apify es an, verschiedene Proxies zu nutzen, zum Beispiel in einer automatischen Rotation, benutzerdefiniert oder aus einer vorher erstellten Selektion von Proxies. Auch ein Maskieren des Browsers ist möglich. Bei den Optionen zur Performance und zum Limit lässt sich definieren, ob Mediadaten und CSS-Dateien heruntergeladen werden sollen, wie viele Seiten maximal zurückgeliefert werden dürfen und wie lange es beispielsweise dauern darf, bis eine Seite geladen wurde. Bei den erweiterten Einstellungen lässt sich angeben, ob ein Breakpoint eingefügt werden soll, beispielsweise nach jeder Navigation, ob das Logging aktiv ist und in welcher Datenbank die Daten gespeichert werden sollen. Ohne diese letztgenannte Option wird die Standard-Datenbank genutzt.Zu guter Letzt lässt sich definieren, welche Version des Actors zum Einsatz kommen soll und wie hoch der Timeout sowie der Speicher sein dürfen. Mehr Ressourcen können einen Actor teils deutlich beschleunigen, erhöhen aber auch die laufenden Kosten.Danach ist zunächst alles konfiguriert und wir können einen Testlauf starten. Im Folgenden wird dazu eine Website der TU Dortmund genutzt, konkret der Fakultät Informatik, und dort die Übersicht der Personen ebendieser Fakultät. Der Start-URL ist der folgende:
https://www.cs.tu-dortmund.de/nps/de/Home/Personen/
index.html
Als Pseudo-URL wird der folgende genutzt:
https://www.cs.tu-dortmund.de/nps/de/Home/Personen/
[(/|\w|-|\.)*]
In Bild 3 ist ein Test des Pseudo-URL auf Basis des Start-URL zu sehen. Ein nettes und hilfreiches Feature von Apify, das direkt in der Weboberfläche bei der Konfiguration zur Verfügung steht. Der Start-URL und der Pseudo-URL passen auf die Website-Struktur für die Personen der Fakultät Informatik. Beispielsweise die Folgenden:
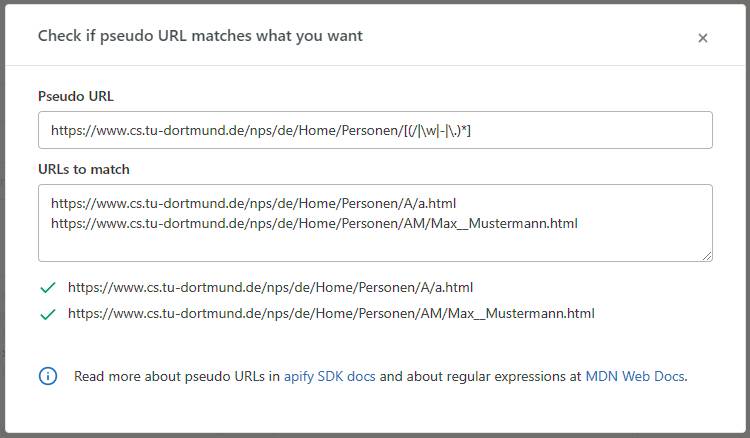
Testsdes Pseudo-URL(Bild 3)
Autor
https://www.cs.tu-dortmund.de/nps/de/Home/Personen/
A/a.html
https://www.cs.tu-dortmund.de/nps/de/Home/Personen/
AM/Max__Mustermann.html
Damit ist ein erster Testlauf möglich, ohne konkrete Daten von den einzelnen Unterseiten zu sammeln – bis auf den Titel der Seite. Der reicht aber schon für einen ersten Debug-Durchlauf, denn der Titel enthält den Namen der Personen. Bild 4 zeigt den Screenshot eines kompletten Durchlaufs.
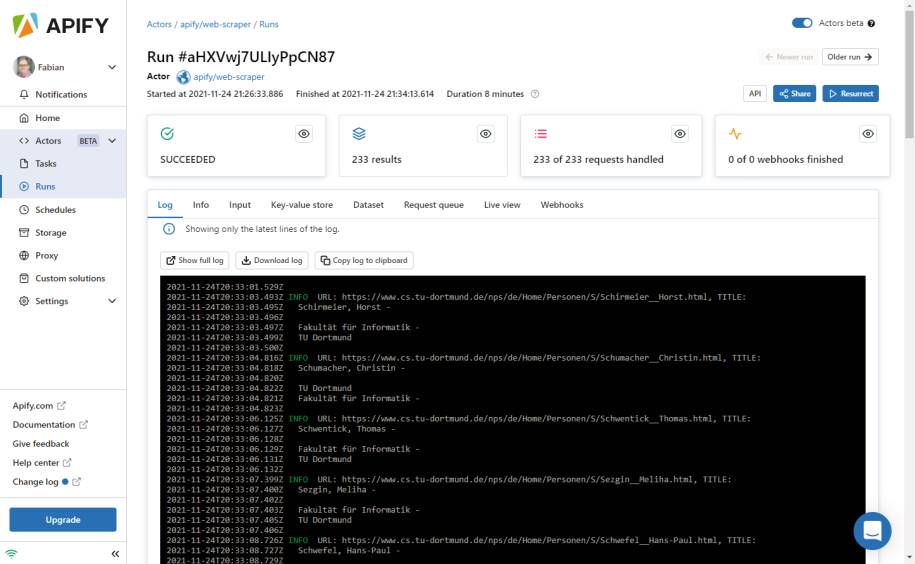
Testlaufzum Sammeln von Personendaten der Fakultät Informatik der TU Dortmund(Bild 4)
Autor
Für die 233 Requests der Personen-Unterseiten hat der Scraper mehr als acht Minuten gebraucht. Das ist langsam und liegt an mehreren Dingen. Zum Beispiel lief der Durchlauf im Debug-Modus. Zusätzlich handelt es sich um einen Apify-Testaccount mit sehr limitierten Ressourcen für einen Actor. Die Durchläufe werden alle ordentlich gespeichert und übersichtlich dargestellt, wie in Bild 5 zu sehen ist. Diese Durchläufe lassen sich somit nachträglich anschauen, was auch für die gesammelten Daten gilt.
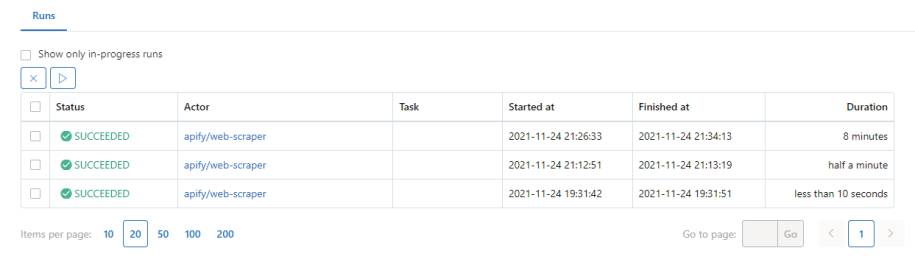
Übersichtüber die Durchläufe des Web Scraper(Bild 5)
Autor
Für den beschriebenen Durchlauf aller Personen der Fakultät Informatik sind 233 Elemente angefallen, weil einfach nur der Titel erfasst wurde. Die Daten werden in einem sogenannten Dataset gespeichert und nutzen für dieses Beispiel nicht ganz 110 Kilobyte. In Bild 6 ist ein Ausschnitt dieser Daten dargestellt, visualisiert als HTML-Tabelle. Zu sehen ist auch der Beispiel-URL, der im Code explizit als Test gesetzt wird. Für zukünftige Durchläufe ist es nicht verkehrt, diesen manuellen Testeintrag zu entfernen. Weitere Datenformate sind JSON, CSV, Excel, XML und RSS. Die gewonnenen Daten lassen sich direkt online einsehen, exportieren oder über einen Link teilen, da die Daten in der Apify-Plattform zur Verfügung stehen.
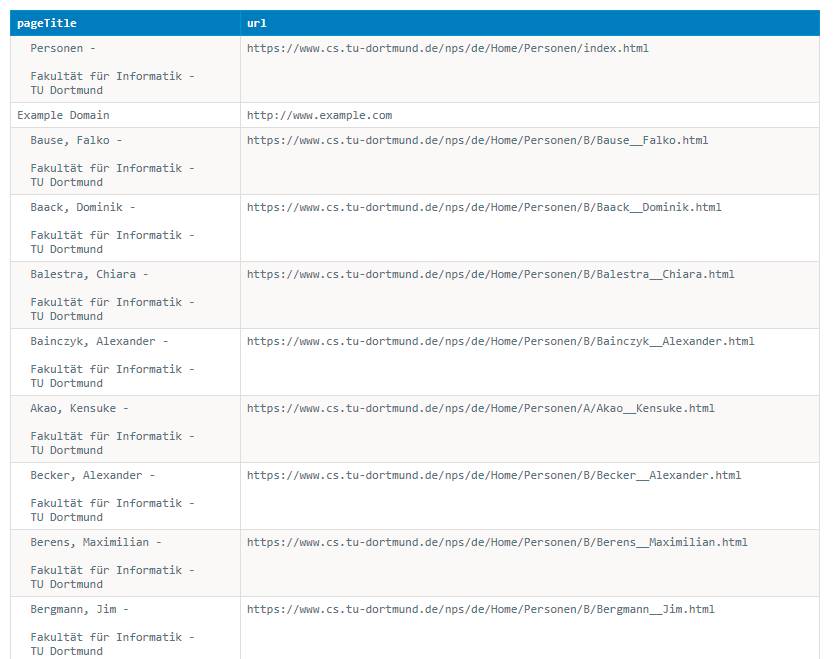
Ausschnitt aus der Datentabelledes Testdurchlaufs(Bild 6)
Autor
Eine eigene Page Function
Das vorangegangene Beispiel hat sehr gut gezeigt, wie mit wenig Konfigurationsaufwand ein Scraper in Form eines Actors erstellt werden kann, um damit Daten von Websites abzugreifen. Die standardmäßig vorhandene Page Function ist allerdings beschränkt, sie gibt in diesem Fall nur den Titel der einzelnen Seiten zurück. In der Regel sind andere Daten von Interesse, in diesem Fall der Vor- und Nachname getrennt, wenn es möglich ist, die E-Mail-Adresse, die Telefonnummer und die Adresse sowie der Raum, falls diese Daten vorhanden sind. Das bedeutet, dass eine eigene Page Function implementiert werden muss, um der speziellen Struktur der Unterseiten Rechnung zu tragen.Daran wird auch deutlich, dass der Page Function eine besondere Rolle zukommt. Je generischer das Web Scraping ablaufen soll und je allgemeiner ein Actor einsetzbar sein muss, desto komplexer wird die Page Function, da dort die vielen unterschiedlichen Situationen, Szenarien und Anwendungsfälle berücksichtigt werden müssen. Wird nur eine Seite verarbeitet oder ist die Struktur der einzelnen Unterseiten identisch bis sehr ähnlich, dann sinkt der Aufwand teils enorm.Die Page Function kann aber noch mehr. Sie enthält eine JavaScript-Funktion, die im Kontext jeder im Chromium-Browser geladenen Seite ausgeführt wird. Der Zweck dieser Funktion ist es nicht nur, Daten aus der Webseite zu extrahieren, sondern auch, das DOM durch Anklicken von Elementen zu manipulieren, neue URLs zur Anfragewarteschlange hinzuzufügen beziehungsweise den Betrieb des Web-Scraper-Actors anderweitig zu steuern. Die Funktion akzeptiert ein einziges Argument mit dem aktuellen Kontext. Da die Funktion im Kontext der Webseite ausgeführt wird, kann sie auf das DOM zugreifen, beispielsweise über die globalen Variablen window oder document. Das Context-Objekt besitzt verschiedene Eigenschaften, wie zum Beispiel ein Feld für benutzerdefinierte Daten, die über das API gesetzt werden, eine Funktion enqueueRequest, die wir bereits genutzt haben, und Möglichkeiten, Umgebungsvariablen auszulesen, die vom Apify SDK genutzt werden.Eine eigene Page Function umzusetzen kann eine langwierige Herausforderung sein – je nach Struktur der Website und den Daten, die von Interesse sind. Eine gute Möglichkeit ist es, die Datenextraktion bei der Implementierung zu testen. Das muss gar nicht über Apify sein, sondern kann in einem separaten System wie beispielsweise JSFiddle stattfinden. Bild 7 zeigt eine Beispielseite für eine Person – diese Daten sind von Interesse.
Die Website einer Personder Fakultät Informatik der TU Dortmund als Beispiel(Bild 7)
Autor
In Bild 8 ist die Testumgebung in JSFiddle [18] zu sehen. Dort ist etwas HTML-Markup nachgebildet, über die DevTools von Chrome einfach herauskopiert, inklusive etwas JavaScript-Code mit jQuery.
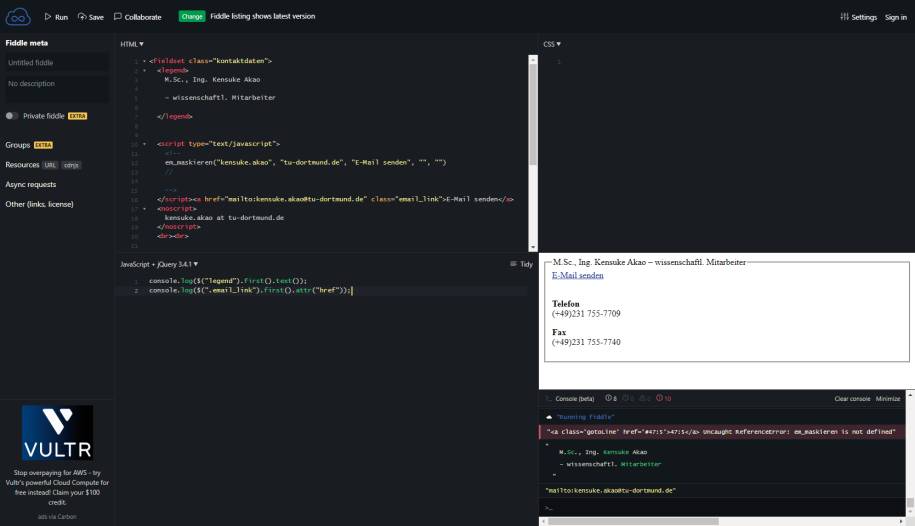
jQuery-Testsfür die spezifische Website in JSFiddle(Bild 8)
Autor
Der folgende jQuery-Code holt sich die persönlichen Informationen wie den (a) Vor- und Nachnamen und (b) die
E-Mail-Adresse:
E-Mail-Adresse:
(a) console.log($("legend").first().text());
(b) console.log($(".email_link").first().attr("href"));
Das ist ein typisches Beispiel für einen Web-Scraping-Task, denn hier fangen die Probleme beziehungsweise die Komplexität erst an. Beispielsweise sind der Vorname und der Nachname nicht einzeln auf der Seite ausgewiesen, von speziellen Markup-Elementen ganz zu schweigen. Die E-Mail-Adresse lässt sich einfacher auslesen. Dort ist dann zwar noch die mailto-Anweisung mit im Link enthalten, die aber recht einfach zu entfernen ist. Generell beginnt der Aufwand erst, wenn die Daten auf der Website lokalisiert wurden, da diese bereinigt werden müssen.Das Beispiel zeigt aber, wie Apify zum Einsatz kommen kann, um die Daten auf der Website zu lokalisieren und zu extrahieren. Die Aufbereitung lässt sich dann ebenfalls im Actor in der Page Function erledigen, oder in einem nachgelagerten Schritt, wenn das als bessere Option erscheint.Eine erste Version einer Page Function zum Auslesen von Daten der Mitarbeitenden der Fakultät Informatik der TU Dortmund zeigt Listing 3. Die Ergebnisübersicht aller 232 Einträge im Dataset demonstriert, dass diese recht einfache Page Function bereits zuverlässig einen erheblichen Teil der Daten sammelt.
Listing 3: Page Function für Teile der Personendaten der Informatik-Fakultät der TU Dortmund
async function pageFunction(context) {
const $ = context.jQuery;
const name = $("legend").first().text();
const email = $(".email_link").first().attr("href");
const phone =
$(".kontaktdaten").find("p").first().text();
const fax =
$(".kontaktdaten").find("p").eq(1).text();
const address =
$(".kontaktdaten").find("p").eq(2).text();
const room =
$(".kontaktdaten").find("p").eq(3).text();
context.log.info(`MAIL: ${email},
URL: ${context.request.url}`);
return {
name: name,
mail: email,
phone: phone,
fax: fax,
address: address,
room: room,
url: context.request.url
};
}
Je nach Aufbau der jeweiligen Unterseiten für die Mitarbeitenden werden die Telefon- und Faxnummer durcheinandergeworfen, die Raum-Angabe wird für die Adresse gehalten und umgekehrt, und es gibt weitere, kleinere Probleme. Die E-Mail-Adresse und der URL immerhin passen bereit sehr gut. Insgesamt sind die Daten noch zu bereinigen, wie bereits weiter oben erwähnt. Aber das ist nicht Fokus dieses Artikels, denn dieser Schritt ist beim Web Scraping in der Regel ohnehin notwendig, Apify hin oder her.
Einen eigenen Actor implementieren
Bisher wurde die Nutzung von Apify dahingehend beschrieben, vorgefertigte Aktoren zu nutzen und maximal die Page Function anzupassen, um die relevanten Daten von den Websites zu extrahieren. Das macht Apify bereits sehr mächtig, ist aber erst der Anfang. Wir können zudem einen eigenen Actor implementieren, um auf diese Weise noch genauer auf die Implementierung einzuwirken.Ein neues Projekt für einen Actor lässt sich auf verschiedene Arten anlegen. Zum Beispiel direkt über die Apify-Website, wie Bild 9 zeigt.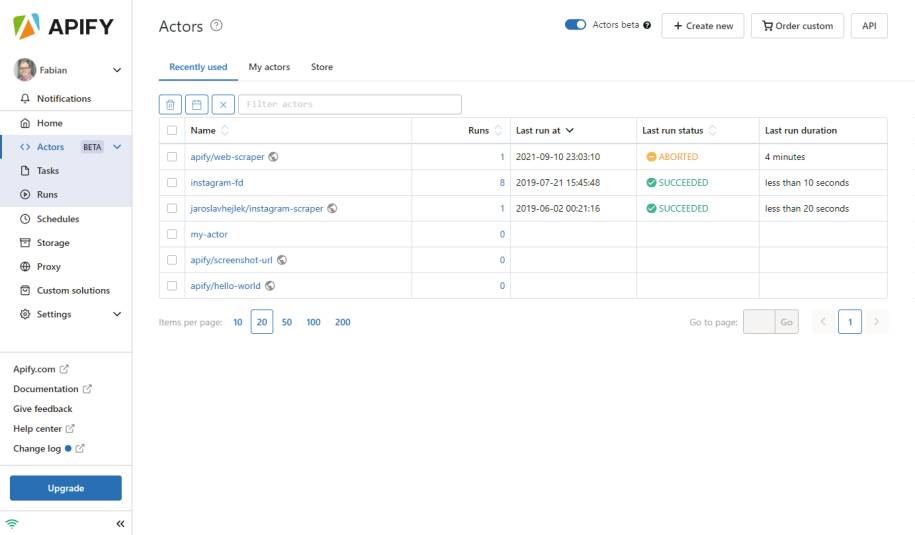
Übersicht der Aktorenund die Möglichkeit, einen neuen zu erstellen(Bild 9)
Autor
In der Actor-Übersicht reicht es dazu aus, auf Create new zu klicken, um einen Actor zu erstellen und die Projektstruktur anzuzeigen. Das Bild zeigt wichtige Elemente, die aus Code-Repositories wie Git beziehungsweise GitHub bekannt sind. Der Actor wird versioniert, es lassen sich Forks erstellen und Tags vergeben. Der Quelltext kann direkt im Browser editiert werden und auch der Build-Prozess, entweder mit dem Docker-Layer im Cache oder ohne, lässt sich ebenfalls direkt im Browser starten. Der Build-Prozess ähnelt in vieler Hinsicht einem Build auf einem lokalen System: Abhängigkeiten werden aufgelöst und das Docker-Image fertiggestellt. Ist der Build erfolgreich, lassen sich weitere Optionen festlegen. Die Input-Daten, die einem Actor übergeben werden können, haben wir bisher noch nicht besprochen. Das sind aber durchaus wichtige Informationen, die einem Run eines Actors mit auf den Weg gegeben werden können. In einem frisch erstellten Actor ist ein Eingabefeld als Test vorhanden. Die Konfiguration dazu stammt aus einer JSON-Datei, die das Input-Schema definiert. Listing 4 zeigt dazu ein sehr einfaches Beispiel. Bild 10 zeigt auch die Datei main.js. Dort startet die Verarbeitung durch Node.js.
Listing 4: Input-JSON-Schema für einen Actor
{
"title":
"Input schema for the apify_project actor.",
"type": "object",
"schemaVersion": 1,
"properties": {
"test": {
"title": "Test",
"type": "string",
"description":
"There is testing input field description.",
"editor": "textfield"
}
},
"required": []
} 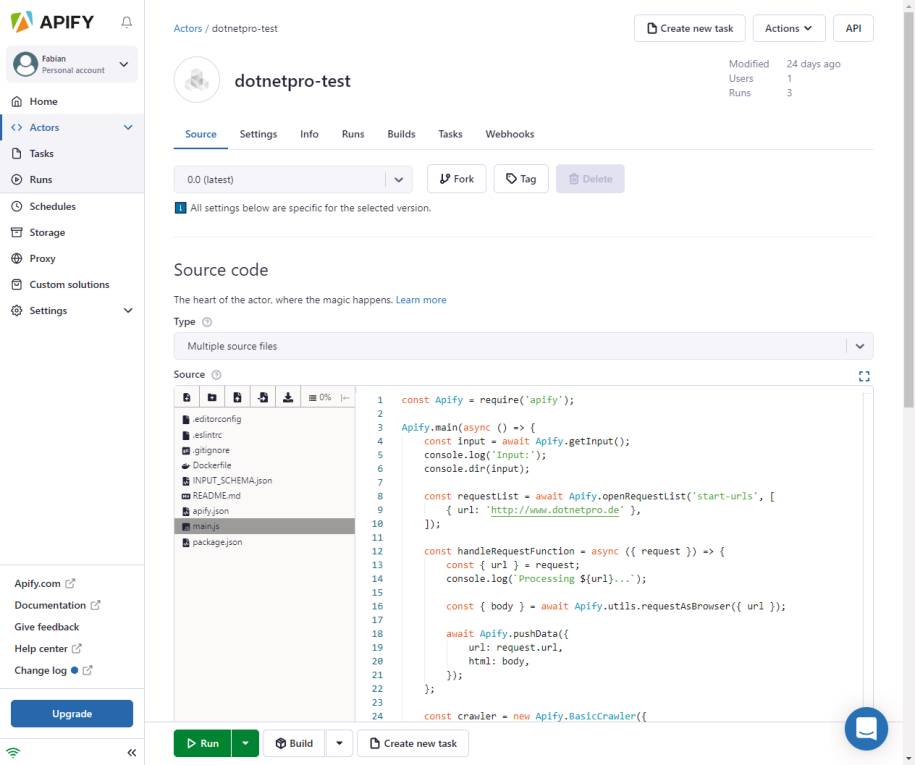
Übersicht eines neuen Actorsinklusive main-Funktion(Bild 10)
Autor
Mit diesen Möglichkeiten und Vorbereitungen lässt sich nun ein erster, eigener Actor erstellen. Listing 5 zeigt einen einfachen Crawler auf Basis des BasicCrawler von Apify. Welche verschiedenen Crawler es gibt, beschreibt der Textkasten Die verschiedenen Crawler-Typen in Apify. Der Crawler zeigt zunächst die übergebenen Input-Daten an, was optional ist. Anschließend wird eine Request-Liste geöffnet und in diesem einfachen Beispiel mit einem statischen URL gefüllt. Ein Kernelement ist die Request-Funktion, also die Page Function, die pro Seite aufgerufen wird. Dort wird das HTML-Markup über HTTP mittels der requestAsBrowser-Funktion heruntergeladen. Das ist eine komfortable und, wenn es sich um statische Websites handelt, sehr oft völlig ausreichende Vorgehensweise. In diesem Actor-Beispiel werden die Daten anschließend zurückgegeben, um sie im Dataset zu speichern. Um das Ganze zum Laufen zu bekommen, wird ein BasicCrawler-Objekt erstellt, die Request-Liste und die Request-Funktion werden übergeben und der Crawler daraufhin gestartet. Das Beispiel funktioniert problemlos direkt „out of the box“. Das ist ein Vorteil der Apify-Plattform, dass dort alles rundherum bereitgestellt wird, um mit wenigen Zeilen Code Daten aus dem Web zu sammeln.
Die verschiedenen Crawler-Typen in Apify
Als einfacher Einstieg bietet sich der Web Scraper [27] an: generisch, einfach zu nutzen und mit einem vollständigen Chromium-Browser im Hintergrund für sehr viele Anwendungsfälle geeignet. Für manche Szenarien ist das aber zu viel des Guten und die Performance leidet.
Listing 5: Einfacher Crawler auf der Apify-Plattform
const Apify = require('apify');
Apify.main(async () => {
const input = await Apify.getInput();
console.log('Input:');
console.dir(input);
const requestList =
await Apify.openRequestList('start-urls', [
{ url: 'http://www.dotnetpro.de' },
]);
const handleRequestFunction = async ({ request })
=> {
const { url } = request;
console.log(`Processing ${url}...`);
const { body } =
await Apify.utils.requestAsBrowser({ url });
await Apify.pushData({
url: request.url,
html: body,
});
};
const crawler = new Apify.BasicCrawler({
requestList,
handleRequestFunction
});
await crawler.run();
console.log('Crawler finished.');
});
Eine wichtige Option wurde noch nicht angesprochen: Beim Anlegen eines Actors lässt sich der Hosting-Typ konfigurieren. Zur Auswahl stehen: ein Projekt basierend auf mehreren Dateien, gehostet bei Apify, eine einzelne JavaScript-Datei, ebenfalls gehostet bei Apify, ein Git-Repository, eine ZIP-Datei und eine GitHub-Gist. Ein Actor muss daher gar nicht direkt bei Apify gehostet werden, denn ein Git-Repository bei GitHub ist zum Beispiel ebenfalls eine valide und sinnvolle Option.In den Einstellungen können zudem zahlreiche Optionen des Actors verändert werden, etwa Name, Beschreibung und öffentliche Informationen, die anderen dabei helfen, den eigenen Actor einzuschätzen: ein Bild, eine Readme-Datei, eine Kategorie und dergleichen. Wenn der Actor öffentlich verfügbar sein soll, dann ist es empfehlenswert, diese Informationen ordentlich anzupassen.
Arbeiten mit dem Apify SDK und dem CLI
Die bisherigen Beispiele stellten verschiedene Actor-Beispiele dar, die auf der Apify-Plattform laufen. Das hat die bereits gezeigten und erwähnten Vorteile, ist aber nicht immer erwünscht oder möglich, etwa aufgrund von Compliance-Regelungen oder anderen Richtlinien in einem Unternehmen. Das haben auch die Betreiber von Apify erkannt und bieten ein SDK an, um einen Actor lokal laufen zu lassen. Das SDK wurde bereits in unserem Beispiel zum BasicCrawler genutzt (siehe Listing 5), und zwar ganz am Anfang. Dort wurde die Apify-Klasse eingebunden, die aus dem SDK stammt:const { Apify } = require('apify');
Das funktioniert auch in einem lokalen Projekt. Das SDK steht aktuell nur unter JavaScript zur Verfügung. Das bedeutet, dass das SDK Tools dieses Ökosystems nutzen kann, was große Projekte wie Playwright, Puppeteer und Cheerio beinhaltet. Das SDK bietet es zudem an, einen Actor nicht nur lokal bereitzustellen, sondern auch auf der Apify-Plattform. Die Möglichkeiten des SDK erlauben es, die Power der Crawler, zum Beispiel Headless Chrome, Firefox und WebKit, laufen zu lassen, Listen und Queues zu verwalten und rotierende Proxies ebenso zu nutzen wie die Speicher- und Export-Funktionen von Apify. Das sind ziemlich viele Vorteile, vor allem wenn die Alternative lautet, das alles selbst zu implementieren. Das Apify SDK ist Open Source und steht auf GitHub [19] unter der Apache-2.0-Lizenz zur Verfügung.Bevor wir in die Features und etwas Beispielcode eintauchen, steht die Frage im Raum, warum das Apify SDK überhaupt zum Einsatz kommen soll – Projekte wie Puppeteer oder Cheerio lassen sich auch ohne Apify drumherum nutzen.Technisch ist das kein Problem und korrekt. Je nach Aufgabenstellung wird es aber ab einem gewissen Punkt kompliziert. Zum Beispiel, wenn eine Website inklusive Unterseiten verarbeitet werden soll und gleichzeitig diese Queue von URLs konsistent gehalten werden muss. Auch beim Verarbeiten von vielen URLs aus einer externen Datenquelle ist es nicht einfach, wenn die bereits gesammelten Daten auch dann bestehen bleiben sollen, wenn der Prozess abbricht. Rotierende Proxies sind ebenfalls ein wichtiges Thema, was die eigene Scraping-Implementierung direkt komplexer macht. Das Apify SDK hat demnach einige Vorteile zu bieten.Für die lokale Nutzung des SDK ist Node.js in Version 10.17 oder höher notwendig und ein Paketmanager wie NPM oder Yarn. Eine sehr einfache Möglichkeit, das SDK und weitere Funktionen von Apify zu nutzen, ist das Apify CLI [20]. Dieses Kommandozeilen-Tool erlaubt es nicht nur, Projekte für das beziehungsweise mit dem Apify SDK zu scaffolden, sondern beispielsweise auch, einen Actor auf der Apify-Plattform zu veröffentlichen. Das CLI lässt sich einfach installieren, zum Beispiel über Yarn:
yarn global add apify-cli
Nach der Installation ist es über das folgende Kommando möglich, ein Projekt zu erzeugen:
apify create dnp-apify-tests
Bild 11 zeigt einige der Optionen, die zur Auswahl stehen, um das neue Projekt zu erzeugen. In Listing 6 sehen Sie die main-Methode von Apify, die für ein Puppeteer-Projekt erstellt wird.
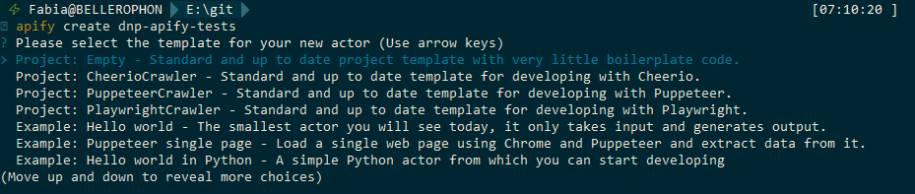
Die Optionendes Apify CLI auf der Konsole(Bild 11)
Autor
Listing 6: Beispiel-Crawler mit Puppeteer
Apify.main(async () => {
const { startUrls } = await Apify.getInput();
const requestList = await Apify.openRequestList(
'start-urls', startUrls);
const requestQueue = await Apify.openRequestQueue();
// const proxyConfiguration =
// await Apify.createProxyConfiguration();
const crawler = new Apify.PuppeteerCrawler({
requestList,
requestQueue,
// proxyConfiguration,
launchContext: {
// Chrome with stealth should work for most
// websites.
// If it doesn't, feel free to remove this.
useChrome: true,
stealth: true,
},
handlePageFunction: async (context) => {
const {
url,
userData: { label },
} = context.request;
log.info('Page opened.', { label, url });
switch (label) {
case 'LIST':
return handleList(context);
case 'DETAIL':
return handleDetail(context);
default:
return handleStart(context);
}
},
});
log.info('Starting the crawl.');
await crawler.run();
log.info('Crawl finished.');
});
Diese ist umfangreicher als die bisherigen Beispiele, nutzt aber auch weiter reichende Features, zum Beispiel eine Request-Queue und eine Proxy-Konfiguration. Letzteres ist im Code auskommentiert, da der für diesen Artikel genutzte Testaccount dieses Feature nicht unterstützt. Würde der Code aktiv bleiben, so erschiene auf der Konsole die folgende Fehlermeldung:
The "Proxy external access" feature is not enabled for
your account. Please upgrade your plan or contact
support@apify.com
Der Actor lässt sich direkt über das Apify CLI in der Konsole testen. Gestartet wird der Code über folgendes Kommando:
apify run -p
Das Flag -p steht für --purge und löscht die in einem vorherigen Schritt gesammelten Daten. Die Eingabedaten in der Datei INPUT.json bleiben aber bestehen. Dort werden auch die URLs konfiguriert, die der Actor als Quellen nutzt.Das Beispiel verdeutlicht sehr gut, was Apify auch lokal leisten kann und wie hilfreich das SDK ist, wenn es um ausgewachsene Crawling-Lösungen geht.
Wichtige Eigenschaften und Einschränkungen von Aktoren
Ein Crawler gleicht nicht zwingend einem anderen. Ein Actor in Apify kann auf Basis verschiedener Crawler implementiert sein, die alle bestimmte Eigenschaften sowie Einschränkungen besitzen. Die bisherigen Beispiele nutzten entweder den Web Scraper, den BasicCrawler oder Puppeteer. Wie bereits kurz angedeutet, ist Ersterer für den generischen Einsatz konzipiert und einfach zu nutzen. Das ist ein Vorteil; auf der anderen Seite ist diese Implementierung nicht vorteilhaft, wenn die primären Ziele Performance und Flexibilität sind. Der Grund dafür ist, dass ein vollständiger Chromium-Browser im Hintergrund zum Einsatz kommt. Dieser hat zwar viele Features, benötigt aber auch gleichzeitig viele Ressourcen. Für Websites ohne dynamische Inhalte beziehungsweise JavaScript ist das übertrieben. Der Cheerio Scraper nutzt als Gegenbeispiel einfache HTTP-Requests und lädt das HTML-Markup herunter, um dieses zu verarbeiten – ohne den Overhead eines vollständigen Browsers.Umgekehrt gelten diese Limitierungen und Einschränkungen natürlich ebenfalls. Daher ist eine Vorab-Auswahl der verschiedenen Crawler wichtig beziehungsweise die Frage entscheidend, ob einer der fertigen Crawler-Typen die eigenen Anforderungen erfüllt oder ob ein neuer Crawler mit dem Apify SDK implementiert werden muss, um noch mehr Flexibilität und Kontrolle zu bekommen. Der Textkasten Die verschiedenen Crawler-Typen in Apify bietet eine Übersicht der Crawler.Integrationen und Webhooks
Apify bietet die Möglichkeit an, die Ergebnisse von Actor-Durchläufen mit praktisch jedem beliebigen Cloud-Dienst oder einer beliebigen Web-App zu teilen. Das ist einerseits mit Integrationen, andererseits mit Webhooks möglich. Ergebnisse von Aktoren weiterzuleiten oder Benachrichtigungen bei wichtigen Ereignissen zu erhalten sind zwei wichtige Anwendungsfälle.Mit den Integrationen ist zudem ebenfalls das RESTful API von Apify gemeint. Damit lassen sich von anderen Diensten und Anwendungen aus Actors und Tasks erstellen sowie Runs starten und stoppen. Auch die Daten können über HTTP-Requests angefragt werden. Die Apify-Dokumentation widmet sich in einem eigenen Abschnitt [21] diesem Thema und zeigt in Tutorials, wie die Verknüpfung mit beispielsweise Zapier, Google und Keboola funktioniert. Der Zugriff auf das Apify API funktioniert dabei mit einem einfachen Token, das zum Beispiel mit dem Authorization Header übermittelt wird.Die Webhooks sind gut geeignet, um andere Web-Apps oder Cloud-Dienste über ein Ereignis zu informieren, das auf der Apify-Plattform aufgetreten ist. Zum Beispiel lässt sich ein Actor starten, wenn der aktuelle Lauf beendet ist oder fehlschlägt. Beim Schreiben dieses Artikels sind Webhooks bei bestimmten Events [22] erlaubt. Sie bieten die Möglichkeit an, einen HTTP-POST-Request abzusetzen.Webhooks sind momentan nur bei Actor Runs erlaubt, zum Beispiel bei Actor.Run.Create oder Actor.Run.Failed. Andere Event-Typen sollen dazukommen. Treten diese Events auf, lassen sich Aktionen [23] als HTTP-Request formulieren, um andere Dienste oder Apps zu benachrichtigen.Kosten der Apify-Plattform
Zunächst ein kurzer Hinweis zu den Aktoren. Es gibt kostenfreie und kostenpflichtige Aktoren. Die Kosten, die bei den kostenpflichtigen anfallen, sind in diesem Abschnitt aber nicht gemeint. Unabhängig davon, ob ein kostenfreier oder ein kostenpflichtiger Actor gestartet wird, fallen bei Apify die üblichen Apify-Plattformkosten an.Als Erstes entscheidet die Art der Subscription, wie mit den Kosten umgegangen wird und welche Ressourcen prinzipiell zur Verfügung stehen. Die Tests dieses Artikels wurden mit dem freien Plan erstellt, also zunächst ohne monatliche Kosten. Darin enthalten sind fünf US-Dollar an sogenannten Plattform-Credits, 4 GB RAM für Actors und sieben Tage, bis die gesammelten Daten gelöscht werden. Der nächste Plan, Personal genannt, kostet bereits 49 US-Dollar im Monat, bietet ebendiese 49 Dollar als Plattform-Credits, 32 GB an Actor-RAM und 14 Tage, bis die Daten wieder gelöscht werden. Die Website zum Apify-Pricing [24] fasst das alles gut zusammen. Beim freien Plan gibt es einen erheblichen Unterschied, wie das Überschreiten dieser Plattform-Credits gehandhabt wird. In der Regel werden die Mehrkosten mit der nächsten Rechnung abgerechnet. Beim freien Plan wird zudem der Zugriff auf die Plattform gesperrt, bis der nächste Monat beginnt.Berechnet werden die Apify-Dienste wie Aktoren, Proxies und Storage. Hier wird der Verbrauch ganz genau überwacht und ermittelt und von den Plattform-Credits abgebucht. Eine weitere Website zum Thema Platform Pricing [25] beschreibt, wie diese Berechnung konkret aussieht. Ein Actor, der mit 1 GB RAM für eine Stunde läuft, verbraucht eine sogenannte Compute Unit (CU). 6000 dieser CUs pro Monat kosten 0,25 US-Dollar pro CU. Danach sinkt der Preis in bestimmten Bereichen. Ebenso werden der Datentransfer, die Nutzung von Proxies und der Datenspeicher berechnet – nicht nur das Speichern dieser Daten über einen Zeitraum, sondern auch die Lese- und Schreiboperationen.Generell fällt bei den Subscription-Plänen auf, dass die Daten alle nach einem bestimmten Zeitraum gelöscht werden, außer beim Enterprise-Plan, der benutzerdefinierte Limits bereithält, aber auch mit einem benutzerdefinierten Preis zu Buche schlägt. Apify versteht sich somit nicht als Datenspeicher. Es ist daher sinnvoll, die Daten nach dem Sammeln und Verarbeiten von der Plattform herunterzubekommen. Ob manuell oder per API, hängt dann vom Anwendungsfall ab. Aber die Daten bei Apify zu lagern scheint keine gute Idee zu sein.Die Kosten und die Abrechnungen werden auf der Plattform übersichtlich dargestellt. Bild 12 zeigt die Kosten, die bei der Ausführung der bisherigen Beispiele dieses Artikels angefallen sind. Der apify/web-scraper hat als Beispiel 1,10 CUs verbraucht und der dotnetpro-test, unser erster eigener Actor, 0,01 CUs. Das Diagramm mit dem Verbrauch verdeutlicht zudem, dass die meisten Kosten für die Berechnungen der Aktoren zustande gekommen sind. Der Datentransfer beträgt nur ein Bruchteil davon. Die insgesamt 0,31 US-Dollar verteilen sich auf 0,28 US-Dollar für die Aktoren und 0,03 US-Dollar für den Storage-Service. Diese Aufteilung ist keine Überraschung, da die bisherigen Beispiele primär mit dem Sammeln und Verarbeiten der Daten der Websites beschäftigt waren. Daraus wurden nicht viele Daten erzeugt und gespeichert. Je nach Anwendungsfall kann sich das aber deutlich in die andere Richtung entwickeln.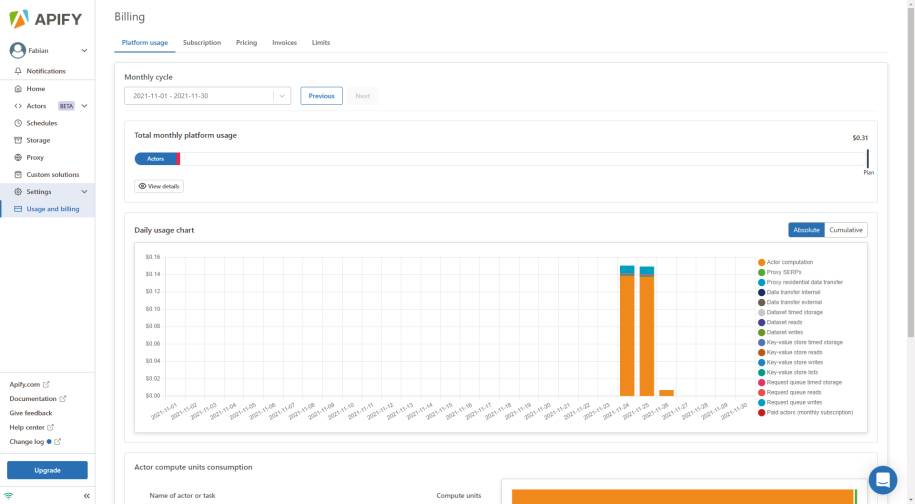
Berechnung der Kostenan einem Beispiel(Bild 12)
Autor
Vor- und Nachteile
Ein zentraler Vorteil von Apify ist, dass eine Plattform zur Verfügung gestellt wird, auf der es fertige Aktoren gibt, die sich weitreichend konfigurieren lassen. Das hilft allen, die sich mit dem ganzen Drumherum gar nicht auseinandersetzen möchten. Durch das Apify SDK ist es aber dennoch möglich, eigene Aktoren zu implementieren, die deutlich flexibler sind und lokal funktionieren. Auch die eingebaute Unterstützung für Projekte wie Cheerio, Puppeteer und andere ist ein großer Vorteil. Die Queue, um poolweise Anfragen abzuarbeiten, ist ebenso vorteilhaft wie die zahlreichen Datenformate und das Abspeichern der gesammelten Daten.Zu den Nachteilen zählt, dass Apify immer notwendig ist, wenn die Implementierung einmal damit erstellt wurde. Egal ob Plattform oder SDK, Apify bleibt mit an Bord. Die Kosten der Plattform können hoch sein, wenn alle Features genutzt werden: viele Berechnungen, hoher Verbrauch beim Datenspeicher und eine hohe Datenübertragung, auch bei Proxies. All das kann schnell ordentlich zu Buche schlagen. Zudem sind die Fristen für die Aufbewahrung der Daten nicht sonderlich hoch. Werden Daten länger benötigt, was häufig der Fall sein wird, dann müssen die Daten woandershin kopiert werden. Das verursacht weiteren Aufwand und weitere Kosten. Dass Apify allgemein etwas überwältigend sein kann, liegt an den vielen Möglichkeiten und ist nicht direkt ein Nachteil der Plattform, weil Web Scraping an sich eine nicht zu unterschätzende Lernkurve hat. An einigen Stellen könnte Apify aber mit weiteren Hilfen und Tutorials gegensteuern, was in der Vergangenheit auch immer geschehen ist.Fazit
Apify ist eine sehr mächtige Plattform. Diese versteht sich als Rundum-Lösung für die Arbeit mit den Actors, um so beispielsweise Daten zu sammeln, zu speichern, Proxies für den Zugriff auf Websites anzubieten und mit den Aktoren im Allgemeinen eine sehr flexible Möglichkeit für viele unterschiedliche Szenarien anzubieten.Die Menge an Aktoren, die über den Shop zur Verfügung stehen, sowie die Möglichkeit, diese durch Einstellungen und eine eigene Page Function zu modifizieren oder komplett eigene mithilfe des Apify SDK zu implementieren, bieten sehr viele Optionen an, die bei anderen Plattformen, Frameworks oder Bibliotheken so nicht zur Verfügung stehen.Die Kosten der Plattform könnten etwas transparenter sein. Welche Kosten konkret auf ein Projekt zukommen, ist vorab schwer auszumachen, da es zum Beispiel nicht einfach abzuschätzen ist, wie viele Computing Units bei der Verarbeitung anfallen werden. Hier hilft im Zweifel nur ausprobieren.Alles in allem bietet Apify eine sehr ausgereifte und vor allem flexible Möglichkeit an, Daten aus dem Web zu sammeln, zu speichern und für die nachfolgende Verarbeitung bereitzuhalten. Wer viel mit Web Scraping, Robot Process Automation (RPA) oder ähnlichen Aufgaben zu tun hat, sollte einen Blick auf Apify werfen.Fussnoten
- [1] Website zur Apify-Plattform, https://apify.com
- [2] Begriff der Inselgrammatiken auf Wikipedia, https://en.wikipedia.org/wiki/Island_grammar
- [3] Website zu ANTLR, https://www.antlr.org/
- [4] Fabian Deitelhoff, Sprachunterricht, dotnetpro 8/2017, Seite 88 ff.,
- [5] Informationen zu den Actors auf der Apify-Plattform., https://apify.com/actors
- [6] Informationen zu den Proxies auf der Apify-Plattform, https://apify.com/proxy
- [7] Informationen zu den Storage-Lösungen auf der Apify-Plattform, https://apify.com/storage
- [8] Informationen zum Apify SDK, https://docs.apify.com/sdk/js/
- [9] Übersicht der Aktoren in der Apify-Konsole, https://console.apify.com/actors
- Informationen zum Apify API, https://docs.apify.com/api/v2
- Informationen zu den Schedules (Zeitplänen) auf der Apify-Plattform, https://docs.apify.com/platform/schedules
- Tutorial zu den Integrationen der Apify-Plattform, https://docs.apify.com/platform/integrations
- Apify-Store mit den zur Verfügung stehenden Aktoren, https://apify.com/store
- Übersicht der Tasks in der Apify-Plattform, https://console.apify.com/actors/tasks
- Übersicht der Runs in der Apify-Plattform, https://console.apify.com/actors/runs
- Readme zur Web-Scraper-Implementierung,
- Code zur Web-Scraper-Implementierung auf GitHub,
- Projekt auf JSFiddle zum Testen von jQuery-Ausdrücken,
- Code zum Apify SDK auf GitHub,
- Code zum Apify CLI auf GitHub,
- Tutorial in der Apify-Dokumentation zu Integrationen,
- Informationen zu den Webhooks in der Dokumentation von Apify,
- Informationen zu den Aktionen bei Webhooks in der Apify-Dokumentation,
- Kosten der Apify-Plattform, https://apify.com/pricing
- Konkrete Rechnungen zu den Kosten von Aktoren auf der Apify-Plattform, https://apify.com/pricing
- Rechtliche Informationen zum Web Scraping,
- Informationen zum Web Scraper auf Apify, https://apify.com/apify/web-scraper
- Informationen zum Cheerio Scraper auf Apify, https://apify.com/apify/cheerio-scraper
- Informationen zum Puppeteer Scraper auf Apify, https://apify.com/apify/puppeteer-scraper
- Informationen zum Playwright Crawler auf Apify,











