
18. Apr 2022
Lesedauer 20 Min.
Newsletter-System in 20 Minuten
Flow-Designs mit Make
Der passende Dienst kann die Entwicklungszeit immens verkürzen.

Manchmal gibt es Tools und Technologien, die für mich wie die Faust aufs Auge passen. Sie erfüllen einen lang gehegten Wunsch oder sogar ein gar nicht mal so bewusstes Bedürfnis. Intellisense, Garbage Collection oder LINQ sind für mich Beispiele dafür. Und jetzt: Make, das früher Integromat hieß.Make hat mich vom ersten Moment an begeistert, weil darin Entwurf, Codierung und auch noch Serviceorientierung zusammenkommen. Aber der Reihe nach …
Software als Bündel von Datenflüssen
Für mich ist auch moderne Software lediglich ein Bündel von Kommandozeilenprogrammen. Der einzige Unterschied: Diese Kommandozeilenprogramme werden nicht direkt mit Kommandozeilenparametern gesteuert und Ergebnisse werden nicht auf der Konsole ausgegeben, sondern grafische Benutzeroberflächen (GUI) auf dem Desktop oder im Web beziehungsweise REST-APIs sind vorgeschaltet. Dahinter jedoch könnte es wie früher aussehen.Ein triviales Beispiel soll verdeutlichen, was ich meine: ein Programm, das die Zahl der Tage in einem Monat ausgibt. Wie würde das modern auf dem Desktop aussehen?Das Programm würde durch Doppelklick aufgerufen, würde einen Dialog zeigen, in dem der Benutzer einen Monat auswählt, und dafür sofort die Anzahl der Tage anzeigen. Bild 1 gibt einen Eindruck von der grafischen Oberfläche. Die Anwendung würde auf zwei Ereignisse reagieren: die Selektion eines Eintrags in der Combobox und die Veränderung der Jahreszahl. In beiden Fällen würde jedoch dasselbe geschehen: Mit Monat und Jahr würde eine Funktion die Zahl der Tage bestimmen.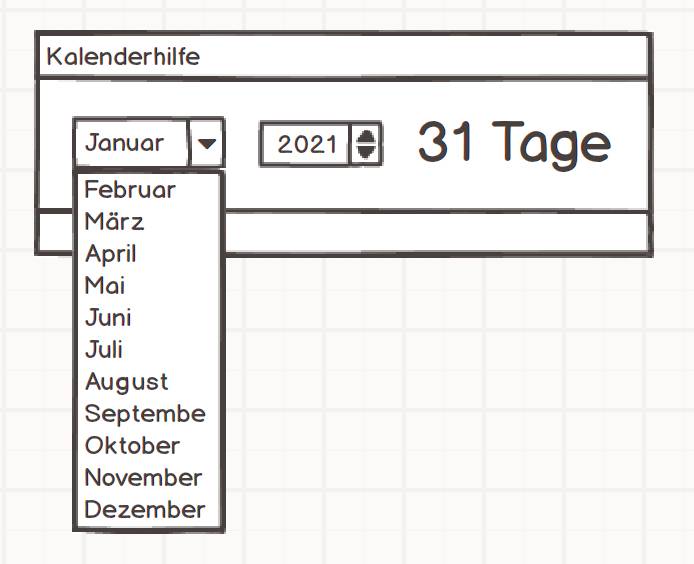
Grafische Oberflächeeiner modernen Anwendung(Bild 1)
Autor
Das GUI wäre abhängig von der Funktion. Oder mit ein bisschen Struktur: Das GUI wäre von der Domäne abhängig. Oder ein bisschen allgemeiner: Das Frontend wäre vom Backend abhängig (Bild 2).
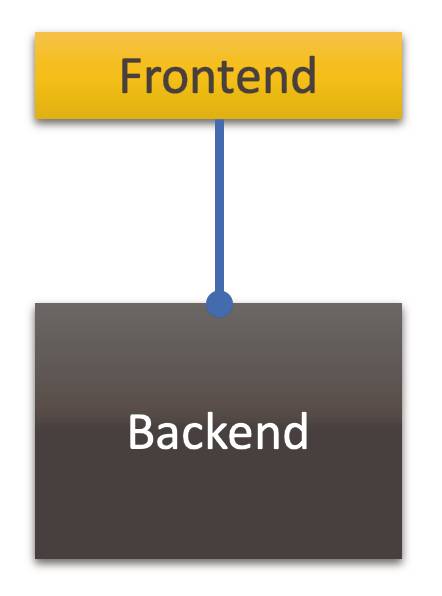
Das Frontendist vom Backend abhängig(Bild 2)
Autor
Das ist eine saubere Arbeitsteilung; das Single Responsibility Principle (SRP) wird honoriert:
- Entscheidungen darüber, wie das Programm mit dem Benutzer kommuniziert, sind im Modul Frontend gekapselt.
- Entscheidungen darüber, wie Funktionalität erbracht wird, sind im Backend gekapselt.

Die Domänenlogikist modularisiert(Bild 3)
Autor
$ dotnet kalenderhilfe.dll 2 2020
29
$
Was hätte sich verändert? Nur das Frontend. Das sähe nun vielleicht wie in Bild 4 aus. Statt die Parameterwerte aus GUI-Steuerelementen auszulesen, werden sie nun von der Kommandozeile gepflückt; statt das Ergebnis einem GUI-Steuerelement zuzuweisen, wird es auf der Konsole ausgegeben.

Ein Frontendfür eine Kommandozeilenanwendung(Bild 4)
Autor
Die Oberfläche hat sich verändert. Der Kern ist gleich geblieben. Das ist für mich entscheidend. Um diesen Punkt zu betonen, kann ich das Beispiel ins Extreme treiben: Das Kommandozeilenprogramm könnte vom GUI-Programm aufgerufen werden; auf diese Weise ließe sich eine existierende Software aufhübschen (Bild 5).

Das Backendmuss nicht im selben Prozess implementiert sein wie das Frontend. Es kann als weiterer Prozess bei Bedarf instanziert werden(Bild 5)
Autor
Moderne Software als Bündel von Kommandozeilenprogrammen? Genau. Das ist meine grundlegende Sicht, die mich aus dem Feuerwerk der Frontend-Technologien rettet. Vorgestern WinForms, gestern WPF, heute HTTP-Controller, morgen MAUI (.NET Multi-platform App UI [1])? Das ist mir einerlei. Wer sich für die ein oder andere Benutzerschnittstellentechnologie interessiert, mag sich damit beschäftigen. Wer dagegen an Funktionalität interessiert ist, kann sich unabhängig von der UI-Technologie darauf konzentrieren.Egal auf welcher Technologie ein Frontend basiert, es tut immer dasselbe:
- Collect: Es sammelt Benutzereingaben von einem Input-Medium, zum Beispiel Kommandozeile, Konsole, WinForms-Steuerelement, JSON/HTTP.
- Project: Es projiziert Daten auf ein Output-Medium, zum Beispiel Konsole, WPF-Steuerelemente, JSON/HTTP.
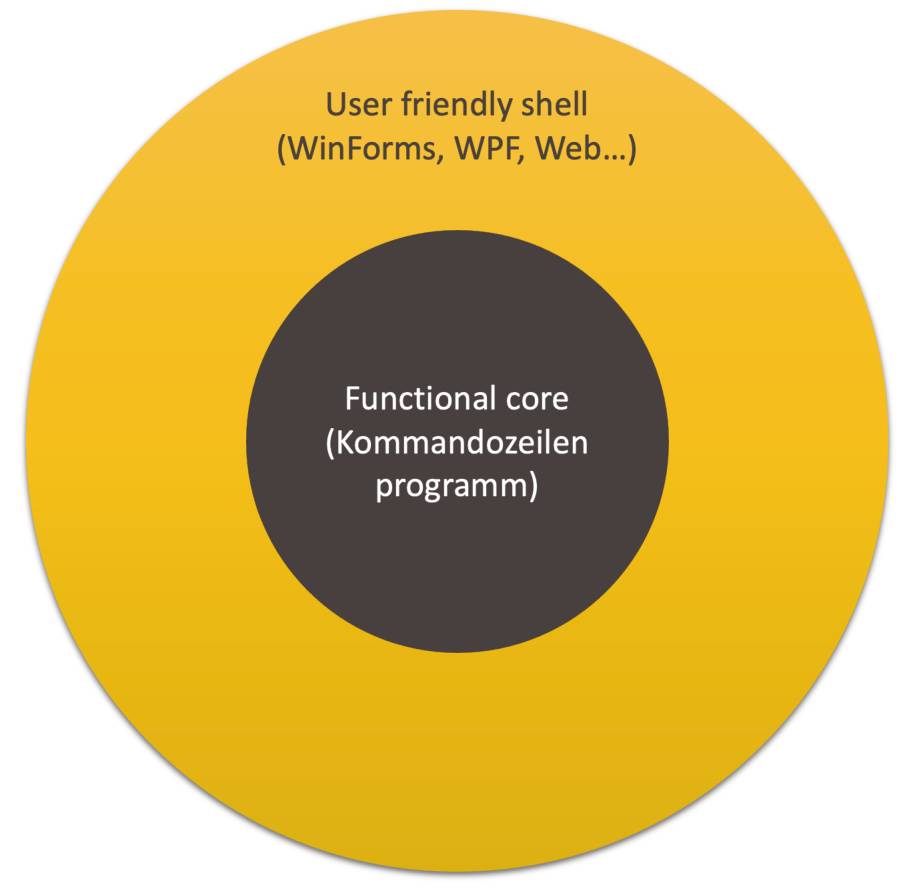
Eine universelle Architektur, die die grundlegenden Aspekte trennt(Bild 6)
Autor
Damit will ich nicht sagen, dass Anwendungen so gebaut werden sollen. Es ist für mich mehr ein Denkmodell. Andererseits: Warum nicht? Es gibt nur einen Grund, der dagegen spricht: suboptimale Performance. Doch wäre die Performance wirklich so schlecht? Wenn das messbar ist, dann kann schrittweise optimiert werden. Solange es aber nur eine Ahnung bleibt, könnte bis zum Beweis des Gegenteils so strukturiert werden.Warum? Darin liegt doch ein Zusatzaufwand, weil der Functional Core Input und Output (de)serialisieren müsste. Für mich liegt der Vorteil in der deutlichen Trennung der grundlegenden Aspekte.Im Web ist das normal: Das Frontend wird mit HTML/JS realisiert, der Functional Core, das Backend, wird etwa als REST-Service mit .NET/C# oder Node.js/TypeScript umgesetzt. Der Performance-Verlust durch die Kommunikation wird ausgeglichen durch die Skalierbarkeit. Warum so eine strikte Trennung nicht grundsätzlich denken?Aber wie gesagt, erst einmal ist das nur ein Denkmodell. Dazu gehört für mich auch die Trennung der beiden Aspekte innerhalb des Frontends: Collection und Projection (Bild 7). Selbst wenn für beides dieselbe Technologie benutzt wird, ist das, worum es geht, doch sehr verschieden.
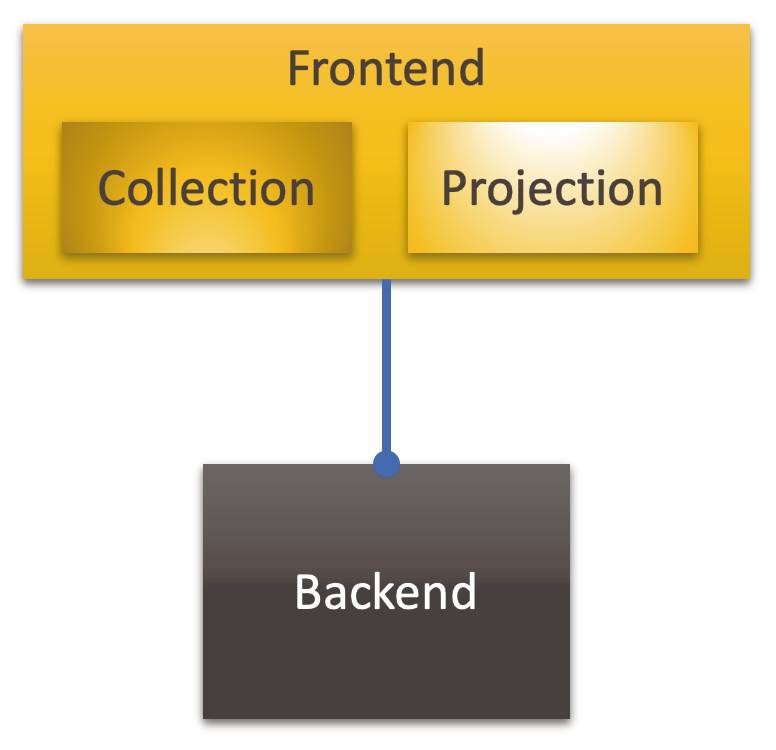
Trennungder Aspekte des Frontends(Bild 7)
Autor
Um diese Trennung deutlich zu machen, finde ich es hilfreich, die Abhängigkeit von Frontend zu Backend aufzubrechen. Die Abhängigkeit ist unnötig beziehungsweise nicht hilfreich und allenfalls ein Implementationsdetail. Entscheidend ist die Intention:
- Dass unterschiedliche Aspekte ihre Arbeit als Funktionseinheiten innerhalb eines Prozesses tun.
- Dass jede Funktionseinheit mit den passenden Daten versorgt wird.
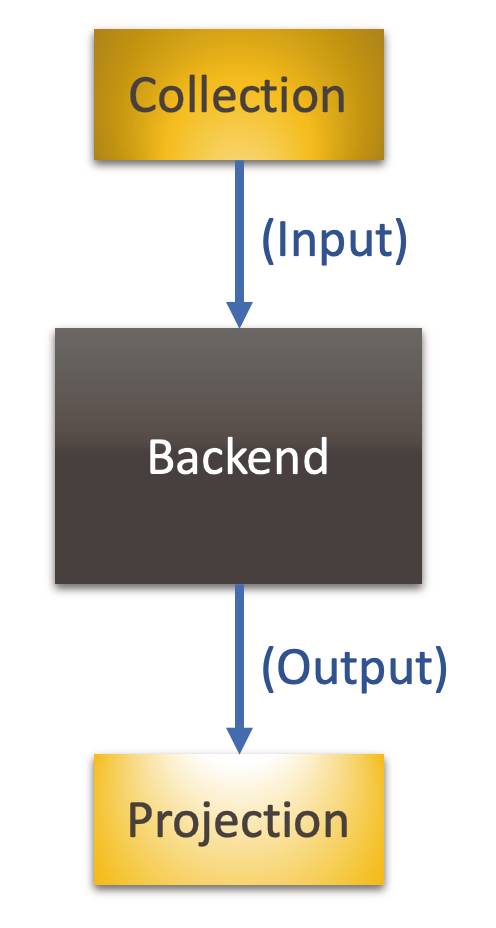
Frontend-Aspekte und Backendals Funktionseinheiten in einem Datenfluss: Ein Prozess für die Transformation von Benutzereingaben in Programmreaktionen(Bild 8)
Autor
- Irgendwie sammelt das Frontend Input aus der Umwelt. Dieser Input ist das Produkt der Collection, die ihn als Prozessschritt ausstößt – zur weiteren Verarbeitung downstream durch andere Funktioneinheiten im Prozess.
- Das Backend wartet auf Input, um daraus ein Ergebnis herzustellen, den Output. Er ist der Ausstoß des Backends in den Prozess und wird downstream verarbeitet.
- Das Frontend wartet darauf, etwas der Umwelt zu präsentieren. Es projiziert den Output in einer für den Benutzer nützlichen Weise.
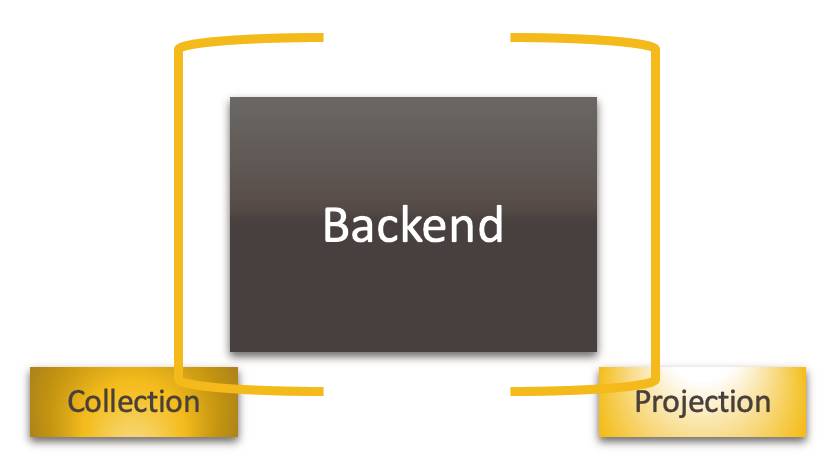
Die Aspekte des Frontendsklammern den Functional Core einer Software(Bild 9)
Autor
Die Funktionalität, die das Backend verkörpert, besteht natürlich aus vielen Facetten. Das API des Backends veröffentlicht viele Funktionen. Diesen vielen Funktionen stehen viele Trigger im Frontend gegenüber, die die funktionalen Facetten anstoßen; und es gibt Arten der Darstellung von Ergebnissen dieser Facetten.Im Prinzip kann deshalb der eine Block, der das Backend bisher darstellte, aufgelöst werden in viele. Jede Facette des Backends kann durch einen eigenen Block repräsentiert und mit den Aspekten des Frontends verbunden werden (Bild 10).
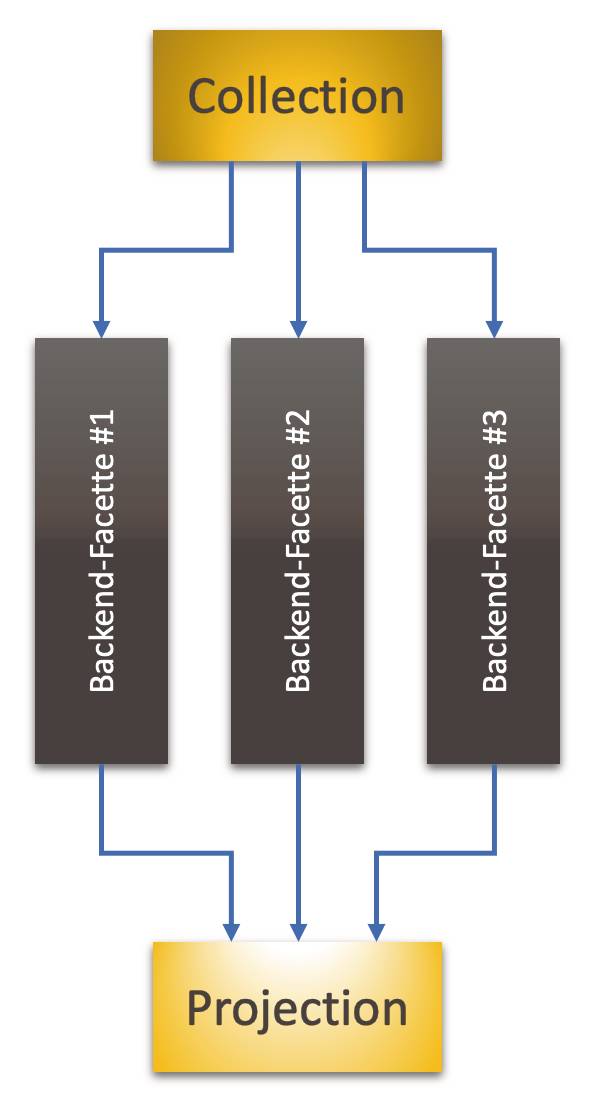
Funktionale Facetten(Sub-Funktionalitäten) des Backends können als eigenständige Backends angesehen und separat in Prozessen mit den Frontend-Aspekten zusammengefasst werden(Bild 10)
Autor
Wie die Darstellung suggeriert, kann jede Facette als kleineres, eigenständiges Backend angesehen werden. Das bedeutet, jede Facette könnte auch als eigenständiges Kommandozeilenprogramm realisiert werden. Ultimativ wäre das Ergebnis eine Lambda-Architektur, bei der jede Funktion des Backends für sich verpackt ist. Mit Serverless-Plattformen wie Azure Functions oder AWS Lambda ist das im Web schon lange realisiert.Warum also nicht dieses Denkmodell auf alle Anwendungen übertragen? Für mich ist es der Default; so beginne ich jedes Softwareprojekt: Ich suche nach den Backend-Facetten und versuche, sie so weit wie möglich zu separieren.Der Trennung von Frontend und Backend widerspricht die Vermutung, dass es Performance-Probleme geben könnte.Der Trennung von Backend-Facetten widerspricht die Vermutung, dass sie Zustand teilen könnten, was über Facetten-Prozesse hinweg umständlicher und auch wieder imperformanter wäre.Auch hier wende ich aber ein: Das sind Vermutungen. Vielleicht ist es so, vielleicht auch nicht. Warum für Vermutungen vorzeitige, unbegründete Optimierungen vornehmen?Backend-Facetten im selben Prozess hosten, Backend und Frontend im selben Prozess hosten: Das sind für mich vorzeitige Optimierungen für Effizienz, die massiv Flexibilität kosten, weil sie die Entkopplung zwischen Aspekten und Facetten verringern. Deshalb wäre ich damit vorsichtig. Deshalb ist für mich das primäre Denkmodell ein Bündel aus Datenflüssen zwischen Frontend- und Backend-Services.Ausführlicher habe ich diese Sicht in zwei Blog-Artikeln beschrieben [3] [4]. Und die Grundlage, warum Datenflüsse und nicht Abhängigkeiten das architektonische Denken beherrschen sollten, wird in [5] entwickelt.
Funktionalität im Datenfluss
Die Funktionalität einer Software wird durch den Functional Core implementiert. Der ist in mehrere Facetten getrennt, die durch unterschiedliche Trigger angestoßen werden. Die Aspekte des Frontends sind dem Functional Core nicht bekannt; er muss nur bereit sein, Input auf Aufforderung anzunehmen, zu verarbeiten und seinen Output in bestimmter Weise an die Umwelt abzugeben. Woher der Input kommt, wohin der Output geht, das ist den Funktionalitätsfacetten einerlei. Diese radikal objektorientierte Sicht leite ich ausführlich in dem Buch „Softwareentwurf mit Flow-Design“ [6] her.So sieht der Zusammenhang aus, in dem der Functional Core arbeitet. Doch wie sind seine Facetten intern strukturiert? Meine Antwort: It’s data flows all the way down.Dass eine Facette des Backends nur aus einem Prozessschritt besteht, ist nicht zu erwarten. Das bedeutet: Was in Bild 10 noch wie schwarze Monolithen aussieht, ist in Wirklichkeit eine Perlenkette vieler Schritte. In Bild 11 sei das lediglich vereinfacht als eindimensionaler Datenfluss dargestellt; tatsächlich und realistisch haben diese Datenflüsse jedoch drei Dimensionen [6].Ob diese Datenflüsse im selben Programm implementiert sind oder in verschiedenen, ist für diese grundsätzliche Sichtweise unerheblich. Das ist eine Frage der Gewichtung von Flexibilität gegenüber Effizienz.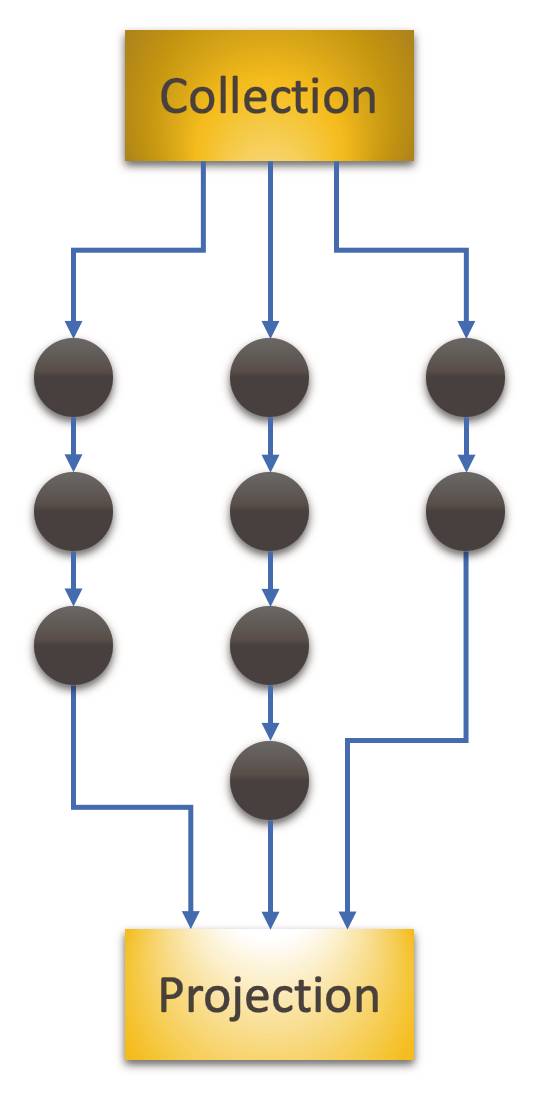
Die Backend-Facettensind selbst Datenflüsse(Bild 11)
Autor
Als Beispiel mag ein Softwaresystem dienen, mit dem man Newsletter erstellen und versenden kann. Welche Funktionalität ist nötig?
- Newsletter-Abonnements müssen eingetragen werden können.
- Jeder neue Abonnent bekommt eine Begrüßungs-E-Mail.
- Ein Newsletter soll zunächst als Entwurf erarbeitet und schließlich veröffentlicht werden.
- Veröffentlichung bedeutet, der Newsletter wird an alle Abonnenten verschickt.
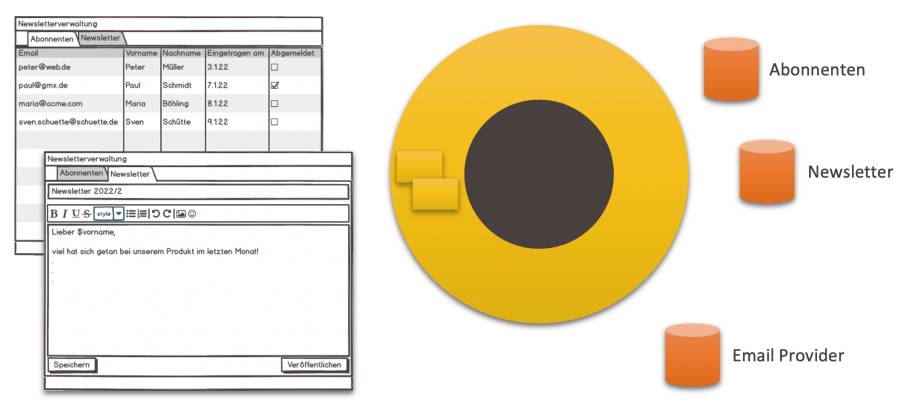
Softwaresystemmit GUI und Ressourcen(Bild 12)
Autor
- Die Abonnenten brauchen einen Speicherort, der über ein Persistenz-API anzusprechen ist.
- Der Newsletter braucht einen Speicherort, bis er verschickt wird, der über ein Persistenz-API anzusprechen ist.
- Der Newsletter wird per E-Mail verschickt; dafür braucht es ein Email-API.

Datenflussfür die Registrierung eines neuen Abonnenten(Bild 13)
Autor
Bei der Veröffentlichung ist der Prozess etwas umfänglicher – siehe hierzu Bild 14:
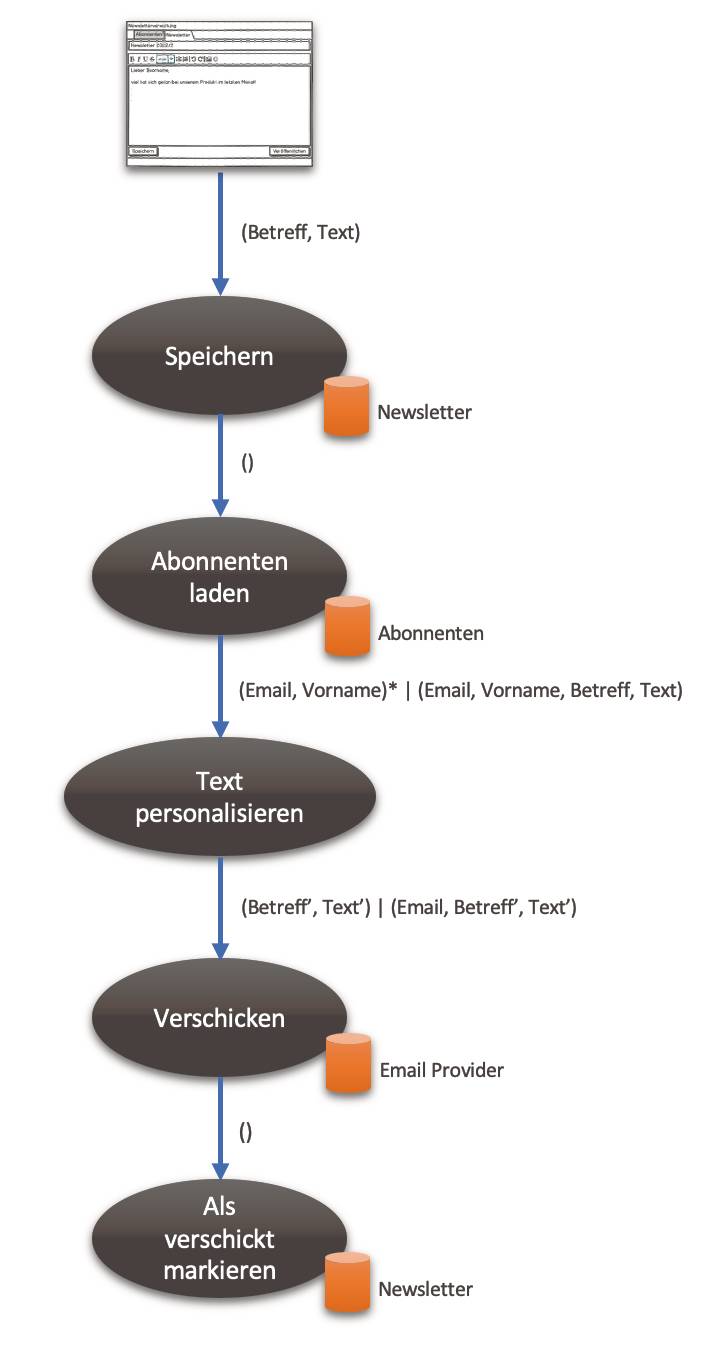
Datenflussfür den Newsletter-Versand(Bild 14)
Autor
1. Der Newsletter-Text wird gespeichert.2. Die Abonnenten werden geladen.3. Der Newsletter-Text wird für jeden Abonnenten personalisiert.4. Der personalisierte Text wird per E-Mail verschickt.5. Der Newsletter-Text wird als versandt markiert.Diese Datenflüsse lassen sich geradlinig in einer Desktop-Software implementieren. Oder ein REST-Backend hostet sie. Die Realisierung der Funktionalität sieht in beiden Fällen gleich aus. Was sich unterscheidet, ist die Verbindung mit dem Frontend. Bild 15 skizziert, wie das für den Newsletter-Versand aussehen könnte. Eine detailliertere Modularisierung lasse ich aus; sie trägt nichts zur Überführung der Implementation nach Make bei.

Skizze der Implementationdes Datenflusses für den Newsletter-Versand(Bild 15)
Autor
Die Implementation eines Datenflussentwurfs kann denkbar simpel sein. Wie das Listing in Bild 15 zeigt, ist jeder Schritt im Prozess lediglich in einen Funktionsaufruf übersetzt worden. Die Schleife implementiert das, wo in Bild 14 fließende Daten ominös mit einem Sternchen gekennzeichnet sind; dieses steht für einen Stream, der eine Menge von Datenelementen einzeln zum verarbeitenden Prozessschritt downstream fließen lässt. Näheres dazu finden Sie in [6].So natürlich und geradlinig die Umsetzung aussehen mag, eines ist hervorzuheben: Die Aufgabe der Funktion NewsletterVeröffentlichen() ist es, die anderen Funktionen zu integrieren. Sie verdrahtet die einzelnen Funktionsbausteine zu einem Ganzen, zum Prozess. Sie stellt den Datenfluss zwischen ihnen her.Integration ist eine ganz eigene Verantwortlichkeit (Integration Operation Segregation Principle (IOSP)). Insbesondere eine Funktion sollte entweder darauf konzentriert sein oder Funktionalität mit Logik implementieren.
Datenflüsse in der Cloud mit Make
Bei Make [7] [8] gilt nomen est omen: Make ist ein Service, der ganz auf Integration von Funktionseinheiten zu Prozessen in Form von Datenflüssen konzentriert ist. Bild 16 zeigt ein Beispiel der Selbstdarstellung von Make.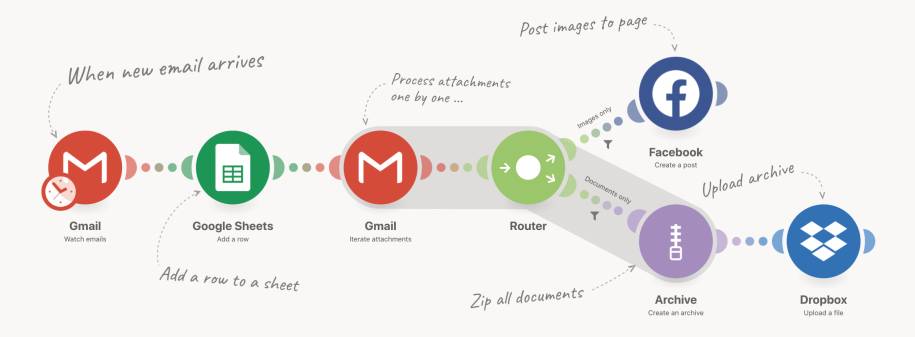
Beispiel für einen mit Makeimplementierten Datenfluss(Bild 16)
Autor
Die Funktionseinheiten, die integriert werden, sind vor allem Dienste im Internet. Derzeit bietet Make knapp 900 Apps, das heißt Internetdienste, deren API in mundgerechter Weise gekapselt wurde. Dazu kommen Services, die zwischen App-Prozessschritte geschaltet werden können, um deren Daten innerhalb von Make zu verarbeiten, zum Beispiel Router oder RegEx-Filter.Was mich von Anfang an begeistert hat, ist die Nähe der Make-Notation zur Flow-Design-Datenflussnotation (Bild 17): Oben ein Beispiel aus der Make-Dokumentation, unten ein nachträglicher Entwurf dazu.
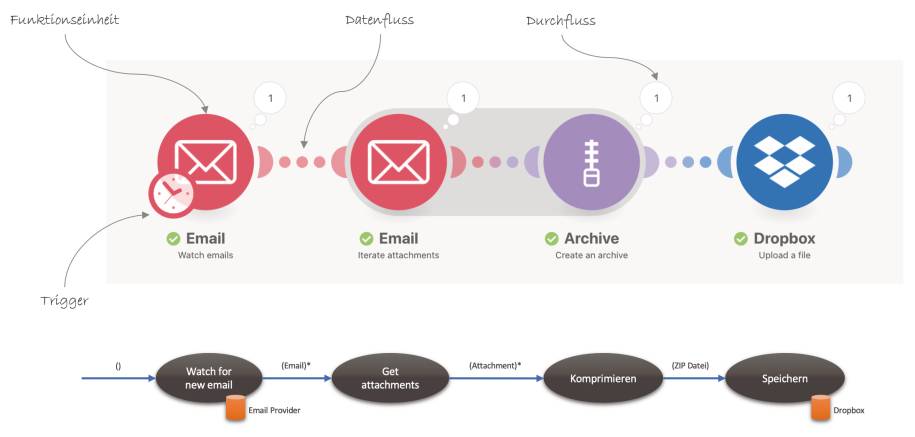
Ein Datenfluss-Entwurflässt sich fast eins zu eins nach Make übertragen(Bild 17)
Autor
- Funktionseinheiten sind Kreise und stehen für einen spezifischen API-Aufruf von App beziehungsweise Service.
- Daten fließen von links nach rechts entlang von (gepunkteten) Linien. Welche Daten in einer Ausführung geflossen sind, zeigt der Durchfluss-Zähler in Anzahl und Inhalt – siehe Bild 18.
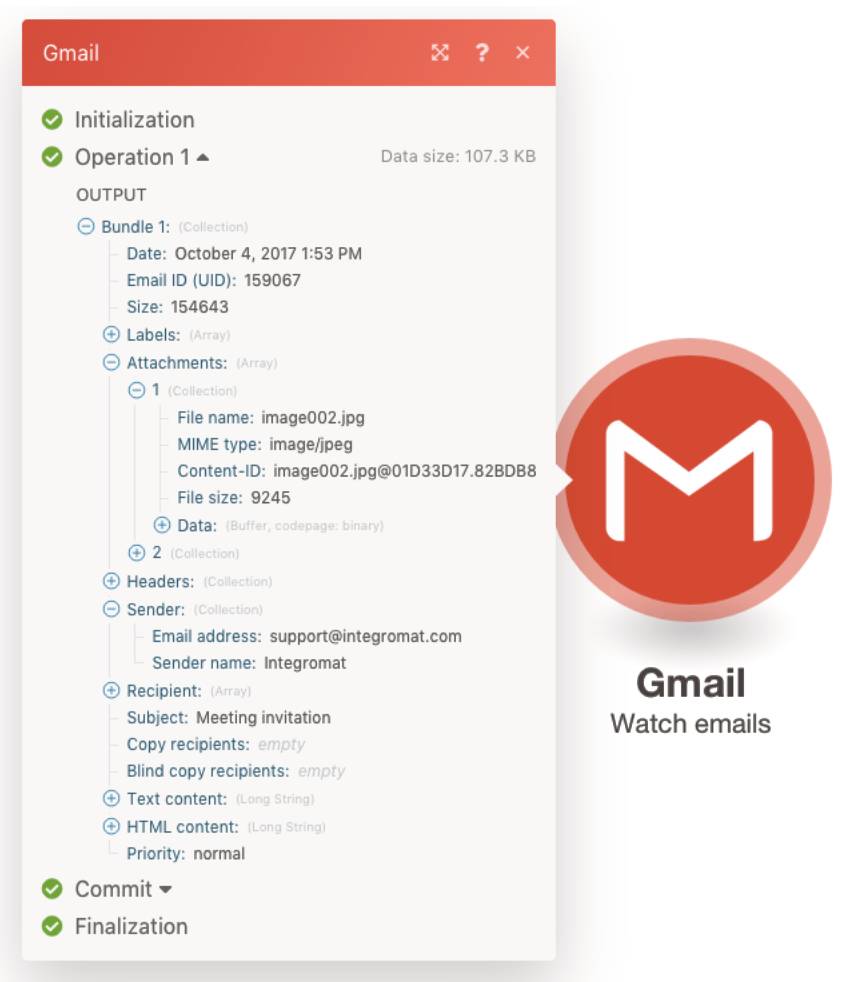
Welche Daten in welcher Strukturzwischen den Funktionseinheiten fließen, kann für jede Funktionseinheit nach deren Ausführung eingesehen werden(Bild 18)
Autor
- Da es kein Frontend gibt, das die Prozessausführung anstoßen könnte, stehen verschiedene Trigger zur Verfügung, zum Beispiel periodische Ausführung oder Reaktion auf Veränderung innerhalb der Datenquelle einer App.
Newsletter versenden mit Make
Mit Make dreht sich das Denken oft um 180 Grad, finde ich. Ich denke nicht mehr vom Frontend aus in die Implementation hinein, sondern von den existierenden Apps zum Frontend hin.Wenn ein Szenario in der Cloud implementiert werden kann, frage ich mich:- Welche Ressourcen sind beteiligt?
- Wie kann der Prozess getriggert werden?
- Was braucht es an Glue Code dazwischen?
- Mit Google Forms kann ich Interessenten auf einer Landing Page oder per Link in einer E-Mail anbieten, sich direkt in den Newsletter-Verteiler einzutragen. Google Forms erlaubt es, eingereichte Formularinhalte gleich an eine verbundene Tabelle anzuhängen.
- Mit Google Sheets kann ich im Backoffice die Abonnenten bequem in der verbundenen Tabelle verwalten.
- Für Endkunden ist das kein passendes Frontend, für Mitarbeiter kann es aber ausreichen, insbesondere in einer frühen Phase des Softwareprojekts.
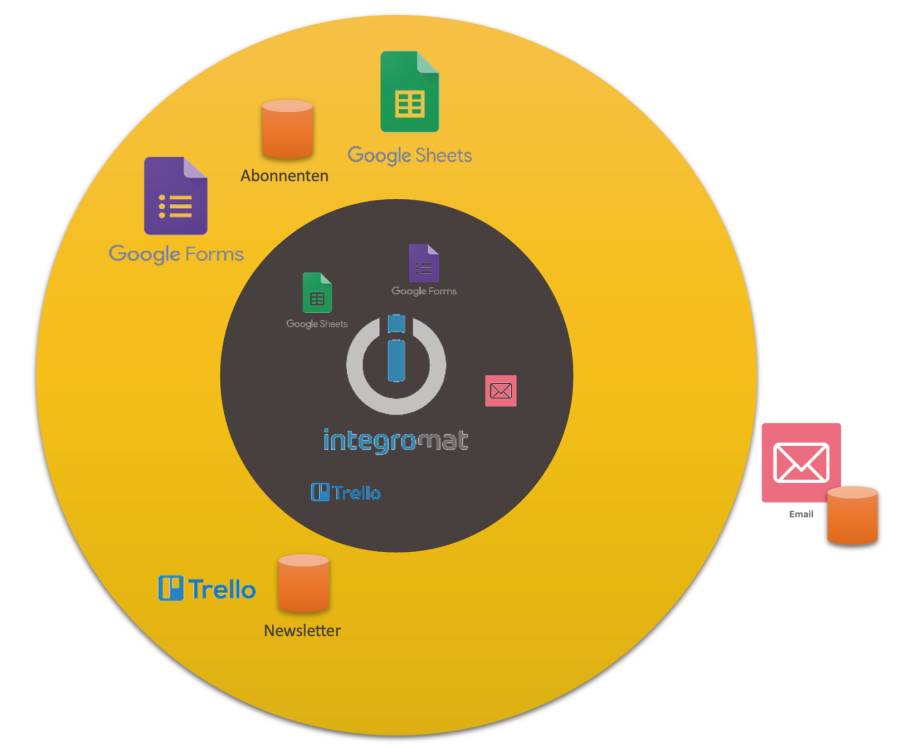
Das Frontend des Softwaresystemssetzt sich aus den Benutzerschnittstellen existierender Services zusammen(Bild 19)
Autor
- Benutzerschnittstellen müssen nicht implementiert werden. Was für eine Erleichterung!
- Das Backend besteht vor allem aus Integration in Make, wo APIs zu einem Prozess zusammengezogen werden.
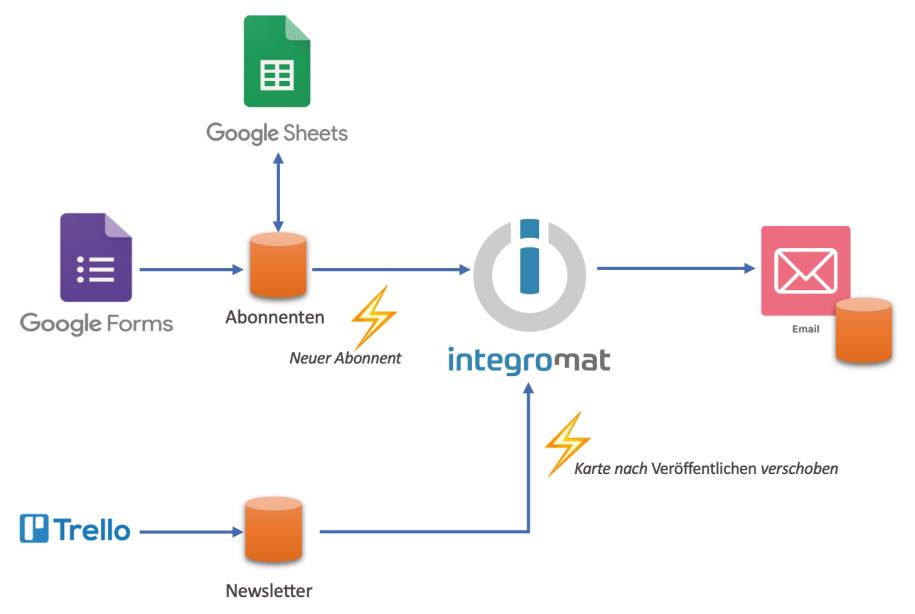
Die Ressourcen der integriertenServicesdienen auch der Kommunikation zwischen Make-Backend undFrontends(Bild 20)
Autor
Wenn in sie Daten eingeschrieben werden, triggert das die Verarbeitung im Backend.Der Abonnent benutzt ein Google-Formular, um sich in den Newsletter-Verteiler einzutragen (Bild 21); der Verteiler ist ein Google Sheet, das in der Tabellenkalkulation auch im Backoffice verändert werden kann.
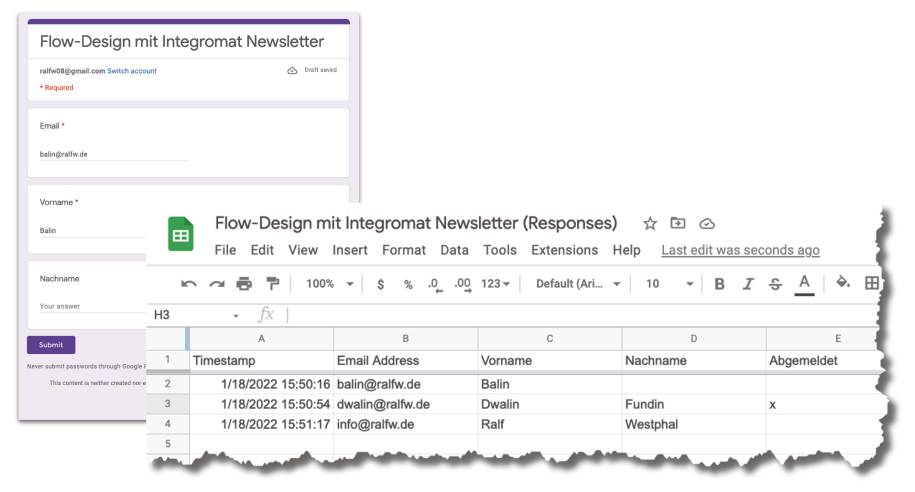
Der Newsletterwird über ein Google-Formular abonniert(Bild 21)
Autor
Die Newsletter-Redaktion findet innerhalb des Trello Boards statt (Bild 22); die Veröffentlichung ist dort nur ein Schubs einer Karte in die Spalte Veröffentlichen. Das Backend verschiebt den Newsletter nach dem Versand an den Verteiler automatisch in die letzte Spalte.
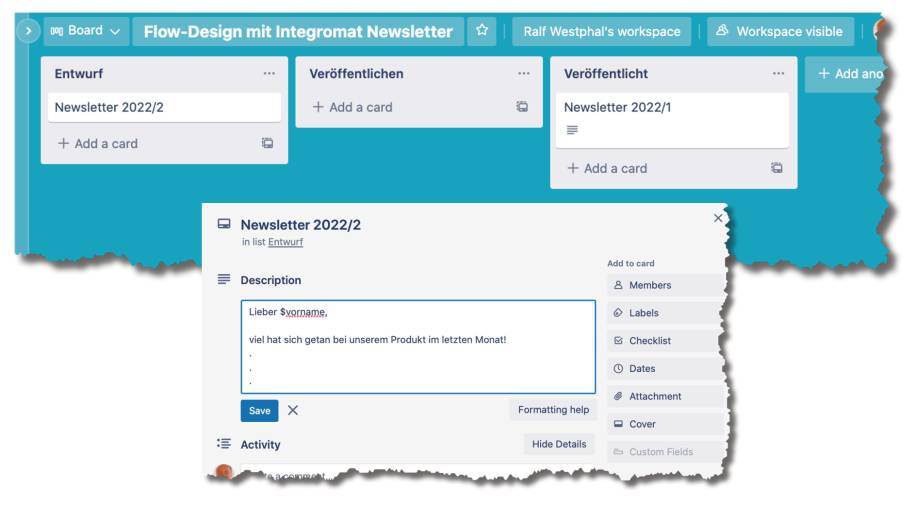
Ein simplerNewsletter-Redaktionsprozess in Trello(Bild 22)
Autor
Für Registrierung und Verwaltung der Newsletter muss nichts in Make getan werden. Dort sind lediglich zwei Prozesse – sogenannte Scenarios – für die Begrüßung und den Newsletter-Versand aufzusetzen. Bild 23 zeigt exemplarisch anhand des Begrüßungsprozesses, wie das geht: Das Make-Scenario soll jedem neuen Newsletter-Abonnenten eine personalisierte Willkommens-E-Mail schicken.
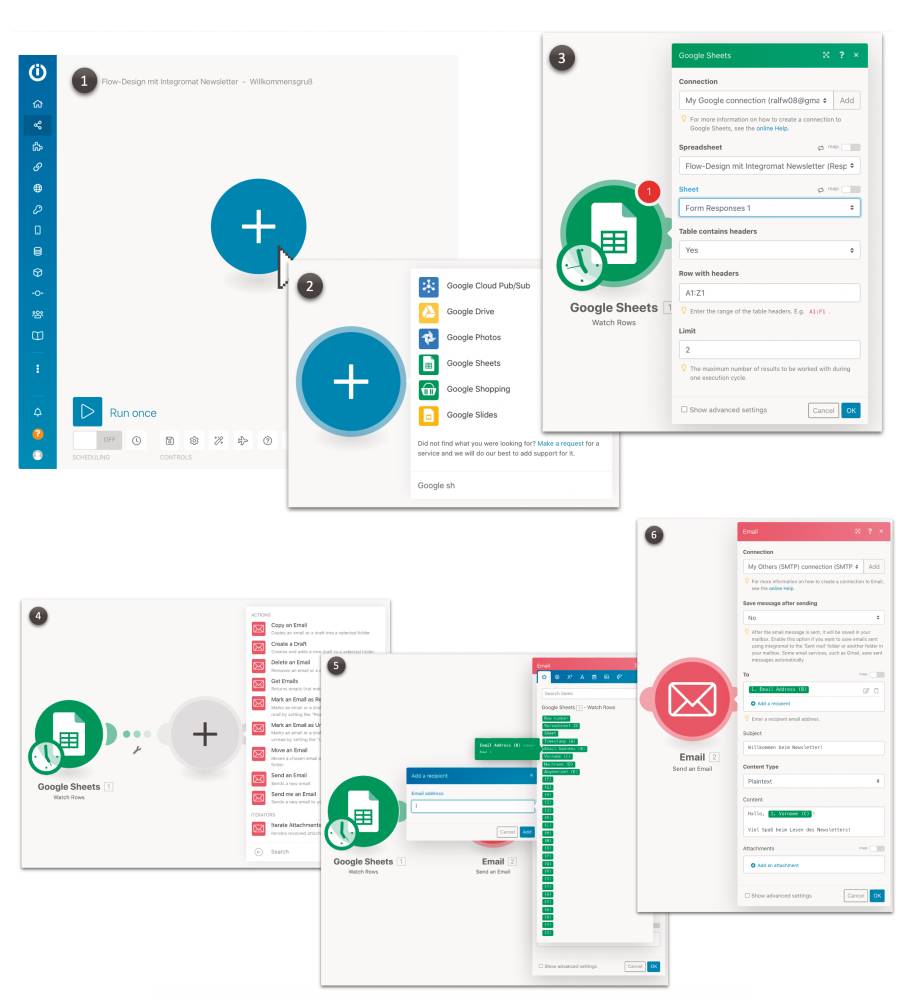
Schrittweise einen Prozessin Make implementieren (Bild 23)
Autor
1.Ein Make-Scenario besteht zunächst nur aus einem Platzhalter für den ersten Prozessschritt.2. Jeder Prozessschritt wird aus der Liste der Apps und Services ausgewählt.3. Apps werden mit einem Konto für ihren Service und darin mit individuellen Ressourcen verbunden. Hier: Ich verbinde Make mit meinem Google-Konto und wähle darin das Google Sheet aus, in das die Google Form aus Bild 21 Newsletter-Anmeldungen schreibt. Außerdem wähle ich als Funktion für diesen Prozessschritt die Ermittlung neuer Einträge in das Google Sheet.4. Die neuen Tabellenzeilen fließen zum zweiten Schritt, für den ich den Versand einer E-Mail wähle. Dafür binde ich den Schritt an mein
E-Mail-Konto.5. Nach jedem Prozessschritt stehen im Datenfluss alle Daten zur Verfügung, die bis dahin über Apps hineingezogen wurden. Das ist hier zwar nur eine Tabellenzeile, doch aus der kann ich
für den Adressaten der E-Mail die Spalte mit der E-Mail-Adresse wählen.6. Den Begrüßungstext trage ich fest in den Prozessschritt ein; der Vorname des Adressaten wird über einen Platzhalter eingespielt, der ebenfalls aus der Tabellenzeile des vorherigen Schrittes stammt.Die Übersetzung des Datenflusses aus Bild 13 erfolgt mit Make quasi mechanisch. Da Google Forms die Speicherung schon vornimmt, reduziert sich die Registrierung auf die Feststellung, ob es neue Anmeldungen gegeben hat. Deren Daten werden geladen und in den Prozess geschoben.Auch wenn der initiale Prozessschritt Watch Rows heißt, beobachtet das Scenario das Google Sheet nicht kontinuierlich und wird auch nicht von Google getriggert. Vielmehr wähle ich ein Polling-Intervall von fünf Minuten: Alle fünf Minuten startet Make das Scenario und der erste Schritt prüft, ob er neue Zeilen in der Tabelle erkennt. Die lädt er und schiebt sie einzeln in den Datenfluss. Wie viele neue Zeilen je Aufruf verarbeitet werden sollen, lässt sich festlegen.Um das Scenario zu testen, kann ich es manuell anstoßen. Ansonsten läuft es nach Einstellung des Polling-Intervalls periodisch automatisch. Neue Abonnenten bekommen also im Mittel nach 2,5 Minuten ihre Begrüßungs-E-Mail. Das scheint mir akzeptabel. Welche Daten bei einem Scenario-Lauf geflossen sind, kann ich an den Prozessschritten einsehen: Der Klick auf die Durchflussangabe öffnet ein Inspektorfenster, das für jedes geflossene/verarbeitete Datenelement Struktur und Inhalt zeigt.Zeitaufwand bis hierher:
E-Mail-Konto.5. Nach jedem Prozessschritt stehen im Datenfluss alle Daten zur Verfügung, die bis dahin über Apps hineingezogen wurden. Das ist hier zwar nur eine Tabellenzeile, doch aus der kann ich
für den Adressaten der E-Mail die Spalte mit der E-Mail-Adresse wählen.6. Den Begrüßungstext trage ich fest in den Prozessschritt ein; der Vorname des Adressaten wird über einen Platzhalter eingespielt, der ebenfalls aus der Tabellenzeile des vorherigen Schrittes stammt.Die Übersetzung des Datenflusses aus Bild 13 erfolgt mit Make quasi mechanisch. Da Google Forms die Speicherung schon vornimmt, reduziert sich die Registrierung auf die Feststellung, ob es neue Anmeldungen gegeben hat. Deren Daten werden geladen und in den Prozess geschoben.Auch wenn der initiale Prozessschritt Watch Rows heißt, beobachtet das Scenario das Google Sheet nicht kontinuierlich und wird auch nicht von Google getriggert. Vielmehr wähle ich ein Polling-Intervall von fünf Minuten: Alle fünf Minuten startet Make das Scenario und der erste Schritt prüft, ob er neue Zeilen in der Tabelle erkennt. Die lädt er und schiebt sie einzeln in den Datenfluss. Wie viele neue Zeilen je Aufruf verarbeitet werden sollen, lässt sich festlegen.Um das Scenario zu testen, kann ich es manuell anstoßen. Ansonsten läuft es nach Einstellung des Polling-Intervalls periodisch automatisch. Neue Abonnenten bekommen also im Mittel nach 2,5 Minuten ihre Begrüßungs-E-Mail. Das scheint mir akzeptabel. Welche Daten bei einem Scenario-Lauf geflossen sind, kann ich an den Prozessschritten einsehen: Der Klick auf die Durchflussangabe öffnet ein Inspektorfenster, das für jedes geflossene/verarbeitete Datenelement Struktur und Inhalt zeigt.Zeitaufwand bis hierher:
- Einrichtung der Google Form samt Tabelle: fünf Minuten.
- Aufsetzen des Scenarios: fünf Minuten.

Der Prozessfür den Newsletter-Versand(Bild 24)
Autor
- Die Beobachtung des Trello Boards stellt nur fest, dass eine Karte in der Spalte Veröffentlichen angekommen ist. Dadurch ist diese Karte jedoch noch nicht im Datenfluss; sie muss anschließend in einem zweiten Schritt explizit geladen werden.
- Laut Entwurf in Bild 14 sollte die Markierung des Newsletters als versandt erst ganz am Schluss stattfinden. Das ist in der Make-Implementation nicht praktikabel, weil das bedeuten würde, dass der Schritt nach dem E-Mail-Versand liegt. Der
E-Mail-Versand jedoch wird für jeden Abonnenten durchlaufen; dasselbe würde mit der Markierung passieren. Deshalb verschiebt schon der dritte Prozessschritt den Newsletter in die Spalte Veröffentlicht, bevor der eigentliche Versand stattfindet. - Aus dem Google Sheet der Abonnenten werden alle Einträge geladen – allerdings werden nur die weitergeleitet, die nicht als abgemeldet gekennzeichnet sind. Das wird durch einen Filter erreicht (Bild 25). Alternativ ließe sich ein solcher Filter auch am Datenfluss in Make anbringen, doch ich nehme an, dass der Filter im Prozessschritt von der App unterstützt wird und die Menge der Daten, die von Google zu Make fließen, begrenzt.
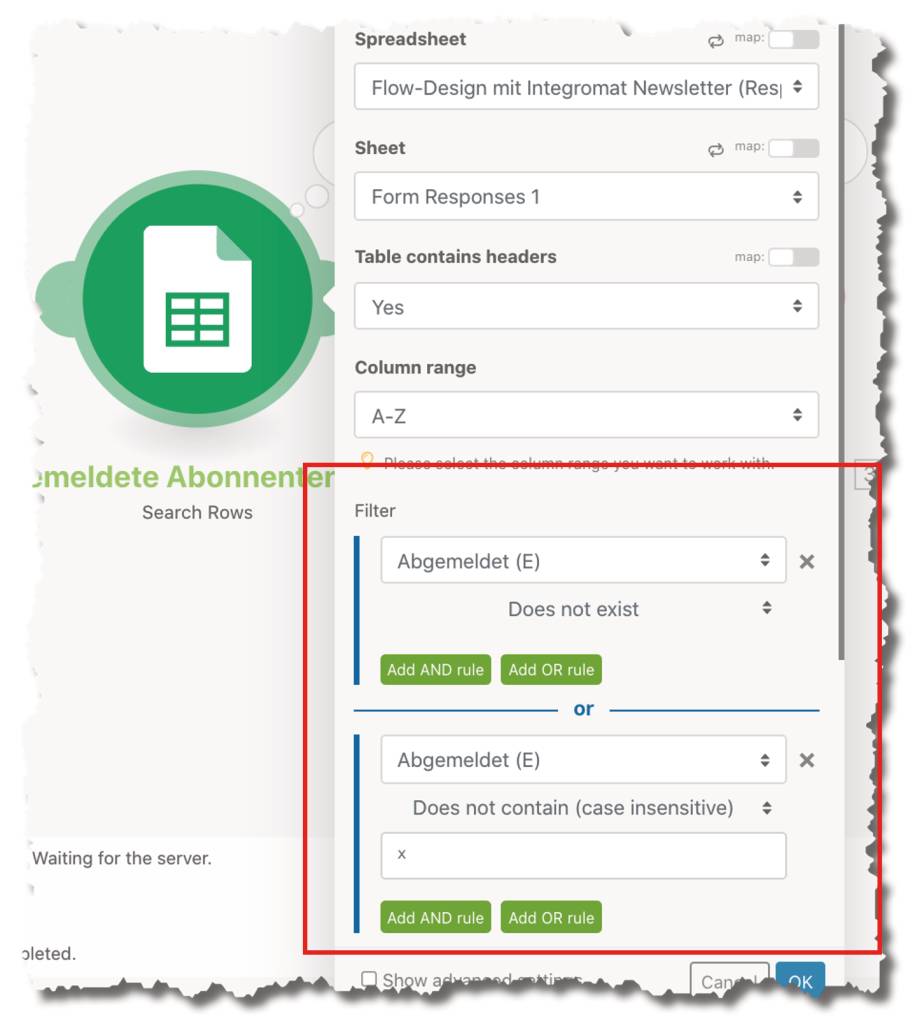
Welche Zeilender Google-Sheet-Tabelle downstream fließen, kann mit einem Filter eingeschränkt werden(Bild 25)
Autor
- Der E-Mail-Versand funktioniert wie beim vorherigen Prozess. Allerdings kann hier der Text nicht im Prozessschritt parametrisiert werden, weil er dynamisch aus der Newsletter-Karte geladen wird. Also ist eine Ersetzung des Platzhalters nötig (Bild 26). Dafür bietet Make Funktionen, die innerhalb von Feldern aufgerufen werden können. Die Notation dafür ist etwas gewöhnungsbedürftig und der Editor ein wenig umständlich, doch letztlich funktioniert diese Programmierung wie gewohnt.
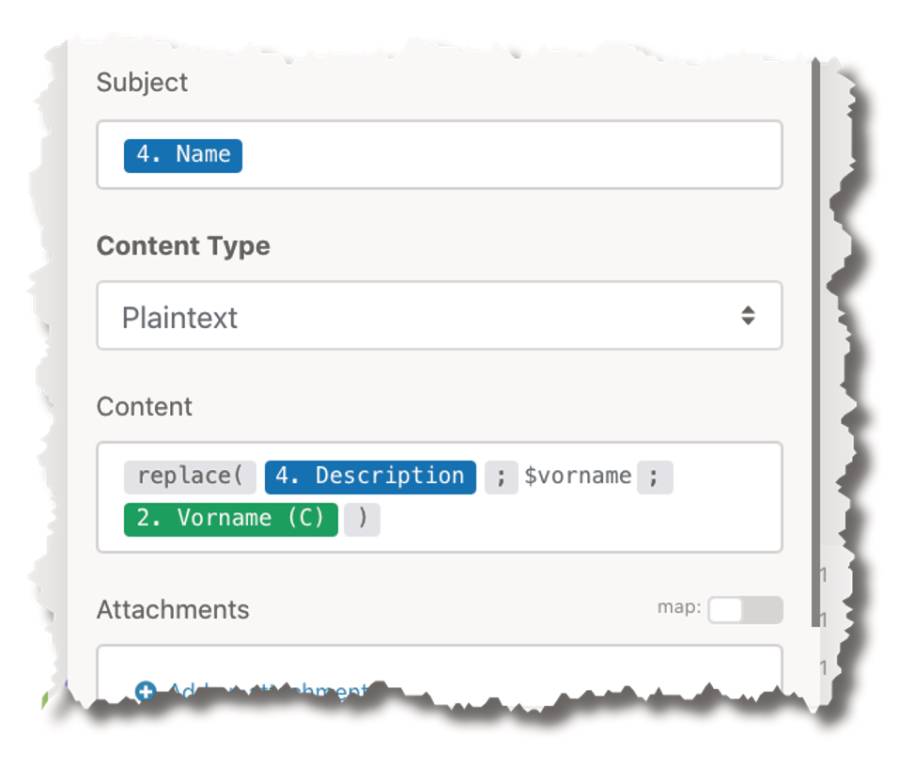
Ersetzen desPlatzhaltersfür den Vornamen im Newsletter-Text durch eine Funktion von Make(Bild 26)
Autor
Auch für dieses Scenario stelle ich ein Polling-Intervall von fünf Minuten ein. Alternativ könnte ich entscheiden, dass nur jeden Morgen um 7 Uhr geprüft werden soll, ob ein Newsletter zum Versand ansteht. Zeitaufwand für dieses Scenario:
- Verteiler: null Minuten.
- Newsletter-Verwaltung mit Trello: fünf Minuten.
- Aufsetzen des Scenarios: 20 Minuten. Eigentlich sollte es nicht so lange dauern, doch ich war nicht ganz vertraut mit der Trello-App und bin über das Filtern in der Google-Sheet-App gestolpert.
Fazit
Insgesamt hat also die Implementation des Softwaresystems für den Newsletter-Versand weniger als 45 Minuten gekostet. Ich finde, das ist vernachlässigbar im Vergleich zu einer eigenen Implementation mit C# und vielleicht Azure.Als Vorteile sehe ich:- Kein Implementationsaufwand für Frontends.
- Kein Hosting-Aufwand für die Persistenz.
- Kein Hosting-Aufwand für Services.
- Getestete und skalierbare Services können „out of the box“ genutzt werden, statt sie selbst entwickeln zu müssen.
- Der Aufruf von eigenen REST-Services ist möglich. Wo in der Liste der Apps und Services etwas fehlt, kann die Lücke selbst geschlossen werden.
- Mit sogenannten Routern lassen sich auch mehrarmige Prozesse realisieren, die alternativ oder parallel arbeiten.
- Scenarios können auch direkt durch HTTP-Aufrufe/Webhooks getriggert werden.
- Make bietet Variablen, die in einem Prozess gesetzt und ausgelesen werden können.
- Scenarios können in eine Make-eigene Datenbank schreiben und daraus lesen; nicht alles muss also in der Cloud mittels App persistiert werden.
- Bei Fehlern können Exception-Flüsse angestoßen werden.
- Die Refaktorisierung von Scenarios wird nicht gut unterstützt. Man kann sie umbauen, man kann das eine vom anderen aufrufen, doch das finde ich umständlich. Es wäre zumindest wünschenswert, innerhalb eines Scenarios mehrere Prozessschritte zusammenfassen und wegklappen zu können.
- Mit Routern lassen sich Datenflüsse in mehrere Arme (fork) auffächern – leider gibt es keine ähnlich einfache Weise, um mehrere Flüsse zusammenzufassen (join). Es ist nicht unmöglich, doch es bedeutet Handarbeit.
- Das Testen von Scenarios wird leider nicht wirklich unterstützt. Es wäre schön, wenn man für Scenarios unterschiedliche Umgebungen einstellen könnte, in denen etwa Variableninhalte und Verbindungseinstellungen hinterlegt sind.
Fussnoten
- .NET MAUI,
- Kenneth Lange, The Functional Core, Imperative Shell Pattern,
- Ralf Westphal, Sleepy Hollow Architecture – No application should be without it,
- Ralf Westphal, Terminus Architecture, https://ralfw.de/terminus-architecture/
- Ralf Westphal, Die IODA-Architektur im Vergleich,
- Ralf Westphal, Softwareentwurf mit Flow-Design,
- Integromat, https://www.make.com/en/integromat-shutdown?fromImt=1&
- Make, https://www.make.com/en









