
13. Jan 2025
Lesedauer 8 Min.
.NET-Anbindung für die Llama-KI
LLamaSharp
Open-Source-KI auf dem lokalen Gerät nutzen – mit handhabbarem Speicherbedarf und optionalem Zugriff auf externe Datenquellen.

Wer die Tech-News von heute verfolgt, stellt schnell fest: Fast jedes Produkt braucht inzwischen einen CoPilot oder ein anderes KI-Gimmick, um im Gespräch zu bleiben. OpenAI und deren KI-Dienst sind weithin bekannt, aber gibt es auch eine Möglichkeit, eine KI „lokal“ – also ohne riesige Rechenzentren im Hintergrund – zu nutzen? Genau hier kommt LLamaSharp ins Spiel.
Was ist Llama?
Llama ist ein Large Language Model (LLM) von Meta, das ähnliche Funktionen wie das bekannte ChatGPT von OpenAI bietet: Es kann menschliche Sprache verstehen und wiedergeben. Der wesentliche Unterschied zu OpenAI liegt darin, dass Meta sein Modell als Open Source bereitstellt. Dadurch hat sich ein breites Ökosystem rund um Llama entwickelt.Ein zentraler Bestandteil dieses Ökosystems ist die Bibliothek llama.cpp [1], die es ermöglicht, Llama auch auf Geräten mit begrenzten Ressourcen lokal auszuführen. Diese Geräte können zum Beispiel ein Server im heimischen Rack, ein Laptop oder sogar ein Smartphone sein. Für den Hauptentwickler Georgi Gerganov war es von Beginn an wichtig, dass man Llama auch ohne leistungsstarke Grafikkarten direkt auf der CPU nutzen kann – was zur enormen Beliebtheit dieser Bibliothek beigetragen hat.Das Ökosystem rund um Llama und GGUF
Durch das Open-Source-Modell von Llama und die Vorteile der kostengünstigen Nutzung von llama.cpp sind auch andere Sprachmodelle von verschiedenen Firmen entstanden, die mit llama.cpp kompatibel sind. Inzwischen hat sich ein Sprachformat namens GGUF (Grok’s General Unified Format) etabliert. Dieses Format wird von Sprachmodellentwicklern und Tools genutzt und ist mit llama.cpp kompatibel.LLamaSharp – .NET trifft auf Llama
LLamaSharp [2] basiert auf llama.cpp und stellt dessen Funktionen und APIs als NuGet-Paket für die .NET-Welt bereit. Damit eröffnet LLamaSharp .NET-Entwickler:innen den Zugang zu leistungsfähiger Sprachverarbeitung und KI-Funktionen direkt auf ihren Geräten.Ein wichtiger Hinweis vorweg: Dieser Artikel basiert auf der zum Zeitpunkt der Abfassung aktuellen Version 0.18 von LLamaSharp vom Oktober 2024. Das API ist seit einigen Versionen relativ stabil, jedoch handelt es sich bei KI-Themen generell um ein dynamisches und schnelllebiges Umfeld.Erste Schritte mit LLamaSharp
Die ersten Schritte mit LLamaSharp sind recht schlicht. Es beginnt mit dem NuGet-Package LLamaSharp. Dieses Package bringt Infrastrukturcode und Definitionen mit sich.Um die Modelle auszuführen, verwendet LLamaSharp sogenannte Backends, die so eingesetzt werden sollten, dass sie zur eigenen Software und vor allem Hardware passen. Die Backends nutzen das Kompilat aus dem llama.cpp-Projekt und laufen daher mit der nahezu gleichen Geschwindigkeit wie das native llama.cpp. Folgende Backends sind derzeit für LLamaSharp verfügbar:- LLamaSharp.Backend.Cpu: In diesem Backend läuft die Berechnung für Windows und Linux auf der CPU, und für Mac gibt es damit auch direkt Metal-(GPU-)Unterstützung.
- LLamaSharp.Backend.Cuda11: Für alle GPUs von Nvidia, die CUDA 11 auf Windows und Linux unterstützen
- LLamaSharp.Backend.Cuda12: Für CUDA-12-GPUs unter Windows und Linux.
- LLamaSharp.Backend.Vulkan: Für alle Vulkan-fähigen GPUs unter Windows und Linux.
LLamaSharp-Quickstart
Gehen wir davon aus, dass wir nur mit der CPU arbeiten wollen, so reichen folgende zwei NuGet-Pakete für einen rudimentären Chatbot aus:
dotnet add package LlamaSharp
dotnet add package LLamaSharp.Backend.Cpu
Der Code in Listing 1 lässt einen Chatbot auf der Kommandozeile entstehen. Hinweis: Der Code entspricht der aktuellen Projekt-ReadMe, allerdings mit einer Fehlerbereinigung. Die InferenceParams müssen unbedingt mit der DefaultSamplingPipeline initialisiert werden, ansonsten kommt es zu einer Null-Reference-Exception.
Listing 1: Ein Chatbot auf der Kommandozeile
using LLama.Common;
using LLama;
string modelPath = @"<Your Model Path>";
// change it to your own model path.
var parameters = new ModelParams(modelPath)
{
ContextSize = 1024,
// The longest length of chat as memory.
GpuLayerCount = 5
// How many layers to offload to GPU. Please
// adjust it according to your GPU memory.
};
using var model = LLamaWeights.LoadFromFile(parameters);
using var context = model.CreateContext(parameters);
var executor = new InteractiveExecutor(context);
// Add chat histories as prompt to tell AI how to act.
var chatHistory = new ChatHistory();
chatHistory.AddMessage(AuthorRole.System,
"Transcript of a dialog, where the User interacts
with an Assistant named Bob. Bob is helpful,
kind, honest, good at writing, and never fails to
answer the User's requests immediately and with
precision.");
chatHistory.AddMessage(
AuthorRole.User, "Hello, Bob.");
chatHistory.AddMessage(AuthorRole.Assistant,
"Hello. How may I help you today?");
ChatSession session = new(executor, chatHistory);
InferenceParams inferenceParams =
new InferenceParams()
{
SamplingPipeline = new DefaultSamplingPipeline(),
// Use default sampling pipeline
MaxTokens = 256,
// No more than 256 tokens should appear in
// answer. Remove it if antiprompt is enough for
// control.
AntiPrompts = new List<string> { "User:" }
// Stop generation once antiprompts appear.
SamplingPipeline = new DefaultSamplingPipeline(),
};
Console.ForegroundColor = ConsoleColor.Yellow;
Console.Write(
"The chat session has started.\nUser: ");
Console.ForegroundColor = ConsoleColor.Green;
string userInput = Console.ReadLine() ?? "";
while (userInput != "exit")
{
await foreach (
// Generate the response streamingly.
var text
in session.ChatAsync(
new ChatHistory.Message(AuthorRole.User,
userInput),
inferenceParams))
{
Console.ForegroundColor = ConsoleColor.White;
Console.Write(text);
}
Console.ForegroundColor = ConsoleColor.Green;
userInput = Console.ReadLine() ?? "";
} Quickstart – Erklärung
Der erste Teil des Codes in Listing 1 bis zur ChatHistory betrifft nur das Laden des Modells. Wie man konkret zu einem Modell kommt und ein passendes auswählt, wird im nächsten Abschnitt beschrieben. Als Einstieg kann man mit den vorgegebenen Werten loslegen, ohne irgendwelche Befürchtungen haben zu müssen, dass das System gleich in die Brüche geht. In einer Produktionsumgebung ist jedoch wahrscheinlich eine detailliertere Anpassung erforderlich.Anschließend wird die ChatHistory instanziert. Wer bereits Erfahrungen mit ChatGPT-Einstellungen hat, wird das Muster erkennen: Ein genereller Kontext wird als System-Nachricht festgelegt und definiert die Grundregeln für den Chatbot. Der Assistent repräsentiert den eigentlichen Chatbot, und der Benutzer wird als User bezeichnet. Die ChatHistory dient zur Speicherung des Gesprächsverlaufs und wird der Session übergeben. Die Interaktion mit dem Benutzer erfolgt dann innerhalb der while-Schleife.So viel zum Code, jedoch bleibt die Wahl des Sprachmodells der wichtigste Faktor.Modellsuche mit LM Studio
Der einfachste Weg, an Modelle zu kommen, führt über LM Studio. Dieses kostenlose Programm läuft sowohl unter Linux und Windows als auch unter macOS und ermöglicht es, lokale LLMs (Large Language Models) herunterzuladen und direkt auf dem eigenen System zu verwenden.Neben den Basisfunktionen bietet LM Studio auch einen integrierten Chatbot, sodass Modelle direkt getestet werden können. Außerdem gibt es ein lokales Web-API im Stil des OpenAI-API, über das Anwendungen nahtlos auf die Modelle zugreifen können.Wichtig: LM Studio hostet selbst keine Modelle, sondern greift auf die Daten von Huggingface.co zu. Man könnte also sagen: Was GitHub für Code ist, ist Huggingface für KI-Modelle. Dort finden sich nicht nur Modelle zur Erstellung von Chatbots, sondern auch solche für Aufgaben wie Bilderkennung oder -erzeugung, Audioverarbeitung und andere mehr. In LM Studio beschränkt man sich allerdings aktuell auf die Chatbot-Modelle.Um unser LLamaSharp-Beispiel auszuführen, suchen wir ein Modell über die Discover-Funktion in LM Studio aus, siehe Bild 1.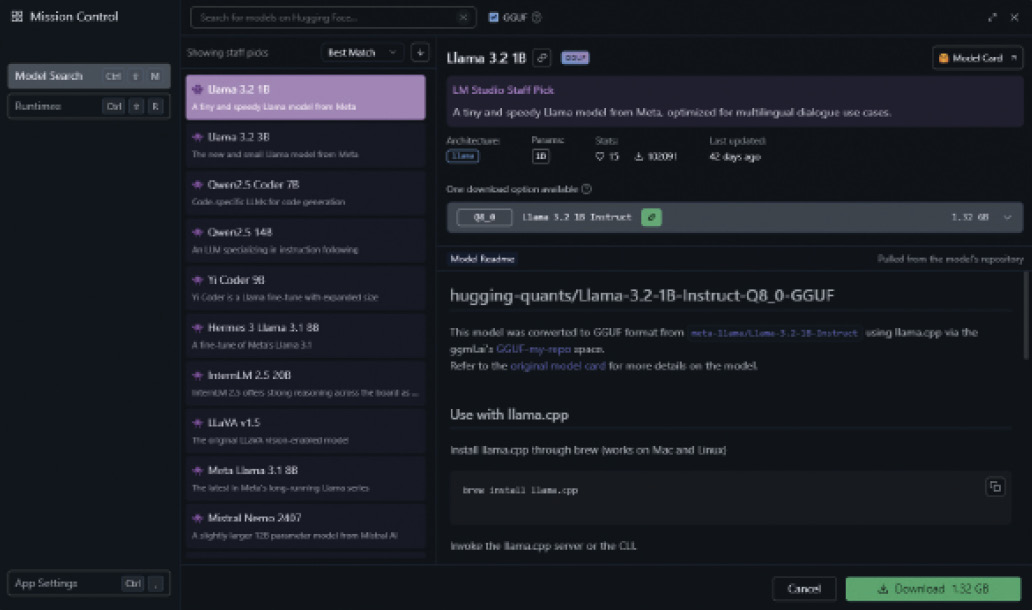
Auswahl eines KI-Modells über die „Discover“-Funktion in LM Studio (Bild 1)
Autor
Modellwahl
Wie in Bild 1 zu sehen ist, stehen uns weit mehr als nur ein Modell zur Verfügung. Aktuell gilt: „Große“ Modelle bewältigen deutlich komplexere Aufgaben als kleinere. Die LLM-Community bietet auf der Plattform LMArena.ai [4] eine Art Ranking für diese Modelle an, in dem verschiedene Leistungsaspekte verglichen werden.Der derzeitige Spitzenreiter ist das Modell ChatGPT-4o. Allerdings ist es proprietär und aufgrund seiner enormen Größe für lokale Anwendungen ausgeschlossen.Ein guter Kompromiss – besonders für experimentelle Zwecke – ist das Modell „Phi 3.1 Mini 128k“ von Microsoft. Es ist mit einer Größe von 3,1 GByte relativ kompakt und kann daher problemlos in den Arbeitsspeicher der meisten aktuellen Systeme geladen werden.Das heruntergeladene Modell findet sich später unter dem Menüpunkt My Models wieder, siehe Bild 2. Von dort können wir den Dateipfad zum Modell herauskopieren und nun in unsere Demoanwendung einfügen.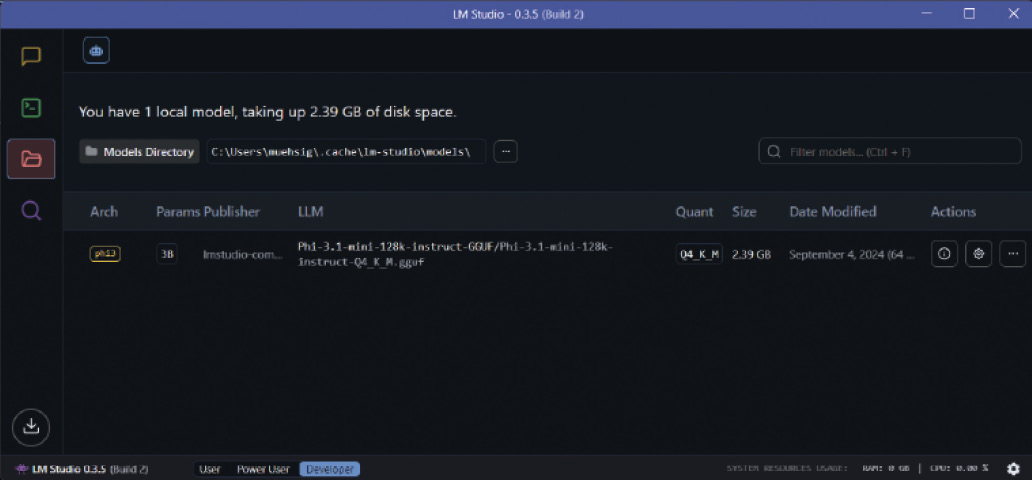
Heruntergeladene Modelle finden sich unter „My Models“ (Bild 2)
Autor
Demo mit Phi 3.1
Nachdem wir die Demo mit dem Phi-3.1-Modell gestartet haben, erhalten wir zunächst viele Informationen rund um das Modell. Anschließend kommt der „Assistent“ ins Spiel, und es ist möglich, mit ihm wie in Bild 3 gezeigt Nachrichten auszutauschen.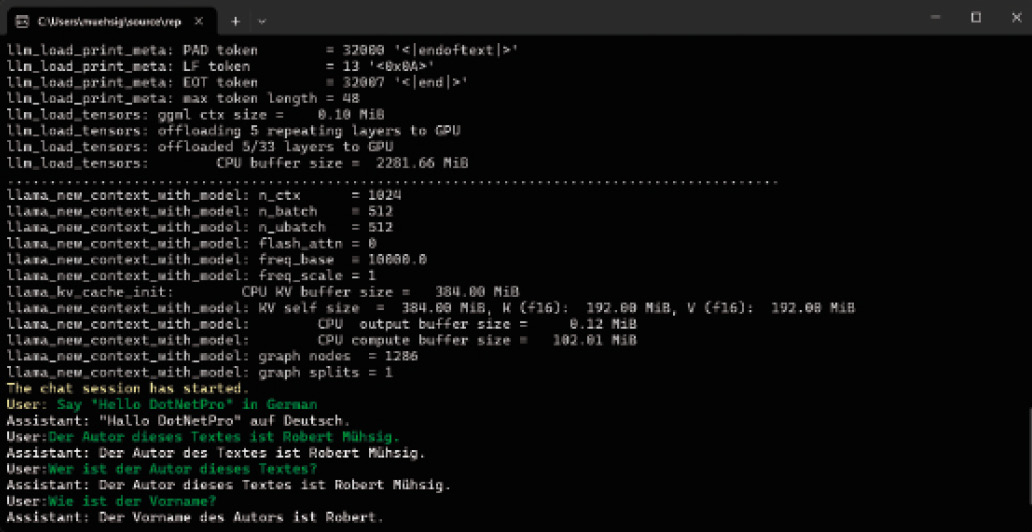
Nachrichtenaustausch mit dem Assistenten des Phi-3.1-Modells (Bild 3)
Autor
Mehr Wissen mit RAG
Sprachmodelle verfügen über ein grundlegendes Verständnis der Welt, jedoch fehlt ihnen oft Detailwissen. Besonders kleinere Modelle stoßen hier schnell an ihre Grenzen, aber auch größere Modelle wie ChatGPT benötigen zusätzliches „Domänenwissen“, um spezifische Themen abzudecken.Eine einfache Möglichkeit hierfür besteht wie in Bild 3 gezeigt darin, relevante Informationen als Chat-Nachricht in das Gespräch einzubringen. Das funktioniert gut für kleinere Textabschnitte, ist jedoch bei längeren Dokumenten kaum praktikabel. Hier kommt RAG (Retrieval-Augmented Generation) ins Spiel. Mit RAG kann ein Sprachmodell auf externe Datenquellen zugreifen und so Informationen dynamisch abrufen. LLamaSharp unterstützt RAG ebenfalls: mithilfe des Kernel-Memory-Projekts von Microsoft [5].Überblick und Fazit
Wie bereits im Intro erwähnt, ist das Thema KI allgegenwärtig – und dabei äußerst umfangreich. LLamaSharp bietet hier eine elegante Lösung als Wrapper für das llama.cpp-Projekt und macht den Einstieg in die Arbeit mit KI für .NET-Entwicklerinnen und -Entwickler deutlich einfacher. Dank der Integration des Kernel-Memory-Projekts von Microsoft steht auch die Option zur Verfügung, Retrieval-Augmented Generation (RAG) [6] zu nutzen und somit dynamisch auf externe Datenquellen zuzugreifen.Für alle, die sich mit LLMs beschäftigen oder dies planen, ist LM Studio eine klare Empfehlung. Besonders für Anfänger, die noch nie von „GGUF“ oder „Huggingface“ gehört haben, stellt das Programm eine wertvolle Hilfe dar: Es vereinfacht den Download und das Testen von Sprachmodellen und überwindet so technische Hürden auf elegante Weise.Alternativen zu LLamaSharp
Ein aktueller Trend in der Chatbot-Entwicklung ist die Verwendung des OpenAI-Web-API als De-facto-Standard. Das zeigt sich auch in den verfügbaren NuGet-Paketen: Mit Azure.AI.OpenAI und OpenAI lassen sich Anwendungen sowohl für den ChatGPT-Endpunkt als auch für den Azure-Dienst entwickeln, da beide denselben API-Standard nutzen. Interessanterweise bieten auch andere KI-Dienste, wie etwa xAI, ein OpenAI-kompatibles API an. Ein weiteres Beispiel ist LM Studio, das ein lokales, OpenAI-kompatibles Web-API bereitstellt und somit einfache Tests ermöglicht. Und es gibt Ollama, ein Open-Source-Projekt, das die Funktionen von llama.cpp über ein OpenAI-kompatibles API zugänglich macht.Der Vorteil dieser Kompatibilität liegt darin, dass ein OpenAI-API-Client flexibel zwischen verschiedenen Implementierungen wechseln kann. LLamaSharp selbst bietet aktuell jedoch noch kein eigenes Web-API. Ein Nachteil der API-Nutzung ist der zusätzliche Bedarf an einem Server, der die Anfragen verarbeitet – dies kann jedoch auch zur Lastverteilung beitragen. In der LLamaSharp-Community gibt es Überlegungen für ein OpenAI-kompatibles Web-API (siehe Issue #269, [7]), wobei die Umsetzung aktuell noch offen ist.Zusammengefasst lässt sich sagen, dass LLamaSharp besonders gut in eine .NET-Umgebung passt. Wenn die Anwendung vollständig lokal ausgeführt werden soll, ist ein Umweg über ein WebAPI eher hinderlich. In anderen Konstellationen sollte jedoch geprüft werden, ob eine API-basierte Lösung sinnvoll ist.
Fussnoten
- llama.cpp bei GitHub,
- LLamaSharp bei GitHub,
- LLamaSharp, Using CUDA when both CPU and Cuda12 back-ends are present, #456,
- Chatbot Arena LLM Leaderboard: Community-driven Evaluation for Best LLM and AI chatbots,
- kernel-memory bei GitHub,
- Retrieval-augmented generation bei Wikipedia,
- LLamaSharp, Create HTTP API server and provide API like OAI, #269,










