
17. Mai 2019
Lesedauer 3 Min.
Ein Beispiel zu Bloom-Filtern
Probabilistische Datenstruktur
Ein Bloom-Filter ist eine Datenstruktur, die entwickelt wurde, um schnell und speichereffizient zu prüfen, ob ein Element in einem Set vorhanden ist.
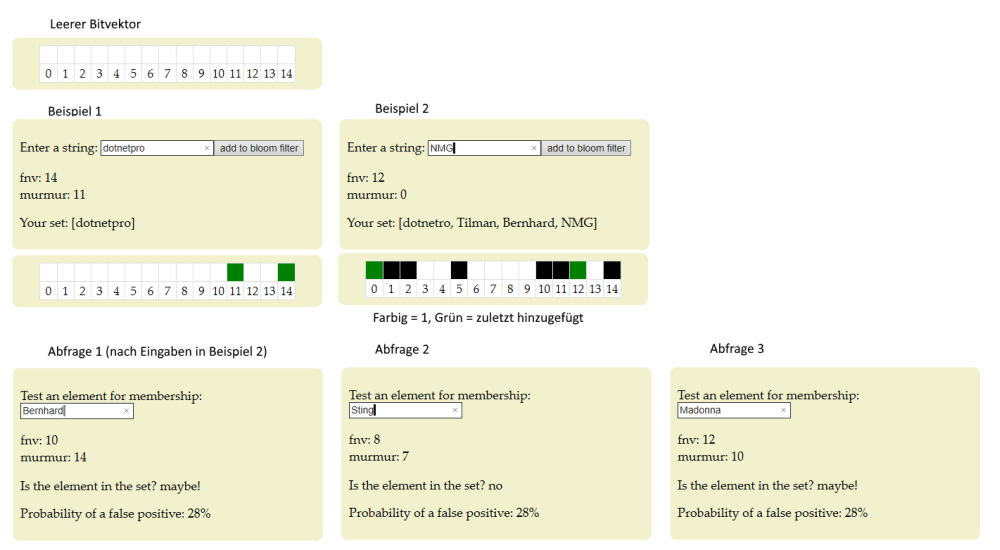
Der Preis für seine Effizienz ist, dass ein Bloom-Filter eine probabilistische Datenstruktur ist: Er sagt uns, dass das Element entweder definitiv nicht im Set ist oder sich im Set befinden kann. Basisdatenstruktur eines Bloom-Filters ist ein Bitvektor. Stellen Sie sich für ein Beispiel ein leeres Array mit 15 Elementen vor (Index: 0 bis 14) – siehe Bild. Jede leere Zelle in diesem Array hat einen Index und repräsentiert ein Bit. Um ein Element zum Bloom-Filter hinzuzufügen, hashen wir es einfach ein paar Mal und setzen die Bits im Bitvektor auf den Index dieser Hashes auf 1. Es ist einfacher zu sehen, was das bedeutet, als es zu erklären. Im abgebildeten Beispiel 1 wurde der String "dotnetpro" eingegeben. Im Bitvektor wurden durch die einfachen Hash-Funktionen Fnv und Murmur die Indizes 11 und 14 mit einer 1 belegt. In Beispiel 2 wurden drei weitere Strings hinzugefügt.Um die Mitgliedschaft zu testen, werden die abzufragenden Zeichenketten mit den gleichen Hash-Funktionen bearbeitet und geprüft, ob diese Werte im Bitvektor gesetzt sind. Sind sie nicht gesetzt, wissen Sie, dass das Element nicht in der Menge ist (Abfrage 2). Sind sie gesetzt (Abfragen 1 und 3), dann wissen Sie nur, dass das Element enthalten sein könnte (maybe!), denn ein anderes Element oder eine Kombination von anderen Elementen könnte die gleichen Bits gesetzt haben (Abfrage 3).Die in einem Bloom-Filter verwendeten Hash-Funktionen sollten unabhängig und gleichmäßig verteilt sein. Sie sollten auch so schnell wie möglich sein (kryptographische Hashes wie sha1sind daher keine gute Wahl). Beispiele für schnelle, einfache Hashes, die unabhängig genug sind, sind murmur, die fnv-Serie von Hashes und HashMix.Mehr über Bloom-Filter erfahren Sie im Bloom-Filter-Tutorial von Entwickler Bernardo Sulzbach (auch auf GitHub), in diesem Beitrag von C. Titus Brown sowie auf Wikipedia.










