
9. Jan 2023
Lesedauer 25 Min.
Branching-Strategien im praktischen Einsatz
Git Branching-Strategien (Teil II)
Es gibt verschiedene Branching-Strategien, von denen sich in der Praxis etliche fest in der Entwicklerszene etabliert haben.
Im ersten Teil dieser Artikelserie lag der Fokus auf der Frage, was Git ist und was diese Versionsverwaltung so beliebt macht. Ein Punkt ist, dass sich Branches und das Branching in Git sehr natürlich anfühlen, also kaum praktischen Aufwand erfordern, schnell erledigt sind und so gut wie keine Ressourcen erfordern. Da Branches lediglich einfache Dateien mit wenigen Metadaten sind, ist diese Branching-Implementierung wie gemacht dafür, um im praktischen Einsatz mit Branches als Verzweigungen zu arbeiten.Das führt direkt zu einem Vor- und einem Nachteil. Der Vorteil ist, dass Branches, die einfach zu nutzen sind, in der Praxis vielfach zum Einsatz kommen. In Git ist es normal, einen Branch zu erstellen, damit zu arbeiten und diesen Branch auch zum Remote-Repository zu pushen. Diese Normalität führt eben dazu, dass es sehr viele Entwickler in der Praxis so handhaben und fleißig Branches erstellen. Das führt nahezu zwangsläufig zum Nachteil, nämlich der Tatsache, dass eine ordentliche und geeignete Branching-Strategie vorhanden sein muss, damit die vielen Branches nicht zum Chaos führen.In diesem zweiten Teil der Artikelserie liegt der Fokus auf die schon vielfach erwähnten Branching-Strategien. Es werden einige Strategien, die sich in der Praxis bewährt haben, im Detail vorgestellt. Inklusive der Vor- und Nachteile, die es wie immer gibt. Auch der Zusammenhang mit DevOps ist spannend, sowie grundlegende Best Practices für alle Strategien.Damit der Artikel vom Umfang her nicht völlig aus dem Ruder läuft, dreht es sich schwerpunktmäßig um die sogenannten Flow-Ansätze und um die Trunk-based Branching-Strategie. Diese Strategien sind weitläufig im Einsatz und geben einen guten Einblick in die organisatorischen und technischen Anforderungen.
Allgemeine Kategorien für Branching-Strategien
Branching-Strategien lassen sich in grobe Kategorien einteilen, die etwas über die allgemeine Idee hinter der Strategie aussagen. Ohne auf die organisatorische und technische Umsetzung einzugehen.Dem Release-Branching liegt beispielsweise die Idee zugrunde, dass sich ein Release vollständig in einem Branch befindet. Der Release-Manager hat dazu zu einem bestimmten Zeitpunkt im Entwicklungszyklus einen Branch aus dem Haupt-Branch heraus erstellt. Beispielsweise mit dem Namen Dev-Branch-2.2.0. Dadurch müssen alle Änderungen im Code zwei Mal angewandt werden. Einmal für diesen Release-Branch und einmal für den Hauptzweig. Das bedeutet zusätzliche Arbeit für das Entwicklungs-Team und es kann leicht vergessen werden, beide Branches zusammenzuführen. Release-Branches können unhandlich und schwer zu verwalten sein, da viele Personen nahezu gleichzeitig über einen längeren Zeitraum an demselben Zweig arbeiten. Diese Situation ist vielen Entwicklern bekannt, wenn viele verschiedene Änderungen in einem einzigen Zweig zusammengeführt werden müssen. Daher gilt der Hinweis, dass wenn ein Versionszweig notwendig ist, sollte sich dieser Zweig so nah wie möglich an der tatsächlichen Version befinden. Das reduziert die Arbeit im Zweifel deutlich. Das Release-Branching ist ein wichtiges Konstrukt, um Versionen eines Software-Produkts zu unterstützen, die nicht mehr in aktiver Entwicklung sind, aber nicht einfach auslaufen können.Eine weitere Kategorie ist das Feature-Branching. Wie der Name vermuten lässt, wird hier ein Branch pro Feature angelegt. Häufig verbunden mit den sogenannten Feature-Toggles, um eine Funktion in einem Software-Produkt zu aktivieren oder zu deaktivieren. Dieser Schalter macht es einfacher zu kontrollieren, ob das Feature aktiv ist oder nicht. Das macht es wiederum einfacher, den Code des Feature-Branches mit einem anderen Branch, beispielsweise dem Haupt-Zweig, zusammenzuführen, da das darin enthaltene Feature nicht zwingend aktiv sein muss.Das Task-Branching ist eine weitere Kategorie für Branching-Strategien. Eine Strategie in dieser Kategorie nutzt einen Branch pro Task, also pro Aufgabe. Unternehmen haben in der Regel einen Mechanismus, wie Aufgaben erstellt, verwaltet und abgearbeitet werden. Zum Beispiel über Anwendungen wie Jira. In einer Strategie, die nach dieser Kategorie aufgebaut ist, wird jetzt pro so einem Ticket in Jira ein Branch angelegt. Alle Arbeiten auf diesem Ticket werden in diesem Branch abgelegt. Dieses Task-Branching ist auch als Issue-Branching bekannt. Ein Vorteil ist, dass auf diese Weise das Problem beziehungsweise die Aufgabe direkt mit dem Quellcode verknüpft wird. Wird nun noch der Name der Aufgabe und/oder die Nummer im Branch mit aufgeführt, ist die Verknüpfung auf den ersten Blick ersichtlich. Bei der Entwicklung lässt sich die zugehörige Aufgabe schnell wiederfinden, um einen Eindruck von der Aufgabenstellung zu bekommen, noch bevor überhaupt der Code geöffnet wird. Dieses Maß an Transparenz sorgt zudem dafür, dass es einfacher ist, bestimmte Änderungen auf den Hauptzweig oder einen länger laufenden Legacy-Release-Zweig anzuwenden. Wenn es sich darüber hinaus um User Stories dreht, passen Task-Branches gut zur agilen Entwicklung. Jede User Story beziehungsweise jede Fehlerkorrektur existiert in einem eigenen Branch, so dass leicht zu erkennen ist, welche Probleme in Arbeit sind und welche zur Veröffentlichung bereit sind.Die Namensgebung von Branches
Die Namensgebung ist in der Informatik ein Thema für sich. Nicht ohne Grund gibt es den Spruch: »Naming is hard«. Im Kontext dieses Artikels ist die Benennung von Branches gemeint. Einige Namen wie Main, früher Master, und beispielsweise Develop erscheinen recht eindeutig und sinnvoll. Konkrete Vorgaben gibt es hier aber nicht und wir können Branches grundsätzlich so benennen, wie uns das am besten in den Kram passt. Dass das einer ordentliche Branching-Strategie fundamental entgegen spricht, sollte aus dem ersten Teil dieser Artikelserie hervorgegangen sein. Wenn alle Teammitglieder die Branches so benennen können, wie sie das für richtig halten, entsteht sehr schnell sehr viel mehr Chaos, als jede Strategie je ordnen können wird.Bei der Namensgebung spielt die Lebensdauer von Branches eine nicht unerhebliche Rolle. Reguläre Branches befinden sich permanent in einem Repository. Beispielsweise der Haupt-Entwicklerzeig (dev), der Main Branch oder ein Branch für das Testen. Gibt es diese Branches, sind einige Namens bereits vergeben. Dann existieren aber noch eine ganze Reihe eher temporärer Branches. Zum Beispiel für einen Bugfix, für ein neues Feature, experimentelle Branches oder diejenige, die als Work in Progress (WIP) gekennzeichnet sind. Alle verdienen ordentliche Namen, um sie voneinander unterschieden zu können. Ob diese Branches gut auseinandergehalten werden können oder nicht, liegt aber nicht nur am Namen, sondern auch an der Gruppierung. Und die spielt wiederum bei den Branching-Strategien eine entscheidende Rolle.Wie ist das beispielsweise bei Feature-Branches? Deren Namensgebung können wir uns exemplarisch anschauen. Grundsätzlich ist jeder Name erlaubt, solange er nicht mit bereits existierenden Branches wie Main oder ähnlichen kollidiert. Am Anfang lassen sich bestimmte Wörter zur Gruppierung nutzen. Vereinfacht gesagt im Sinne von:
group_1/<branch-name>
group_2/<branch-name>
group_n/<branch-name>
und so weiter. Zum Beispiel um bestimmte Features in Gruppen einzuteilen und diese schneller wiederzufinden. Typische Namen für Gruppen sind unter anderem die Folgenden:Oftmals bieten Tools es auch an, eine Gruppe zum Beispiel Feature zu nennen, um so alle Features Branches direkt aufzufinden. Dazu mehr im dritten Teil dieser Serie zur Tool-Unterstützung. Bild 1 zeigt, wie ein Baum aus Commits und Branches nach diesem Namensschema aussehen kann. Ausschließlich zahlen sind allerdings keine gute Idee. Gerade dann nicht, wenn die Kommandozeile mit ins Spiel kommt. Beim Erweitern von Kommandos mit der Tag-Taste könnte Git auf die Idee kommen, nach SHA-1 Nummer von Commits zu suchen und im schlimmsten Fall auch welche finden. Dann wäre sich Git unsicher, ob wir Branches oder Commits meinen. Die Kombination von Gruppen, Zahlen und einem aussagekräftigen Namen ist aber wiederum eine ausgezeichnete Idee für einen Branch.
Ein schematischer Aufbauvon Commits und Branches mit Gruppennamen(Bild 1)
Deitelhoff
Einzelne Teilbereiche von Branch-Namen lassen sich mit Schrägstrichen trennen. Wie das oben bei den Gruppen schon der Fall war. So wird deutlich, dass der nachfolgende Teil zwar zum Branch-Namen gehört, aber nicht Teil eines längeren Namens ist. Dadurch lässt sich folgende Daumenregel definieren: Die Gruppe gruppiert, die Nummer spezifiziert und der Name beschreibt.Teile eines längeren Namens lassen sich durch Bindestriche voneinander trennen. Zum Beispiel beim Feature
feature/bluetooth/add-bluetooth-
connection-selection
Das Feature wird im Feature-Branch einsortiert, gehört zur Gruppe bluetooth und behandelt die Auswahl einer Bluetooth-Verbindung. Folgende Branch-Namen können wir auf diese Weise zusammensetzen:
feature/12345-modal-dialog-at-login
bugfix/12399-add-missing-link-shopping-card
Im ersten Fall ist ein Feature-Branch gemeint, daher die Gruppierung nach feature/. Anschließend folgt die Ticket-Nummer, zum Beispiel aus Jira oder einem anderen Ticketsystem heraus. Anschließend folgt eine sprechende Beschreibung. Die ergibt sich zwar grundsätzlich auch aus dem Ticket, aber auf diese Weise muss nicht erst aufwändig nachgesehen werden. Die Kombination aus Ticket-Nummer und Beschreibung verrät schon sehr viel darüber, um welche Aufgabe es sich dabei handelt. Das zweite Beispiel ist praktisch identisch aufgebaut, mit dem Unterschied, dass es sich um eine Fehlerbehebung und nicht um ein neues Feature handelt. Zusätzlich kann eine Regelung sinnvoll sein, ob deutsche oder englische Branch-Namen verwendet werden sollen, beziehungsweise ob eine Mischung in Ordnung geht. Das kann die Lesbarkeit verbessern, wenn es nur eine Variante gibt.Bei der Länge von Branch-Namen streiten sich die Geister. Auf der einen Seite sind längere, beschreibende Namen besser bei der Übersicht, wenn eine Liste von Branches durchgegangen werden muss. Diese längeren Namen können aber schnell im Weg sein, wenn es zum Beispiel um Log-Dateien geht. Dann stören die zusätzlichen Zeichen oftmals.Die oben genannten Tipps haben sich in vielen Projekten und Branching-Strategien bewährt. Hier ist Flexibilität gegeben, da wir uns auch gar nicht daranhalten müssen. Ein gewisses Schema bei Branch-Namen ist allerdings eine außerordentlich gute Idee. Wichtig ist außerdem, dass es Regeln im Team oder Unternehmen gibt, sodass jedes Teammitglied identische Schreibweisen für Branches nutzt. Git selbst legt uns hier keine Steine in den Weg, aber es wird sehr unübersichtlich und aufwändig, wenn wir uns diese Steine selbst in den Weg legen.Die Daumenregel für Branch-Namen lässt sich wie folgt zusammenfassen: Ein Branch sollte mit einer Gruppe starten. Beispielsweise feature/, bugfix/, wip/ oder ähnliches. Wie diese Namen konkret lauten ist schon fast wieder egal. Hauptsache die Intention wird deutlich und die Gruppen lassen sich unterscheiden.Ein Branch sollte eine eindeutige ID enthalten. Das macht es einfach, ihn zu finden, wenn die ID bekannt ist. Egal, wie sich der Name des Branches ansonsten noch zusammensetzt. Pluspunkte gibt es dafür, dass die ID nicht einfach nur zufällig oder fortlaufend ist, sondern mit Informationen aus anderer Stelle verknüpft sind. Zum Beispiel einem Ticketsystem.Schrägstriche (Slashes) und Minuszeichen lassen sich gut als Trenner nutzen, damit die Namen besser lesbar sind. Ob jetzt Slashes, Minuszeichen oder eine Kombination genutzt wird, ist ebenfalls eine Detailfrage. Oft werden Guppen durch einen Slash und die Namen durch Minuszeichen getrennt. Die konkrete Ausgestaltung ist aber uns überlassen.Wir sollen es vermeiden, ausschließlich Zahlen in Branch-Namen zu nutzen. Diese Namen sind zwar gut zu unterscheiden und die Suche findet diese Branches auch, allerdings fehlt die Semantik völlig.Oft gibt es in Unternehmen die Regel, den Autornamen in einen Branch-Namen mit einfließen zu lassen. Ein richtig oder falsch gibt es hier ebenfalls nicht. Ob es sinnvoll ist, ist projektweise zu entscheiden. Klar sollte sein, dass es immer nur den Autor oder die Autorin widerspiegeln kann, der oder die den Branch initial angelegt hat. Da oft mehrere Personen an einem Branch arbeiten, entsteht so eine gewisse Ungenauigkeit. Alternativ lässt sich der Team-Name in den Branch integrieren, falls es verschiedene Teams gibt. Aber das wird in der Praxis häufig durch unterschiedliche Repositories geregelt, so dass das ebenfalls nicht notwendig ist und den Branch-Namen nur aufblähen würde.Zudem sollte ein Satz an Regeln definiert und sich darangehalten werden. Ansonsten ist die Verwirrung groß. Auch sehr lange Namen für Langzeitbranches ist keine gute Idee, da diese schnell stören können. Für kurzlebige Branches besteht das Problem weniger, da sie irgendwann obsolet werden und in den Hintergrund treten.Halten sich alle in einem Projekt an diese Regeln oder eine Teilmenge davon, wird die Arbeit mit Git, Branches und verteilten Teams deutlich einfacher.
Der Zusammenhang mit DevOps
Eine ordentliche Branching-Strategie ist essenziell wichtig für eine gute DevOps-Umsetzung. Eine richtig umgesetzte Verzweigungsstrategie ist der Schlüssel zur Schaffung eines effizienten DevOps-Prozesses. Denn DevOps konzentriert sich auf die Umsetzung eines schnellen, gestrafften und effizienten Workflows, ohne die Qualität des Endprodukts zu beeinträchtigen.Dabei hilft eine Branching-Strategie zu definieren, wie das Bereitstellungsteam arbeitet und wie jede Funktion, Verbesserung oder Fehlerbehebung gehandhabt wird. Außerdem wird die Komplexität der Deployment-Pipeline reduziert, da sich das Entwicklungsteam nur auf die Entwicklung und Bereitstellung der relevanten Branches konzentrieren kann, ohne das gesamte Produkt zu beeinträchtigen.Branching-Strategien, die eine Implementierung von Continuous Integration (CI) und Continuous Delivery (CD) in DevOps-Pipelines nicht unterstützen oder erschweren, sollten in einer DevOps-Umgebung nicht verwendet werden. Das führt unweigerlich zu KonfliktenDer zentralisierte Workflow als Einstieg
Der erste Teil dieser Artikelserie hat den Workflow Nummer 0 beziehungsweise die nullte Branching-Strategie bereits kurz angesprochen. An dieser Stelle sei das noch einmal aufgegriffen, weil der zentralisierte Workflow gerade beim Einstieg in das Thema Branching-Strategien eine so entscheidende Rolle spielt. Dieser Workflow ist schnell aufgesetzt, einfach zu verstehen und hat erst einmal einen geringeren Einfluss auf die tägliche Arbeit als andere Strategien. Insbesondere, wenn vorher gar keine Strategie zum Einsatz kam oder wenn beispielsweise zu Git als Versionsverwaltungssystem migriert wird.Beim Einsatz von Git und der Überlegung, einen zentralisierten Workflow zu nutzen, kommt dann schnell die Frage auf, ob es überhaupt sinnvoll ist, ein dezentrales Versionskontrollsystem zur Organisation eines zentralisierten Arbeitsablaufs einzusetzen. Das ist nicht ganz von der Hand zu weisen. Aber wie beschrieben, ist ein zentralisierter Ansatz für einen großen Teil der Entwicklungsteams interessant. Beispielsweise für alle, die zuvor mit Systemen wie Subversion Erfahrungen gemacht haben. Wie Subversion verwendet dieser Arbeitsablauf ein zentrales Repository, das als maßgebliche Quelle für den aktuellen guten Zustand der Anwendung dient. Ein zentralisierter Branch in Git reicht aus, um diesen initialen Workflow zu etablieren. Das dient als Basis, um weitere Elemente anderer Strategien einzusetzen. Beispielsweise weitere Branches, Standards wann und wie verzweigt wird und so weiter.GitFlow ermöglicht parallele Entwicklung
GitFlow gilt als etwas kompliziert und zu fortschrittlich für viele Projekte. Diese Branching-Strategie ermöglicht die parallele Entwicklung, bei der Entwickler getrennt vom Hauptzweig an Funktionen arbeiten können, wobei ein Feature-Branch immer aus dem Main-Branch erstellt wird. Anschließend, wenn die Änderungen abgeschlossen sind, führt der Entwickler diese Änderungen zur Freigabe wieder mit dem Main-Zweig zusammen.Trotz der höheren Komplexität ist GitFlow weiterhin häufig im Einsatz ist. Zusammengefasst liegt der Fokus auf einer strengeren Branching-Politik mit zahlreichen long-running Branches für verschiedene Zwecke, beispielsweise der genannten Feature Branches. Ausgerichtet ist der Workflow auf größere Projekte und rund um den Prozess beziehungsweise die Anforderungen eines Projekt-Releases. Das ist auch ein gutes Entscheidungskriterium, ob GitFlow als Branching-Strategie für das eigene Projekt funktionieren könnte. Haben wir es mit einem eher kleinen Projekt zu tun, ist GitFlow vielleicht zu überdimensioniert.Die langläufigen Branches werden als Historie für den Projektverlauf genutzt. Davon gibt es zumindest schon mal den Main- und den Develop-Branch. Ersterer enthält die offizielle Release-Historie. Bei jedem Release müssen die Änderungen also in den Main-Branch wandern. Daher ist es auch häufiger Ritus, bei jedem Release die Commits im Main-Branch durch Tags mit Versionsnummer zu versehen. Der Develop-Branch dient als Integrationsstelle der Änderungen, die durch die jeweiligen Teammitglieder im Laufe der Zeit durchgeführt werden. Branches wie Main oder Develop werden auch häufig als Environment-Branches bezeichnet. Sie spiegeln nicht nur einen gewissen Stand im Release-Management einer in Entwicklung befindlichen Anwendung wider, sondern eben auch einen gewissen Stand einer Umgebung. Eine eingeworfene Notiz am Rande: Es ist durchaus denkbar, einen Branch Live zu nennen, um dort aktuell laufende Stände zu speichern. Nicht nur ausgelieferte, sondern vielleicht direkt durch ein Continuous Delivery System auf einen Server aufgespielte Versionsstände. Ob das sinnvoll oder eher gefährlich ist, hängt wieder von Kontext ab. Git steht uns da aber nicht im Weg.Änderungen am Code finden in den bereits bekannten Features-Branches statt. Wird die Entwicklung eines Features begonnen, ist der Startpunkt allerdings nicht der Main-Branch, sondern der Develop-Branch. Dieser dient als Ausgangspunkt für die neuen Feature-Branches, die mit Leben gefüllt werden. Ist der Zeitpunkt erreicht, wo ein Feature abgeschlossen ist, werden die Änderungen des entsprechenden Branches zurück in Develop überführt. Hier ist dann die Stelle, wo es zu potenziellen Problemen kommen kann, da alle anderen Teammitglieder ebenso verfahren. Es kann also zu Merge-Konflikten führen, wenn der Develop-Branch mittlerweile durch andere eingepflegte Feature-Branches abweicht. Dies ist die Beschreibung des Feature-Branch-Workflows, wenn wir nur die Feature-Branches und den Develop-Branch betrachten. Das ist korrekt, mit der großen Ausnahme oder Einschränkung, dass Feature-Branches niemals direkt mit dem Main interagieren sollen. Das ist beim Feature-Branch-Workflow anders. Den bisherigen Stand, was die beschriebenen Branches betrifft, verdeutlicht Bild 2.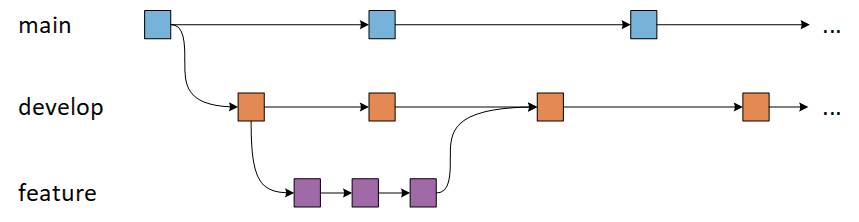
Branching-Verlauf(Schema) mit Main-, Develop- und Features-Branches(Bild 2)
Deitelhoff
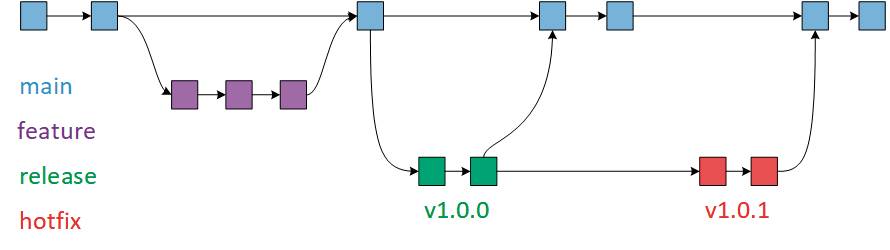
Ab jetzt ist es möglich, zu einem gewissen Zeitpunkt, zum Beispiel, weil alle Features, oder für den aktuellen Sprint ausreichend viele, umgesetzt worden sind, den Develop-Branch in den Main-Branch zu mergen. Dadurch wird gekennzeichnet, dass es sich um eine neue Produktversion handelt, die beispielsweise ausgeliefert werden kann. Eine Abweichung davon, die der GitFlow-Workflow auch so strikt vorsieht, ist der Release-Branch. In den Release-Branch werden die Features eingepflegt, wenn es zu einer neuen Version kommen soll. Der Release Branch enthält somit einen Stand des Features und ist vom Develop-Branch abgekoppelt.In den Release-Branch sollen dann nur noch Änderungen in Form von Bugfixes oder ähnlichem eingepflegt werden. Wird ein neuer Release-Branch erzeugt, kennzeichnet das einen neuen Release-Zyklus. Grundsätzlich ist es dann möglich, dass ein Teil des Teams an neuen Features arbeitet und ein anderer Teil Fehler im Release-Branch behebt. Ist alles erledigt, kann der Release-Branch in den Main-Branch eingepflegt und mit einer Versionsnummer als Tag versehen werden. Wichtig ist, dass Änderungen im Release-Branch auch zurück in den Develop-Branch überführt werden müssen, da ansonsten neue Features, die vom Develop-Branch starten, nichts davon mitbekommen.
Git-Flow Workflow mit Release-Branch
Ob diese Vorgehensweise zum eigenen Unternehmen passt oder ob eigene Release-Branches als zu viel Aufwand empfunden werden, muss jeder für sich entscheiden. Wie am Anfang dieses Abschnitts erwähnt, hängt das auch mit der Projektgröße und -Komplexität zusammen. In der Praxis sind beide Workflows anzutreffen. Sowohl streng nach dem Git-Flow Workflow mit Release-Branch als auch aufgeweichter ohne diese Trennung. Bild 3 zeigt die Änderungen der Workflows mit den besprochenen Release-Branches.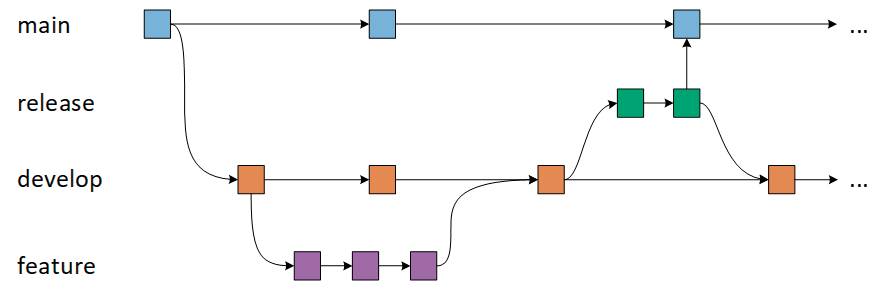
Zusätzlicher Release-Branchim Workflow(Bild 3)
Deitelhoff
Zu guter Letzt kommt eine weitere Art von Branches ins Spiel. Die sogenannten Maintenance-Branches sind für Wartungszwecke gedacht. Das bedeutet konkret, ein Hotfix-Branch aus einem Stand des Main-Branch erzeugt wird, um dort zum Beispiel Patches oder sonstige Fehlerbehebungen einzuspielen. Damit ist ein Hotfix-Branch der einzige Branch, die direkt aus dem Main-Branch erzeugt werden. Nachdem die Veränderungen durchgeführt sind, müssen die Änderungen natürlich auch wieder in den Main-Branch zurückgeführt werden. Allerdings nicht nur dorthin, auch der aktuelle Develop-Branch benötigt diese Änderungen. Oder, wenn es gerade einen aktuellen Release-Branch gibt, dort hinein. Auf diese Weise ist es möglich an Patches zu arbeiten, ohne das restliche Team an der Arbeit zu hindern. Bild 4 zeigt den letzten Stand des Workflows mit allen Arten von Branches, die angesprochen wurden. Es muss allerdings klar sein, dass eine weitere Art von Branch die Komplexität des Workflows weiter erhöht. Und mit der Komplexität steigt in der Regel auch die Fehlerwahrscheinlichkeit.
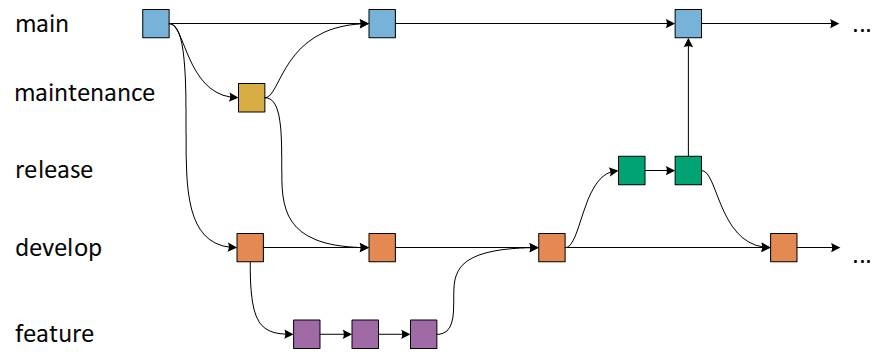
Zusätzlicher Maintenance-Branchim Workflow(Bild 4)
Deitelhoff
Zusammenfasst besteht diese Branching-Strategie somit aus den Main- und Develop-Branches, den Feature-Branches zur Entwicklung neuer Funktionen, die vom Develop-Branch abzweigen, dem Release-Branch, der bei der Vorbereitung einer neuen Produktionsversion hilft und in der Regel vom Entwicklungszweig abgezweigt wird, sowie einem Hotfix-Branch, der ebenfalls bei der Vorbereitung einer Veröffentlichung hilft. Im Gegensatz zu den Release-Zweigen entstehen Hotfix-Branches aber aus einem Fehler, der entdeckt wurde und behoben werden muss. Dieser Branch-Typ ermöglicht es den Entwicklern, im Entwicklungszweig weiter an ihren eigenen Änderungen zu arbeiten, während der Fehler behoben wird.Der vielleicht offensichtlichste Vorteil dieses Modells ist, dass es eine parallele Entwicklung zum Schutz des Produktionscodes ermöglicht, so dass der Hauptzweig für die Veröffentlichung stabil bleibt, während die Entwickler an separaten Zweigen arbeiten. Außerdem erleichtern die verschiedenen Arten von Zweigen den Entwicklern, ihre Arbeit zu organisieren. Diese Strategie enthält getrennte und überschaubare Zweige für bestimmte Zwecke, obwohl sie aus diesem Grund für viele Anwendungsfälle kompliziert werden kann. Diese Strategie ist ebenso ideal für den Umgang mit mehreren Versionen des Produktionscodes.Je mehr Zweige jedoch hinzugefügt werden, desto schwieriger kann es werden, diese zu verwalten, da die Entwickler ihre Änderungen vom Entwicklungszweig in den Hauptzweig zusammenführen. Die Entwickler müssen zunächst den Freigabezweig erstellen, dann sicherstellen, dass alle abschließenden Arbeiten auch in den Entwicklungszweig zurückgeführt werden, und dann muss dieser Freigabezweig in den Hauptzweig zusammengeführt werden.Wenn Änderungen getestet werden und der Test fehlschlägt, wird es immer schwieriger herauszufinden, wo genau das Problem liegt, da sich die Entwickler in einem Meer von Commits verlieren.Aufgrund seiner Komplexität könnte GitFlow den Entwicklungsprozess und den Veröffentlichungszyklus verlangsamen. In diesem Sinne ist GitFlow kein effizienter Ansatz für Teams, die kontinuierliche Integration und kontinuierliche Bereitstellung umsetzen wollen. Oder anders gesagt macht es diese Strategie aufgrund der zahlreichen Anforderungen und Schritte etwas schwieriger, schnell und agil zu agieren. Für Projekte und Teams, die flexibler agieren möchten, wird vielfach ein deutlich einfacherer Workflow wie GitHub Flow empfohlen.
GitHub Flow als Alternative
GitHub Flow ist eine einfachere Alternative zu GitFlow und ideal für kleinere Teams, die nicht mehrere Versionen verwalten müssen. Damit bietet sich diese Branching-Strategie für kleinere Projekte an, denn bei umfangreichen Projekten wird die Wahrscheinlichkeit immer größer, dass es zwangsläufig mehrere Produktversionen im Verlauf der Zeit gibt.Im Gegensatz zu GitFlow gibt es bei diesem Modell keine Release-Zweige. Wir beginnen direkt mit dem Main-Branch, erstellen anschließend die Develop-Branches, Features-Branches, die direkt vom Hauptzweig abstammen, um dadurch unsere Arbeit zu isolieren und die dann wieder mit dem Hauptzweig zusammengeführt werden. Der Feature-Branch wird anschließend gelöscht. Der Grundgedanke dieses Modells besteht darin, den Code im Main-Branch, oft Mastercode genannt, in einem konstanten, einsatzfähigen Zustand zu halten und somit kontinuierliche Integrations- und Lieferprozesse zu unterstützen.Das Bild 5 zeigt die notwendigen Branches für die GitHub-Flow-Strategie. Beim Vergleich mit Bild 4 wird deutlich, wie stark vereinfacht der Branching-Aufbau und der umfassende Workflow dieser Strategie sind. GitHub Flow wird damit zu einer ernstzunehmenden Alternative.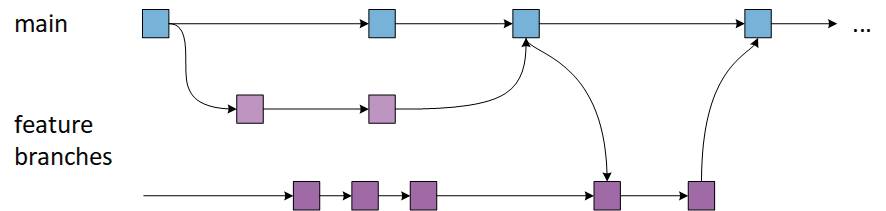
Der schematische Workflowfür GitHub Flow(Bild 5)
Deitelhoff
Diese Branching-Strategie hat ebenfalls Vor- und Nachteile. GitHub Flow basiert auf agilen Prinzipien und ist daher eine schnelle und schlanke Verzweigungsstrategie mit kurzen Produktionszyklen und häufigen Veröffentlichungen. Diese Strategie ermöglicht zudem schnelle Feedbackschleifen, so dass die Teams Probleme schnell erkennen und lösen können. Da es keinen Develop-Branch gibt, denn wir testen Änderungen in einem Branch und automatisieren diesen Prozess, ist eine schnelle und kontinuierliche Bereitstellung möglich.Diese Branching-Strategie eignet sich besonders für kleine Teams und beispielsweise Webanwendungen. Die Strategie ist ideal, wenn wir eine einzige Produktionsversion pflegen müssen. Das macht aber wiederum diese Strategie ungeeignet für den Umgang mit mehreren Versionen einer Code-Basis beziehungsweise eines Software-Produkts.Zudem bewirkt das Fehlen von Entwicklungszweigen, dass diese Strategie anfälliger für Fehler ist, was zu einem instabilen Produktionscode führen kann, wenn Branches nicht ordnungsgemäß getestet werden, bevor sie mit der Main-Release-Vorbereitung zusammengeführt werden. Das führt in der Praxis nicht selten dazu, dass Fehlerbehebungen in diesem Branch stattfinden (müssen). Der Main-Zweig kann infolgedessen leichter unübersichtlich werden, da er sowohl als Produktions- als auch als Entwicklungszweig dient.Ein weiterer Nachteil ist, dass diese Strategie eher für kleine Teams geeignet ist. Wenn die Teams wachsen, kann es zu Konflikten bei der Zusammenführung kommen, da alle in denselben Zweig zusammengeführt werden und es an Transparenz mangelt, was bedeutet, dass die Entwickler nicht sehen können, woran andere Entwickler arbeiten. Das kann dazu führen, dass eine andere Branching-Strategie zum Einsatz kommen muss, die wiederum zu definieren und einzuführen ist. Mit praktikabler Migration zwischen den Strategien.Aber es gibt eine weitere Flow-Strategie, die sich vielfach im praktischen Einsatz befindet. GitLab Flow ist eine einfachere Alternative zu GitFlow, die funktionsgesteuerte Entwicklung und Funktionsverzweigung mit Fehlerverfolgung kombiniert. Damit handelt es sich um eine weitere Vereinfachung der ursprünglichen GitFlow-Strategie und nicht um eine weitere Simplifizierung der GitHub-Flow-Strategie.Bei GitFlow erstellen die Entwickler einen Entwicklungszweig und machen diesen zum Standard, während GitLab Flow sofort mit dem Hauptzweig arbeitet. GitLab Flow eignet sich hervorragend, wenn wir mehrere Umgebungen verwalten möchten und eine von der Produktionsumgebung getrennte Staging-Umgebung bevorzugen. Sobald der Main-Branch für die Bereitstellung bereit ist, kann dieser wieder mit dem Produktionszweig zusammengeführt und freigegeben werden. Diese Strategie bietet also eine proaktive Isolierung zwischen den Umgebungen und ermöglicht es Entwicklern, mehrere Softwareversionen in verschiedenen Umgebungen zu pflegen.Während GitHub Flow davon ausgeht, dass wir immer dann in Produktion deployen können, wenn wir einen Feature-Branch mit dem Main-Branch zusammenführen, versucht GitLab Flow, dieses Problem zu lösen, indem es dem Code erlaubt, interne Umgebungen zu durchlaufen, bevor er die Produktion erreicht. Dieses Prinzip verdeutlicht das Bild 6. Hier wird deutlich sichtbar, dass wir von Main über einen Pre-Production genannten Branch, nämlich den angesprochenen Staging-Branch, auf den eigentlichen Produktions-Branch deployen.
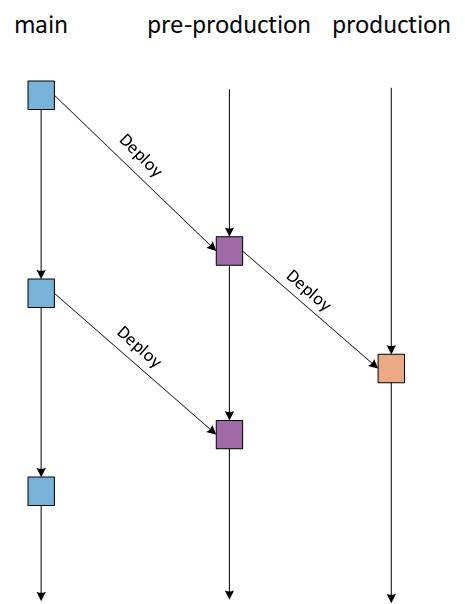
Der schematische Workflowfür GitLab Flow mit Deployments(Bild 6)
Deitelhoff
Diese Branching-Strategie eignet sich daher für Situationen, in denen sich der Zeitpunkt der Veröffentlichung nicht oder nur sehr schwer kontrollieren lässt. Ein praktisches Beispiel dafür ist eine iOS-App, die zuerst die App-Store-Validierung durchlaufen muss. Ein anderes Beispiel sind spezielle Zeitfenster für Deployment.Das vorherige Bild 6 stellt einen üblichen Aufbau für die Strategie GitLab Flow inklusive Environment-Branches dar. Da Einschränkungen lediglich organisatorische und nicht technische Natur sind, Git selbst schränkt uns nicht ein, lässt sich diese Strategie verändern und an veränderte Gegebenheiten anpassen. Beispielsweise ist es kein Problem, Production Branches einzuführen. Wenn es uns interessiert, welcher Code sich in der Produktion befindet, können wir diese Information im Produktionszweig nachsehen. Der ungefähre Zeitpunkt der Bereitstellung ist als Merge Commit im Versionskontrollsystem sichtbar. Diese Zeit ist recht akkurat, wenn wir den Produktionszweig automatisch bereitstellen. Eine genauere Zeitangabe lässt sich über ein Deployment-Skript erreichen, das für jedes Deployment einen Tag erstellt. Dieser Workflow verhindert den Overhead beim Freigeben, Markieren und Zusammenführen, der bei der GitFlow-Strategie entsteht.Weitere Anpassungen der GitLab-Flow-Strategie betreffen Environment-Branches und Release-Branches. Beide lassen sich ebenfalls in die Strategie integrieren, wenn das notwendig ist. Damit lässt sich die Strategie an die Anforderungen des eigenen Unternehmens oder Projekts anpassen, mit dem Nachteil, dass sich die Strategie schrittweise verkompliziert.
Die Trunk-based Entwicklung als Gegenentwurf
Neben den bisher vorgestellten Flow-Ansätzen als Branching-Strategien gibt es eine weitere Strategie, die im praktischen Einsatz ist. Die sogenannte Trunk-based-Entwicklung oder -Strategie wird zudem gerne als der Gegenentwurf zu den Flow-basierten Strategien bezeichnet.Dahinter steckt eine Branching-Strategie, die streng genommen keine Branches erfordert. Das ist sowohl korrekt als auch falsch, denn es gibt mindestens den Main-Branch. Feature-Branches zur Entwicklung werden aber vermieden. Egal, wie groß das Team ist beziehungsweise an wie vielen Features gleichzeitig gearbeitet wird. Was zudem fehlt sind weitere organisatorische Branches, wie zum Beispiel für Deployments, Tests oder Hotfixes.Das Entwicklungsteam integriert die Änderungen der eigenen Entwicklungen mindestens einmal am Tag in den gemeinsamen Main-Branch. Dieser gemeinsame Stamm sollte jederzeit zur Veröffentlichung bereit sein. Der Name Stamm stammt vom englischen Begriff Trunk. Daher Trunk-based Entwicklung.Der Grundgedanke hinter dieser Strategie ist, dass die Entwickler häufiger kleinere Änderungen vornehmen und somit das Ziel verfolgt wird, langlebige Branches zu begrenzen und Merge-Konflikte zu vermeiden, da alle Entwickler am selben Branch arbeiten. Mit anderen Worten bedeutet das: Die Entwickler nehmen die Integrationen (Commit) direkt in den Stamm vor, ohne Branches zu verwenden. Ein Entwickler checkt somit den aktuellen Stand des Main-Branches aus. Darin werden Änderungen vorgenommen, die vom Umfang her zeitlich in diesen Arbeitstag passen.Anschließend werden die Änderungen über Commits zurück in den Main-Branch gespielt. So gehen alle im Entwicklungsteam vor. Dadurch wird deutlich, dass die Commits nur wenige Merge-Konflikte hervorrufen sollten und wenn es doch passiert, sind die Code-Änderungen aufgrund der begrenzten Zeit überschaubar und die Merge-Konflikte nicht allzu komplex.Folglich ist die Trunk-basierte Entwicklung eine wichtige Voraussetzung für Continuous Integration (CI) und das Continuous Deployment (CD), da Änderungen am Stamm häufiger vorgenommen werden, oft mehrmals am Tag (CI), was eine wesentlich schnellere Veröffentlichung von Funktionen ermöglicht (CD). Das Bild 7 visualisiert die Funktionsweise dieser Strategie.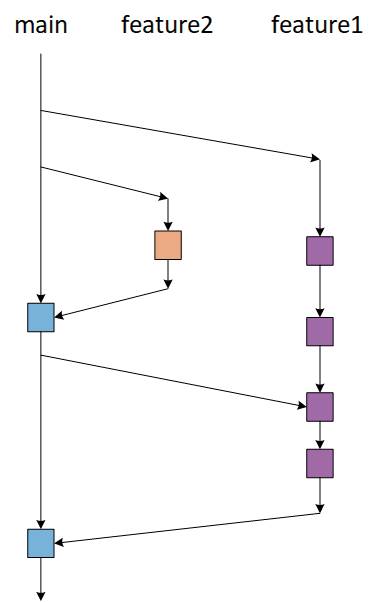
Der schematische Workflowfür die Trunk-based Entwicklung(Bild 7)
Deitelhoff
Diese Strategie wird häufig mit Feature-Flags kombiniert. Da der Trunk immer für die Veröffentlichung bereitgehalten wird, helfen Feature-Flags dabei, die Bereitstellung von der Veröffentlichung zu entkoppeln, so dass alle Änderungen, die noch nicht fertig sind, in ein Feature-Flag eingepackt und verborgen werden können, während vollständige Funktionen ohne Verzögerung für die Endbenutzer freigegeben werden können.Die Trunk-based Entwicklung ebnet den Weg für CI/CD, da der Trunk im Entwicklungsprozess konstant aktualisiert wird. Diese Strategie verbessert zudem die Zusammenarbeit, da die Entwickler einen besseren Überblick über die Änderungen anderer Entwickler haben, da die Commits direkt in den Trunk übertragen werden, ohne dass Branches erforderlich sind. Dies steht im Gegensatz zu den anderen Branching-Strategien, bei denen jeder Entwickler unabhängig in seinem eigenen Branch arbeitet und alle Änderungen in diesem Branch erst nach dem Zusammenführen mit dem Hauptzweig sichtbar werden.Da für die Trunk-based Entwicklung keine Branches erforderlich sind, entfällt der Stress durch langlebige Branches und damit auch Merge-Konflikte oder die so genannte Merge-Hölle, da die Entwickler viel häufiger kleine Änderungen einbringen. Dies macht es auch einfacher, eventuell auftretende Konflikte zu lösen. Für Fehlerbehebungen wird der gleiche Prozess genutzt. Ein Teammitglied arbeitet dann in der eigenen Kopie des Repositories nicht an einem Feature, sondern an einem Fix. Die Integration durch Commits ist aber identisch.Schließlich ermöglicht diese Strategie schnellere Veröffentlichungen, da der gemeinsame Trunk in einem konstanten veröffentlichungsfähigen Zustand gehalten wird und ein kontinuierlicher Strom von Arbeit in diesen Trunk Stamm integriert wird, was zu einer stabileren Veröffentlichung führt. Nicht selten führt diese Strategie außerdem zu einer hohen Kollaboration innerhalb des Entwicklungsteams. Der Prozess, dass das Team die eigene Arbeit täglich in den Main-Branch integriert, erzwingt automatisch ein höheres Maß an Zusammenarbeit und Kommunikation. Die Teammitglieder müssen auf derselben Seite stehen, damit diese Art von Strategie funktioniert, und die regelmäßige Zusammenarbeit gewährleistet dies.Ein großer Nachteil ist jedoch, dass diese Strategie eher für erfahrene Entwicklerteams geeignet ist, da sie ein hohes Maß an Autonomie bietet aber auch einfordert, was unerfahrene Entwickler als abschreckend empfinden könnten, da sie direkt mit dem gemeinsamen Trunk interagieren. Für ein jüngeres Team, die womöglich mehr Supervision benötigen, ist die Wahl einer anderen Branching-Strategie daher eine gute Idee.Die Anforderungen der Trunk-based Entwicklung sind dagegen überschaubar. Notwendig ist ein gut durchgeplantes und extensives Schema für das automatisierte Testen, um Fehler im Trunk schnell zu finden. Zudem sind Feature Flags erforderlich, die sich im Code oder der genutzten Konfiguration umsetzen lassen. Das muss in der Programmiersprache der Wahl möglich sein, was aber selten ein Problem darstellt. Zudem gibt es eine immer größer werdende Anzahl von spezifischen Plattformen für das Feature-Management. Beides in Kombination hilft dabei, eine Trunk-based Strategie zum Laufen zu bekommen.
Exkurs: Der Forking-Workflow
Der Forking-Workflow unterscheidet sich essenziell von anderen beliebten Git-Workflows und den genannten Branching-Strategien. Genau genommen ist es auch keine weitere Strategie, trotzdem hat dieser Workflow in der Praxis eine hohe Relevant.Der grundlegende Unterschied dieses Workflows zu den anderen Strategien ist, dass, anstatt ein einziges serverseitiges Repository als zentrale Codebasis zu verwenden, jedes Teammitglied sein eigenes serverseitiges Repository erhält. Das bedeutet, dass jeder Mitwirkende nicht nur ein, sondern zwei Git-Repositories hat. Das ist ein privates lokales und ein öffentliches serverseitiges. Der Forking-Workflow wird häufig in öffentlichen Open-Source-Projekten eingesetzt.Der Hauptvorteil des Forking-Workflows besteht darin, dass Beiträge integriert werden können, ohne dass jeder in ein einziges zentrales Repository pushen muss. Die Entwickler pushen in ihre eigenen serverseitigen Repositories, und nur eine Gruppe von Hauptverantwortlichen im Projekt können in das offizielle Repository pushen. Dies erlaubt dieser Gruppe Commits von jedem Entwickler zu akzeptieren, ohne ihnen Schreibzugriff auf die offizielle Codebasis zu geben.Der Zusammenhang eines Forking-Workflows zu einer Branching-Strategie besteht darin, dass bei diesem Workflow für die konkrete Arbeit am Projekt eine Branching-Strategie zum Einsatz kommt. In der Regel eine Strategie, die auf dem GitFlow-Workflow basiert. Das bedeutet, dass komplette Feature-Branches für den Merge in das ursprüngliche Projekt-Repository des Maintainers vorgesehen sind. Das Ergebnis ist ein verteilter Workflow, der eine flexible Möglichkeit für große, organische Teams, einschließlich nicht vertrauenswürdiger Dritter bietet, sicher zusammenzuarbeiten. Genau diese Kombination ist es, die den Workflow zu einem idealen Arbeitsablauf für Open-Source-Projekte macht.Best Practices für alle Strategien
Neben den zahlreichen Merkmalen einer guten Branching-Strategie, lassen sich zudem einige Best Practices aufstellen. Diese beziehen sich nicht alle auf eine konkrete Strategie, sondern sind eher auf der Metaebene zu verstehen.Wir sollten unsere Branching-Strategie für ein Projekt kennen und mit dem Team kommunizieren. Auch eine entsprechende Dokumentation der Strategie ist wichtig. Zudem ist es gut, die Zeit zu minimieren, in der ein Code-Teil ausgecheckt ist. Dabei geht es weniger um die Anzahl an Branches, in denen konkret gearbeitet wird, sondern die Zeit, die vergeht, bis der so abgezweigte Code wieder mit dem ursprünglichen Branch zusammengeführt wird.Eine wichtige Vorüberlegung betrifft die Abhängigkeiten. Nicht nur die technischen, sondern ebenso die organisatorischen. Bevor verzweigt wird, sollten wir uns die Frage stellen, ob andere Teams oder Abteilungen von den Änderungen betroffen sind und wenn ja, in welchem Ausmaß. Dann lässt es sich besser im Vorhinein mit diesem Team in Kontakt treten.Die Review- und Merge-Prozesse sollten beständig auf den Prüfstand gestellt werden. Ist der Prozess noch zeitgemäß oder sind Anpassungen notwendig? Funktioniert der Integrationsprozess oder kommt es vermehrt zu Fehlern? Nur weil diese Prozesse einmal aufgesetzt worden sind, heißt das nicht, dass es nicht Veränderungen geben kann, wenn sich das Projekt weiterentwickelt.Ein Versionskontrollsystem kann das Ergebnis von Branches und dem Zusammenführen nur bedingt beeinflussen. Automatisierte Tests und kontinuierliche Integration sind ebenfalls von entscheidender Bedeutung. Auch die ausgewählte Branching-Strategie ist ständig zu prüfen. Daher ist es wichtig, die Prozesse immer wieder aufs Neue zu validieren, damit sich über Zeit weniger Probleme einspielen, die ansonsten viel zu spät bemerkt werden.Fazit
Dieser Teil der Artikelserie gab einen Überblick über beliebte Branching-Strategien, deren Einsatzgebiete, sowie Vor- und Nachteile. Die verschiedenen Strategien sind entstanden, weil die Anforderungen an so einen Workflow sehr unterschiedlich sind. Sie müssen zum Projekt und die dort vorzufindenden Anforderungen passen, ansonsten bringt die beste Branching-Strategie nichts. Und das Entwicklungsteam ist ebenfalls mit einzubinden, denn das Team muss letztendlich tagtäglich mit der Strategie arbeiten.Wichtig zu betonen ist, dass alle gezeigten Beispiele für Branching-Strategien auch eben nur genau das sind: Beispiele. Vorschläge, wie die technischen Möglichkeiten von Git genutzt werden können, um die organisatorischen Herausforderungen bei Entwicklungsteams beim Umgang mit Code im Zaun zu halten.Wer mit wenigen Personen eine kleine Anwendung implementiert, braucht vielleicht nicht alle Arten von Branches beispielsweises einer GitFlow Workflows. Bei der Auswahl einer Strategie muss daher auch Zeit eingeplant und verwendet werden, den ein oder anderen Strategien anhand von Beispielen durchzuspielen, um damit warm zu werden. Ebenso beim Onboarding neuer Teammitglieder.Im nächsten und abschließenden Teil dieser Artikelserie dreht sich alles um die Unterstützung durch Tools bei Branching-Strategien. Der Support für Git ist in Anwendungen wie Entwicklungsumgebungen, der Konsole und externen Werkzeugen bereits seit geraumer Zeit enthalten. Aber auch die direkte Unterstützung für Branching-Strategien wird immer besser, so das eine Anwendung darauf achten kann, welche Branch-Namen wir nutzen und welcher Branch mit welchem anderen Branch zusammengeführt werden muss.
Inhalt
- Allgemeine Kategorien für Branching-Strategien
- Die Namensgebung von Branches
- Der Zusammenhang mit DevOps
- Der zentralisierte Workflow als Einstieg
- GitFlow ermöglicht parallele Entwicklung
- Git-Flow Workflow mit Release-Branch
- GitHub Flow als Alternative
- Die Trunk-based Entwicklung als Gegenentwurf
- Exkurs: Der Forking-Workflow
- Best Practices für alle Strategien
- Fazit











